DevOps lijst van concepten
Onderstaande tabel bevat een lijst van woorden, of — beter — concepten (want een concept bestaat soms uit meerdere woorden). De tabel bestaat nu vooral uit een toelichting op de checkpunten uit het CDDM beoordelingsmodel. Voor het beantwoorden van vaker terugkomende vragen zoals:
Wat wordt er bedoelt met het punt BD-203 - Build Once deploy anywhere?
Hoe dan ook, van deze termen moet je de betekenis kennen als je de minor hebt gevolgd. Alleen de uitleg in de tabel lezen is niet altijd voldoende voor goed begrip. Je moet ook de context uit de les erover kennen. Maar het kan wel een begin zijn, of manier om snel iets terug te zoeken.
Toelichting
In de DevOps minor leer je DevOps tools en DevOps concepten. Nu zijn tools meestal tijdelijk, zeker in een snel ontwikkelend vakgebied als DevOps. Maar (basis) concepten hebben een veel langere houdbaarheid, goede concepten zelfs oneindig...
Figuur 1 toont ludiek wat termen uit het wild, waar je ook veel buzzwords tegenkomt. Als DevOps professional moet je onderscheid kunnen maken tussen waardevolle concepten, en buzzwords.

In ieder geval is het doel wel dat deze termen ook aansluiten bij de beroepspraktijk en bestaande DevOps terminologie. De meeste woorden zijn dan ook Engels.
Hoewel de meeste feitelijk ook Nederlands zijn, of feitelijk deel uit maken van de internationale DevOps taal of jargon. Idealiter, als een concept een goede 'semantische' naam heeft, is ook voor ICT'ers de Van Dale soms een aardig begin. En zou je de originele betekenis/oorspring niet altijd terug moeten zoeken ('Death of the author' principe). Maar in de praktijk is vaak enkel de termn maar is dit niet toereikend heb je meer bronnen nodig om deze` goed te begrijpen (zie het voorbeeld uit figuur 3).

Figuur 2: Discussie thread op Twitter X over 'deployment' vs. 'release' (bron: Steve "ardalis" Smith 9-11-2023 op X)
Het plaatje in Figuur 2 toont een (vrij) recente discussie rondom checkpoints CO-302 uit het CDMM.
| Concept/begrip | Uitleg |
|---|---|
| DevOps | Cultuur van samenwerken |
| Green field vs. brown field | Nieuwbouw project vs bestaand project en/of nieuwe/nieuwste technologie vs legacy technologie. |
| TODO | ... |
| OA-001 Geconsolideerd platform & en technologie | Dit betekent dat je als organisatie een keuze hebt gemaakt qua technologie, meestal met erbij horende training, ervaring van huidige medewerkers. Bijvoorbeeld Java, of dotNet. Of Wordpress voor simpele corporate sites maar SiteCore voor complexere sites, en of multi-tenant opdrachten. Dit hoort bij lagere niveaus, omdat je bij microservices aanpak juist 'Polyglot X' kunt doen, zoals InfoSupport dat noemt, om programmeertaal of stack te laten varieren per microservice. Maar aanname is hierbij wel vaak weer een basis technologie als Kubernetes of Docker Swarm o.i.d die deze polyglot X mogelijk maken. Kortom: deze krijg je eigenlijk gratis bij gebruik PitStop, mits je gebruikte technologie maar documenteert. |
| BD-006 Enkele deployment scripts bestaan | Dit zijn wat handmatige deploy scripts die als basis kunnen dienen voor automatisering op de hogere levels (e.g. 'automate all the things'). |
| BD-101 Polling builds | Ik ga uit dat dit polling model is waarbij in plaats van dat je 'git distribution' (bv. GitHub met GitHub Actions) recht geeft te pushen naar de (runtime) omgeving via opslaan credentials o.i.d., er een tool is op een andere plek, buiten je Git systeem, (bv. ArgoCD), die periodiek checkt (bv. elke minuut) of er in je Git repo of ander versiebeheer een nieuwere versie staat en zo ja dan die code pakt, build en containerized en evt. test. Merk op dat het testen van de build onlosmakelijk verbonden is met Continuous Integration in de definitie van Martin Fowler’s hiervan: "Each of these integrations is verified by an automated build (including test) to detect integration errors as quickly as possible." |
| BD-203 Build Once Deploy Anywhere | Het Build Once Deploy Anywhere (BODA) principe houdt in dat je één keer een artefact bouwt. Zoals een .jar, .war, maar in de container age is dit natuurlijk een Docker-image (met daarin een .jar of andere applicatie), en ditzelfde artefact gebruikt voor alle omgevingen: van test en staging tot productie. Je koppelt een specifieke commit aan het artefact en automatiseert tagging en versiebeheer, zodat je elke build uniek kunt traceren.Je beheert configuraties buiten het artefact via omgevingsvariabelen, in lijn met het 12 Factor App-principe. Door configuraties niet hard mee te bouwen, voorkom je de noodzaak om omgevingsspecifieke artefacten te maken, zoals spotitube-prod.war of spotitube-staging.war. Met één geteste en goedgekeurde build kun je direct deployen naar productie, zonder opnieuw te bouwen. Je standaardiseert het deploymentproces over alle omgevingen. Dit proces omvat ook geautomatiseerde database-migraties en gescripte runtimeconfiguratie-aanpassingen. Door deze aanpak creëer je een uniforme delivery pipeline die alle stappen omvat: van source control tot productie. Dit minimaliseert fouten, verhoogt de betrouwbaarheid en versnelt het deploymentproces. Met tools zoals ArgoCD en andere CI/CD-oplossingen automatiseer je het combineren van configuraties met de artefacten en rol je deze efficiënt uit naar meerdere omgevingen. Dit is logisch voor verdere standaardisatie, maar is in Cloud tijdperk nog lang niet altijd standaard bij bedrijven (blog). |
| BD-204 Automatiseer meeste DB wijzigingen | Dit punt kun je bv. afvinken met het gebruik van de in de course fase (kort) behandelde Entity Framework (EF) Code first aanpak. Deze ondersteunt (automatische) data migraties (o.b.v. een 'single source of truth', namelijk de code). Maar alleen het gebruik van EF is voor dit punt echter niet voldoende. Je moet dan ook minstens één voorbeeld hebben van een daadwerkelijke en 'niet triviale' data migratie. Vaak hebben teams een standaard migratie voor het opzetten van de initiële database. E.g. een migratie van 'niets' naar iets. Of deze is evt. opgesplitst in een 'create' stuk en een 'insert' migratie, maar ook dat is nog triviaal (e.g. simpel). 'Niet triviaal' wil zeggen dat je de databasestructuur verandert door bijvoorbeeld een tekstveld om te zetten naar een foreign key naar een stamtabel (vaak hoort hier wijziging in de UI bij van een vrij tekstveld naar een dropdown, en/of back-end veld omzetten naar Enum i.p.v. String o.i.d.). Bij deze structuur wijziging moet je ook bestaande data migreren in je Up() én Down() methode. Of alles goed gaat moet je dan vervolgens testen, en typisch is handmatig schrijven van wat migratie code nodig. Voor afvinken moet je zo'n (voorbeeld van) een migratie ook kort toelichten in je CDMM of elders. Helemaal interessant maak je het als je een serie van wijzigingen hebt die je apart lokaal test, maar vervolgens op een test omgeving gecombineerde doorvoert (migreert) en test, liefst ook tegen kopie van productie, of gelijkwaardige set om te voorkomen dat je dit als eerste op productie doet en hierbij pas eventuele integratie problemen optreden. Let wel, dat dit is in een kleine project wel lastig te verwezenlijken. Dit vraagt ook een goede toepassing binnen het domein en afstemmen met de opdrachtgever. Als er voor de opdrachtgever geen winst in de nieuwe datastructuur zit, is de effort moeilijke te verkopen. Voor dit punt helpt het wel om heel vroegtijdig live gaan (in week 1 of 2) met een simpele datastructuur en ook bijbehorende test dataset. En hierop ook de opdrachtgever of andere testers laten werken om productie achtige gegevens in te voeren. Op deze test data kun je daarna je (niet triviale) migratie kunt doorvoeren. |
| BD-206 Gescripte config wijzigingen | Als je config wijzigigingen gescript hebt, kun je dit script testen op een test omgeving, en checken dat config wijzigingen doen wat je wilt, voordat je het op productie ook doet. Voorkomt fouten en zorgt voor herhaalbaarheud. Versnelt ook het proces, omdat je niet handmatig stap voor stap de config wijzigingen uit moet voeren, of op productie foutgevoelig met een editor config aanpast. |
| CO-201 Multidiscl. team (betrekken DBA, CM) | In plaats van een aparte developer team en operations team (die CM=Configuration Management) doen. En wellicht ook aparte DB admin of admins, plaats je iedereen in het team, zodat mensen vroegtijdig(er) overleggen (shift left), en wijzigingen niet tijdens deploy aan het eind vastlopen, omdat een probleem bovenkomt die iemand van andere discipline had kunnen zien aankomen. Denk bijvoorbeeld ook aan security mensen (e.g. van DevOps naar een DevSecOps team). |
| CO-202 Component eigenaarschap | Hoewel het hele team verantwoordelijk is voor alles, is het wel goed om een of enkele mensen eigenaar te maken van een component. Denk bij een component bijvoorbeeld aan een microservice. Dit sluit ook aan bij de 'Pizza rule' uit DevOps (NetFlix): het team verantwoordelijk voor 1 microservice moet (bij onderhoud) aan 1 pizza genoeg hebben. Dus 2 of 3 mensen? |
| CO-203 Handelen op metrics | Studenten vraag: > "[...] Hoe zouden wij dit moeten uitvoeren in dit project? We hebben niet echt gebruikers waarop we kunnen reageren." Antwoord: Als er geen echte gebruikers zijn, moet je deze faken. Sowieso is het een best practice om een test dataset aan te leggen in een database of andere data storage. Ook om je requirements duidelijk te krijgen, en gekozen abstracties te testen. Dit onder de noemer “Sometimes three good examples are more helpful to understand the requirements than a bad abstraction.”' - Peter Hruschka (domainstorytelling.com, 2023). |
| CO-206 Decentrale besluitvorming | Agile is naast cross-functional en collaberatief ook niet hiërarchisch (Wrike, z.d.). Er is dus NIET één baas, voorzitter of product owner die alles beslist. De product owner is weliswaar verantwoordelijk voor het houden van overzicht van het product en WAT erin komt. Maar HOE je dit realiseert besluiten de teamleden samen, en voor decentrale besluitvorming betekent dit dat een beslissing idealiter bij de persoon die de meeste relevante kennis heeft, qua domein en/of technisch (zie ook <a href="CO-202>CO-202 Component eigenaarschap). Een probleem kan ook om 3:00 's nachts optreden, en idealiter kan er op dat moment ook een beslissing genomen worden om het op te lossen, zonder 'de baas' uit bed te bellen om een beslissing te nemen over wel/niet release van een fix en evt. release. Wel houdt CO-206 in dat je ook samen een proces opzet, waarbij je met hele team later bv. een post mortem over zo'n issue houdt, en meer structurele fix inplant, na een nachtelijke work-around/bugfix, en bv. ook je (DevOps) proces optimaliseert om kans op een soortgelijke fout later te verkleinen. Terzijde: er is ook een interessante link tussen 'decentralized decision making' en het concept 'epistocracy' zoals beschreven door Jason Brannon in zijn 'scherpe' boek 'Against democracy' (2017, voor de duidelijkheid: geen ICT boek :P). |
| CO-301 Dedicated Tools team | Er is een apart team in het bedrijf dedicated gericht op DevOps tools inrichten, beheren en onderzoeken. Sinds circa 2022 kwam dit principe ook onder de noemer Platform Engineering naar voren (State of DevOps, 2023). Dit houdt in dat er één apart team verantwoordelijk is voor het 'platform' waarop de IT draait. Dit lijkt op een soort interne 'Platform as a Service (PAAS)', maar sommigen spreken liever van 'Platform as a Product' (taloflow.ai, 2024, teamtopologies.com, 2021). Of pessimistisch (of realistisch?) gezegd: Het team van 'DevOps tools experts' is zo druk met hun werkzaamheden, dat ze geen tijd meer hebben voor ontwikkelwerkzaamheden in regulier teams. NB: Merk op dat het woord 'apart' een beetje indruist tegen de 'DevOps cultuur' van 'break down silo's. En een 'specialistisch' team gaat ook tegen het multi-disciplinaire karakter van DevOps teams, waarbij ook juist een Polyglot X aanpak mogelijk is. Dus dat elke deelapplicatie/microservice een andere techniek heeft (the right tool for the right job). Ook bij polyglot X is echter het (container) platform meestel wel geconsolideeerd (dat wil zeggen er zijn regels over, zodat alle teams in het bedrijf dezelfde taal en frameworks gebruiken). Dit is bijvoorbeeld Kubernetes en de de DevOps aanpak geeft veel nieuwe andere tools en technologie die aansluiten bij DevOps zoals Git, Kubernetes, Ansible, Argo. Iedereen kent de basis, maar een expertise team op dit gebied levert voor grotere bedrijven wel winst op. |
| CO-304 Continuous improvement (Kaizen) | Creëer een cultuur van continue verbetering waarin alle medewerkers actief bijdragen aan verbetering; voed deze cultuur met events gericht op specifieke verbetergebieden (Vorne Industries, z.d.). |
| CO-303 - Deployment loskoppelen van release | Hoewel ICT'ers de termen 'release' en 'deployment' vaak als synoniemen gebruiken, geeft dit CDMM checkpoint aan dat een volwassen DevOps deze 2 van elkaar los kan koppelen. Een release is een set samenhangende wijzigingen, een product increment in Scrum termen. Het 'increment' samen met het product samen leidt tot een potentially shippable product. Een nieuwe versie van je applicatie. Het 'potentially' stelt eisen aan dat de nieuwe features (voldoende) bugvrij zijn, en samenhangend. Maar het laat dus vrij of je de nieuwe versie ('release') daadwerkelijk beschikbaar stelt voor naar eindgebruikers ('productie'). Dit is dan een 'business beslissing'. Het loskoppelen heeft twee varianten. Je kan er de nieuwe release alleen deployen op een (accceptatie test omgeving, en dan beslissen er op door te itereren door nieuwe inzichten die je krijgt. Je kunt ook via bv. een 'dark release' of 'feature toggle' de onderliggende code van de functionaliteit wel degelijk opleveren, maar deze nog niet activeren (feature toggle) of bereikbaar maken (dark release). Het 'loskoppelen' gaat erom dat je dit makkelijk in kunt stellen, zodat de twee concepten 'release' en 'deployment' duidelijk van elkaar gescheiden zijn. Zie figuur 1. |
| CO-402 Cross Silo analysis | Dit punt uit Information & Reporting is geavanceerd en vereist de nodige domeinkennis en overzicht van de organisatie. Dit punt is gelieerd aan Conway’s Law over de link tussen de structuur van de applicaties/microservices en de structuur van de organisatie die de applicaties gebruiken/laten bouwen. Basis eis is dat je meerdere microservices draait die Kan je systeem ook metrieken rapporteren waardoor je verbanden tussen verschillende organisatie onderdelen (silo's) kunt zien? Dat je organisatieonderdelen onderling kunt vergelijken op bepaalde aspecten? Zulke informatie geeft voor een bedrijf vaak optimalisatie mogelijkheden. Zoals InfoQ aangeeft: "Moving to expert level in this category typically includes improving the real time information service to provide dynamic self-service useful information and customized dashboards. As a result of this you can also start cross referencing and correlating reports and metrics across different organizational boundaries,. This information lets you broaden the perspective for continuous improvement and more easy verify expected business results from changes." |
| OA-001 Geconsolideerd platform & technologie | Een bedrijf kiest voor een enkele technologie, of combi van bij elkaar passende technologieen (e.g. stack) voor alle applicaties. Bv. Windows (platform) en GEEN macOS. Of programmeertaal/ontwikkelomgeving .NET. Dus een medewerker kan dan niet bij een nieuwe opdracht opeens Java kiezen, ook al is er wellicht een library in Java die al 50% van de requirements vervult, die er (nog) niet voor .NET is. En een developer kan ook niet een Elixir project kiezen voor opdracht waar dit past (maar hoge concurrency eisen bv. proberen te voldoen via gebruik RabbitMQ). Of "Geen MySQL, want "we hebben een SQL Server licentie, en 3 DB admins met MS DP-300 certificaat. Dit is erg pragmatisch en komt dus veel voor, want geeft standaardisatie, maar is tegelijkertijd wel de tegenhangen van de Polyglot X aanpak die DevOps in principe mogelijk maakt (merk op dat Polyglot X zeker niet verplicht is bij DevOps). |
| CO-402 No rollbacks (always roll forward) | Dit checkpunt vereist wat zelfstudie, want dit punt vraagt wat verdieping en kun je over discussieren. Lees bijvoorbeeld kritische beschouwing van Jim Bird over roll forward en andere DevOps best practices of misconcepties (Bird, 2011). Dit punt moet je discussieren en toelichten als je dit punt wilt afvinken in je CDMM, met liefst beschrijving van eigen concrete situatie in je software ontwikkeltraject waar je een roll forward deed, of juist automatische rollback kon doen, en hoe dan. |
| OA-102 API-gestuurde aanpak | De microservices praten met elkaar met (geconsolideerde) interface, bv, RESTful API's of service bus (of RabbitM!). Dit maakt PolyGlot X aanpak mogelijk, niet alle applicaties hoeven bv., meer in Java (voorloper aanpak voor innovatie is andere taal op zelfde Virtual Machine zoals JVM (met Java, Kotlin, Scala)) of .NET met C#, F# of VB.NET voor CLR. |
| OA-203 Configuration as Code (CaC) | De (software) configuratie van een applicatie staat OOK in versiebeheer, zodat je het verloop hiervan over de tijd kunt zien en terugvinden (ivm auditing ook: wie heeft op 28 oktober deze setting aangepast?). Evt. kan configuratie hierbij in aparte repository staan dan code in verband met security, waar andere mensen (dan developer) verantwoordelijk voor zijn (denk aan connection strings die anders toegang tot productie db zouden geven (niet confogm AVG/GDPR)). Denk bij configuratie aan welk OS, welke software/middleware, maar ook zaken als welke software instellingen zoals IP adressen van machines). Verder kun je naast configuratie van applicatie zelf, ook denken aan configuratie van bijvoorbeeld een deployment pipeline die je applicatie build uit de code en oplevert naar een (runtime) omgeving. CaC vraagt dus de 'scripted pipelines' van Jenkins 2.0, de oude 'via UI' manier in Jenkins 1.0 geldt niet als CaC (maar wellicht kun je via UI ingestelde settings wel exporteren en dan inchecken in VCS en daarna hiermee verder werken). Hier is verder veel online over te vinden. |
| OA-204 Feature hiding (feature toggle e.d.) | Functionaliteit kan gedeployed zijn maar nog niet zichtbaar of geactiveerd voor eindgebruikers. Met een feature toggle schakel je codepaden aan/uit of kies je varianten (A/B). Dit maakt het mogelijk om release los te koppelen van deploy en om veilig te experimenteren (bv. dark release). Voorbeeld van een eenvoudige toggle in Java/Spring staat in de les over Git workflows: feature toggles – Java voorbeeld. |
| OA-205 Modules omzetten naar componenten | De monoliet is al wel modulair opgezet, de bestaande modules hang je in eigen microservice, bv. met eigen Docker container, zodat je ze los van elkaar kunt gaan opleveren. Heeft als potentieel probleem wel 'testing pyramid of hell' 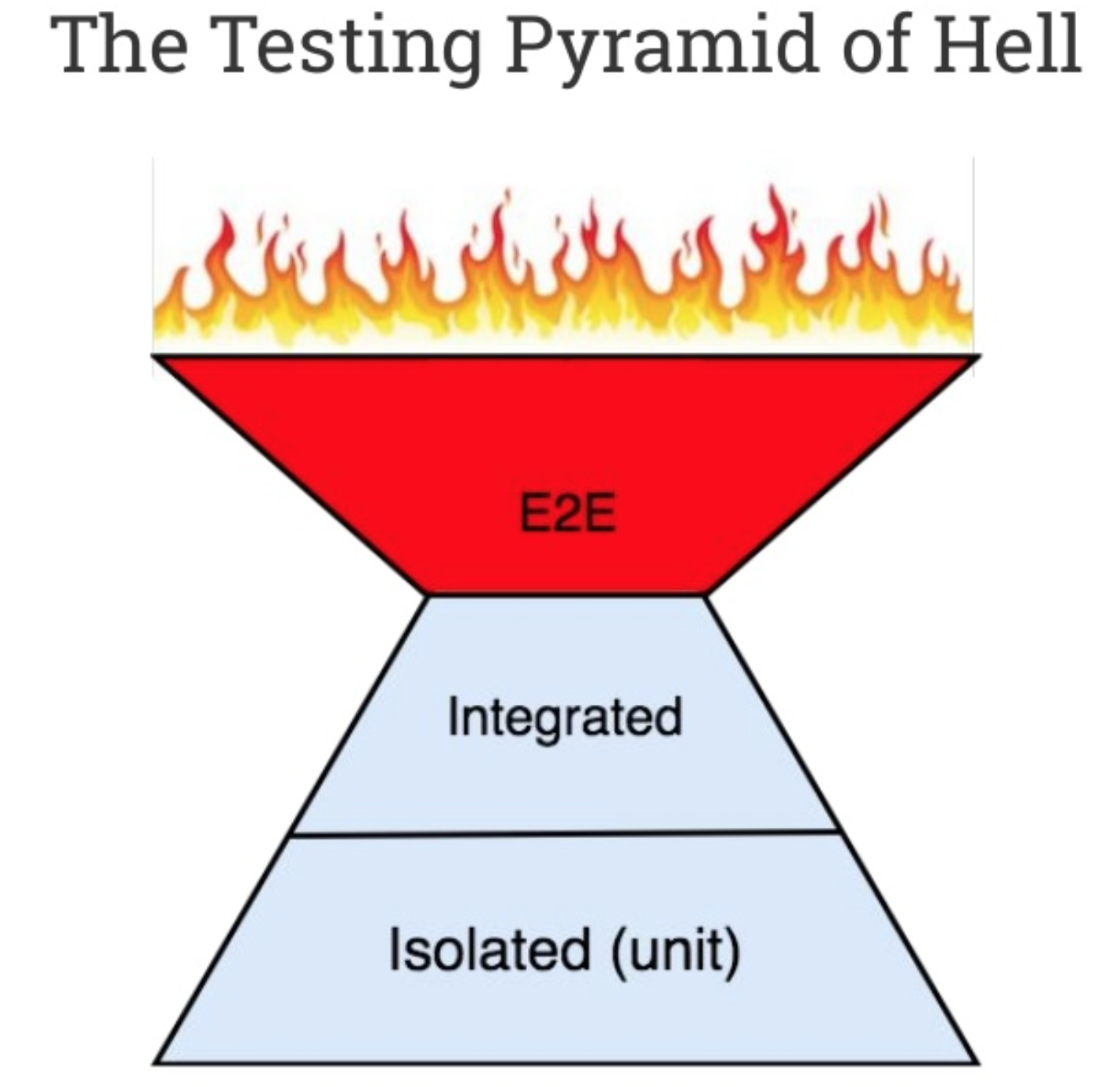 |
| OA-301 Volledige component gebaseerde architectuur | Next level van OA-205, met het 'strangle pattern' is een evt. oude monoliet (volgens 'monolithFirst' aanpak van Fowler) volledig omgezet in microserves |
| OA-302 Strict API based approach of message bus/broker | 'API‑first' (regelmatig gezien als een “13e principe” aanvullend op 12‑Factor) betekent dat je het contract vóór de implementatie ontwerpt en vastlegt (bijv. met OpenAPI voor sync HTTP of AsyncAPI voor events). Dit stimuleert loskoppeling, contract‑testing, documentatie en polyglot teams. Bij event‑driven integreer je via een broker (bijv. RabbitMQ/Kafka) met publish/subscribe i.p.v. point‑to‑point calls, wat back‑pressure en resiliency vergemakkelijkt. |
| OA-303 Graph business metrics uit applicatie | Naast de standaard metrieken die bv. Grafana kan geven van cpu, geheugen en bandbreedte gebruik heb je ook custom metrics gemaakt, die ook voor de business waarde hebben. En die frequent geupdate zijn, zodat business hierop ook kan sturen, en experimenten kan doen qua business logica in de markt en zien hoe deze uitpakken (bv. A/B testen). |
| BD-104 1e stap naar standaardisatie deploys | Meerdere teams gebruiken zelfde stappenplan voor deploy (bijvoorbeeld een geconsolideerde 'tech' keuze is SQL Server als database, en men switcht van .bak bestanden naar nieuwe BacPac) en/of gebruikt Azure Cloud voor alle producten. |
| BD-206 Gescripte config wijzigingen | De bij BD-203 genoemde config (bv. systeemvariablen) test je ook op een test omgeving VOORdat je op productie test door een script te maken die je kunt uitvoeren. Dit sluit aan bij het 12factor principe van one off Admin processes. Onder config wijzigingen kun je overigens naast omgevingsvariabelen ook andere config denken, zoals update van dependency bij security issue, maar bv, zelfs aanpassingen aan het database schema zien (SQL DDL scripts). In een ORM gebruik je hiervoor bv 'db migration scripts/code. |
| BD-401 Build bakery | Dit is een heel breed onderwerp, wat teruggaat naar de begintijd van Virtualisatie, met Amazon Machine images, maar wat feitelijk volwaasen is gemaakt door container registries en runtimes a la, waarbij je bv. een door veel applicatie hergebruikte base image hebt, met aparte config voor de specialisatie ervan (e.g. Dockerfile met CMD apk install tool-x). Vink dit punt NIET zomaar af als je Docker gebruikt, maar verdiep je in bron en argumenteer zelf waarom je hieraan voldoet. |
| BD-402 Zero touch continuous deployment | Geen handmatige inmenging meer nodig voor een deploy, een commit leidt automatisch tot nieuwe versie op productie, idealiter met gradual release maar dat valt hier niet bij, via de pipeline (mits linting, unit tests, automatische integratie tests etc. ). Merk op dat in projecten waar nog handmatige tests zijn dit niet altijd gewenst is, maar idealiter gebeurde dit plaats op test omgeving, en kun je via BODE principe (BD-203) risicoloos ermee naar productie via commit op main. |
| TV-201 Automatische component test (geisoleerd) | Geautomatiseerde integratie en/of UI test van een microservice, waarbij gebruikte dependent microservice gemockt zijn |
| IR-101 Meet het proces | InfoQ heeft bij het 'measure the process' stuk het voorbeeld van een aantal metrieken rondom het software ontwikkelproces zoals cycle-time of delivery time. Het proces meetbaar maken betekent dat je weet hoe lang een release duurt, dus het runnen van de pipeline. Of dat je weet hoeveel bugs er open staan op een component. En wat de gemiddelde fix tijd van een bug is. Of hoeveel bugfixes er in een release zitten. Het uberhaupt in kaart brengen is het begin van ook weten waar bottlenecks of probleemgebieden zijn in je software landschap. Waar zitten de moeilijke onderhoudbare 'big ball of mud' monolieten. Of welke modules leveren vaak bugs op. En voor de release van welke service moet je altijd een paar developers klaar hebben. Meet het proces gaat echter alleen over het inzichtelijk hebben van zulke informatie, en nog niet over het verbeteren op basis hiervan. |
| IR-201 Gedeeld informatie model | Dit punt is op twee manieren op te vatten. De eerste, zoals binnen InfoQ's artikel vooral bedoelt gaat het over het informatie model van het software ontwikkelingsproces zelf. Zoals je ook metrieken voor bepaalt onder IR-101. Dit informatiemodel gaat over releases, indienen van bepaalde requirements, deze formuleren als requirements en hier bijvoorbeeld unit tests of acceptatie tests voor opstellen. Ook het indelen van de software in modules of componenten (=typisch microservices), en dan de namen van deze microservices of modules. Dit is dus op meta niveau ten opzichte van het 'domeinproces' waarover de ontwikkelde applicatie gaat, en waarop ook een informatiemodel van toepassingen is. Dit gaat dan om entiteiten en hun eigenschappen zoals zichtbaar in het domeinmodel. Om aan te kunnen geven hoe het release proces verloopt, welke feature net is gereleased, of voor een komende release gepland is, of hier nog issues voor open staan, of om terug te zoeken op welke omgeving het staat, of wie dit daar gedeployed heeft, moet iedereen (of in ieder geval de juist mensen) dit terug kunnen halen uit bijvoorbeeld een code mangement systeem, een log van gedraaide pipelines, of overzicht van containers en hun versies in een container registry. Voor dit punt kun je ook denken aan het informatiemodel van de applicatie en van het domein en diens subdomeinen zelf. Denk hierbij aan DDD's ubiquitous language. Dit is een door iedereen gedeelde lijst van woorden, e.g. een 'alomvertegenwoordige taal' in een organisatie. Deze gebruiken dus zowel business mensen tijdens het werk, als developers in hun broncode (class names, foldernamen, variabele namen, methodenamen etc.). Dit houdt in dat de hele organisatie bedoelt hetzelfde met een bepaalde term. Of als één term meerdere dingen betekent in verschillende contexten, zoals bijvoorbeeld verschillende afdelingen van het bedrijf, dan zijn deze (bounded) contexts duidelijk en bekend, en is voor elke context een definitie van de term. In een microservice architectuur heeft idealiter elke microservice eigen opslag (autonomy over authority) en synchroniseer je geen informatie direct via de database (maar heb je validation layer (DDD)). TL;DR: De DDD term 'ubiquitous language' is van belang voor dit checkpoint. Zoals hierboven uitgelegd gaat het bij 'shared information model' vooral om het informatiemodel van het software‑ontwikkelproces. De term 'domein' kan verwarrend zijn; soms is ICT zelf het domein. Binnen dit ICT‑domein is 'semantic versioning' (semver) een belangrijk concept: het geeft betekenis aan versienummers. Je kunt semver toepassen op zowel je applicatie (features/bugfixes per versie) als op tools die je gebruikt. |
| IR-202 Traceerbaarheid ingebouwd in pipeline | Traceren of 'tracing' gaat over het achterhalen van fouten/bugs in software. In een DevOps omgeving denk je dan eerder aan fouten in productie (of staging), i.p.v. nog lokaal (development) waar je deze fouten kunt debuggen in je IDE. Het gaat hierbij ook vaker om integratie bugs. Denk aan automatische release notes/testplannen uit de pipeline en traceerbare koppelingen tussen requirements, builds, tests en releases. |
| IR-301 Graphing-as-a-service | Er is een aparte service die op aanvraag en redelijk gestandaardiseerd grafieken kan aanleveren. In plaats van dat elke applicatie dit intern zelf doet, en elk op eigen wijze. Real‑time dashboards met relevante grafieken per doelgroep. |
| IR-203 Rapportagehistorie is beschikbaar | Als monitoring/metrics eenmaal draaien, wordt historie automatisch opgeslagen zodat je trends kunt zien. Denk aan: aantal critical issues vorige maand vs. nu, request-aantallen per dag op een BFF, of CPU-load over de laatste 3 weken. Tools bewaren deze ruwe data in tijdreeks-/logbackends (bijv. Prometheus TSDB + retention, Loki/ELK met bewaartermijn), waardoor je trendgrafieken en vergelijkingen in de tijd kunt maken. Dit maakt retrospectives en continue verbetering gericht: je ziet het effect van wijzigingen in proces of code. |
| IR-303 Report trend analysis | Gelieerde aan IR-402, maar in plaats van Cross Silo kan in ieder geval binnen een Silo/service/organisatie onderdeel grafieken of gegevens worden opgevraagd, maar dan wel over een bepaalde tijd, om verloop te kunnen analyseren (trend). |
| IR-401 Dynamische grafieken en dashboards | Spreekt hopelijk voor zich? Realtime of i.i.g. 'near realtime' data uit productie op dashboard scherm ook bereikbaar voor business mensen. Bv. het aantal openstaande issues op schermen in team work garden, maar wellicht ook direct inzichtelijk maken als/dat server geheugen volloopt, of tonen van aantal mensen momenteel in check-out scherm van webwinkel (of vergelijkbare 'custom metric' in ander/eigen domein). |
| OA-401 Infrastructure as Code (IaC) | Deze term is te vergelijken met Configuration as Code (CaC OA-203), alleen in plaats van de software configuratie beschrijf je nu de hardware configuratie als code. Oftewel: op welke infrastructuur gaat je software precies draaien. Dus welke CPU, hoeveel geheugen, hoeveel harde schijfruimte, maar bv. ook of bandbreedte. Voor echt hardcore IAC hoort hier ook het type hardware nog bij, zoals heb je Intel processor nodig, of AMD of een Apple M1 o.id., is je harddisk een (snelle) SSD (solid state disk) of ouderwetse magenetische schijf. Typisch gezien doe je dit bij Cloud providers, die dit soort hardware ook kunnen leveren. De precieze opties die je hebt hangen dan ook af van de Cloud provider die je gebruikt. Verschillende cloud providers hebben ook verschillende naampjes voor de machines. Er zijn ook wel speciale IaC tools/talen om meer generiek een config in te schrijven, zoals Cloudformation voor AWS (Amazon Web Services) of Azure Resource Manager (ARM, niet te verwarren met de (RISC) processor met hetzelfde acronym). Deze geven dus een soort abstractielaag om niet alle details te hoeven kennen, en minder afhankelijk te zijn van wijzigingen in hardware die er zijn. En er is zelfs cloud agnostische Terraform (hoewel de machine namen in deze config taal vaak alsnog cloud specifiek zijn). Vergeet ook niet dat je voor IaC ook tools moet hebben die deze config moeten kunnen uitvoeren (anders is het slechts een 'spec', geen code). Dit punt zit dus erg aan de OPS kant, en kun je NIET zomaar afvinken, maar moet je je echt verdiepen in IAC. Als developer wil je je vaak je software juist enigszins onafhankelijk maken van onderliggende hardware details, maar uit handen laten nemen door in te stappen op een 'X As a Service model'. Als er speciale eisen zijn, zoals gebruik GPU's i.p.v. CPU's voor bv, grafische toepassingen, of machine learning kan dit echter niet altijd meer, of als je heel grootschalig gaat werken kun je je kosten besparen als je dit zelf doet. Een goede aanzet voor dit punt, om het 'half af te vinken' kan wel zijn dat je in Kubernetes horizontal podscaling instelt ën je containers draait met zogenaamde Quality of Service instellingen hebben, dus echt vermelden van hardware karakteristieken zoals minimale CPU snelheid en harddisk ruimte. |
CDMM Q&A
Q: Kunnen wij het punt CO-305 - Continuous improvement al behalen door retrospectives uit te voeren over ons individuele handelen en onze processen? A: Niet helemaal, je moet naast probleem analyse (retro), ook verbeterpunten concreet formuleren (denk Transfer uit STARRT methode) en ook doorvoeren in opvolgende sprints (of kunnen uitleggen waarom een voorgenomen improvement in de praktijk er toch niet van kwam) Q: Wat bedoelen jullie met het punt BD-207 - Standaard proces voor alle omgevingen? A: Dit gaat vooral over het deploy proces. Als antwoord een schets van een situatie waarin een team een verschillend proces per omgeving hanteert. Zonder standaardisatie verloopt het deploymentproces verschillend per omgeving:
- Op de developmentomgeving gebruiken teamleden handmatig commando’s om de app te deployen.
- Voor staging upload je bestanden via FTP.
- Production vereist speciale scripts die uniek zijn voor de live-omgeving.
Deze verschillen leiden tot fouten, zoals configuratiemissers, vergeten updates, of inconsistente versies tussen omgevingen.
Q: Voor BD-302 - Meerdere build machines: mag mijn teamgenoot die runnen op zijn VPS? A: Ja
Q: TV-302 - Performance test? Wat moeten wij performance testen? En hoe uitgebreid? A: Performance kritieke onderdelen. Early optimisation is the root of all evil. Zei eens iemand. Maar er kwam nog wat achteraan. En performance is ook een feature, die veel geld of andere waarde (minder verspilde tijd) kan opleveren in sommige domeinen. Dus zo uitgebreid als nodig is om probleem in kaart te krijgen, maar mits het past in jullie tijdsbesteding. Stem af met opdrachtgever. Je moet echter ook wat onderzoek doen in het project, je bent met een heel team. Dus je kunt best goede tools en/of aanpakken onderzoeken. Bv. een profiler in je IDE. Of een load test tool als K6 voor webapps.
Nog over faken data: fake it till you make it
In kader van het 'shift right' is het goed om al tijdens ontwikkelen vooruit te kijken naar relevante metrics die je kunt verzamelen en waarop de business kan handelen. Dit is wel eens beschreven als een soort 13e factor als uitbreiding op de 12factor app principles. Namelijk als 'Telemetry' (namelijk in het boek van Kevin Hoffman (2016))
I like to think of pushing applications to the cloud as launching a scientific instrument into space. [...] If your creation is thousands of miles away, and you can’t physically touch it or bang it with a hammer to coerce it into behaving, what kind of telemetry would you want?
Bronnen
- Hoffman, K. 1st edition, april 2016. Beyond the twelve factor app - Exploring the DNA of Highly Scalable, Resilient Cloud Applications. Oreilly, Pivotal. Geraadpleegd op 23-10-2023 op https://www.cdta.org/sites/default/files/awards/beyond_the_12-factor_app_pivotal.pdf
- Hofer S. & Schwentner H. domainstorytelling.com (2023) Domain Storytelling: Quick-Start Guide - Feeling lost? Workplace Solutions Geraadpleegd 23 oktober 2023 op https://domainstorytelling.org/quick-start-guide#feeling-lost
- Bird, J (2011) Rolling forward and other deployment myths. DZone. Geraadpleegd laatst op https://dzone.com/articles/rolling-forward-and-other
- Smith, Steve "ardalis" (9-11-2023). Deployment vs Release. X Geraadpleegd 13 nov 2023 op https://x.com/ardalis/status/1722728350437757320
- Brannon, J. Against democracy Boekbeschrijving geraadpleegd 23 oktober 2023 op https://www.bol.com/nl/nl/p/against-democracy/9200000075205551/
- Vorne Industries. (z.d.). Kaizen. Leanproduction.com. Geraadpleegd op 22-09-2025, van https://www.leanproduction.com/kaizen/