HAN Minor DevOps - Moderne ICT-technieken
Quick links
Figuur 1: Promo video minor DevOps HAN i.s.m. InfoSupport
Course codes:
- MINDEC05 - Minor DevOps - Course DevOps (15 EC) - iSAS
- MINDEP01 - Minor DevOps - Project (15 EC) - iSAS
Inleiding
In deze minor leren ICT-studenten moderne ICT-technieken voor Continuous Delivery volgens een DevOps aanpak. Studenten werken in teamverband aan de ontwikkeling van een geïntegreerd softwareproduct, waarbij zowel de software en de onderliggende software-architectuur, als de infrastructuur (hardware), en de architectuur en configuratie daarvan aan bod komen.
🤝 DevOps en Samenwerking
Studenten leren applicaties te ontwikkelen door middel van een containerized aanpak. Deze aanpak maakt het mogelijk om veel operationele processen te automatiseren, te werken vanuit een gedeelde backlog en op grotere schaal oude silo's te doorbreken. Het doel hiervan is een snellere 'time to market' te realiseren (shift left). DevOps staat hierbij centraal als een manier van samenwerken: DevOps is cooperation.
🎯 Focus op Non-functional Requirements
Naast functionaliteit voor eindgebruikers, wordt er in deze minor ook gekeken naar non-functionele eisen (NFR's), zoals schaalbaarheid, betrouwbaarheid en onderhoudbaarheid. Deze non-functionele eisen worden soms ook wel 'quality attributes' (QA's) genoemd, omdat goede prestaties vaak essentieel zijn voor de eindgebruiker (performance as a feature).
🚀 Opzetten van Deployment Pipelines
Studenten leren een DevOps-proces opzetten en werken met een CI/CD pipeline voor geautomatiseerde deployment naar productie- en andere runtime-omgevingen, gebaseerd op de 'desired state' in versiebeheer (GitOps). Deze efficiënte en frequente updates maken ook een betere focus op beveiliging mogelijk (DevSecOps). Daarnaast verbetert goede logging en monitoring (SlackOps) het zicht op prestaties, het vroegtijdig detecteren van fouten en zelfs het volgen van bedrijfsdoelen. Dit gebeurt door middel van applicatiespecifieke KPI's en tools die helpen bij het monitoren van de naleving van gemaakte afspraken (SLA's - Service Level Agreement).
📈 Ontwikkelen als "T-shaped Professional"
Deze minor biedt zowel verdieping als verbreding. De instroom is beperkt tot ICT-studenten met een achtergrond in Operations (Infrastructuur, Security) of Development (Software-, Web-, of Data Solutions Development). Alle studenten verbreden hun kennis door elkaars vakgebieden te leren begrijpen en interdisciplinair samen te werken. Tegelijkertijd verdiepen ze zich verder in hun eigen specialisatie door te leren werken met moderne technieken zoals containers, cloud providers, microservices en Agile systeemontwikkeling.
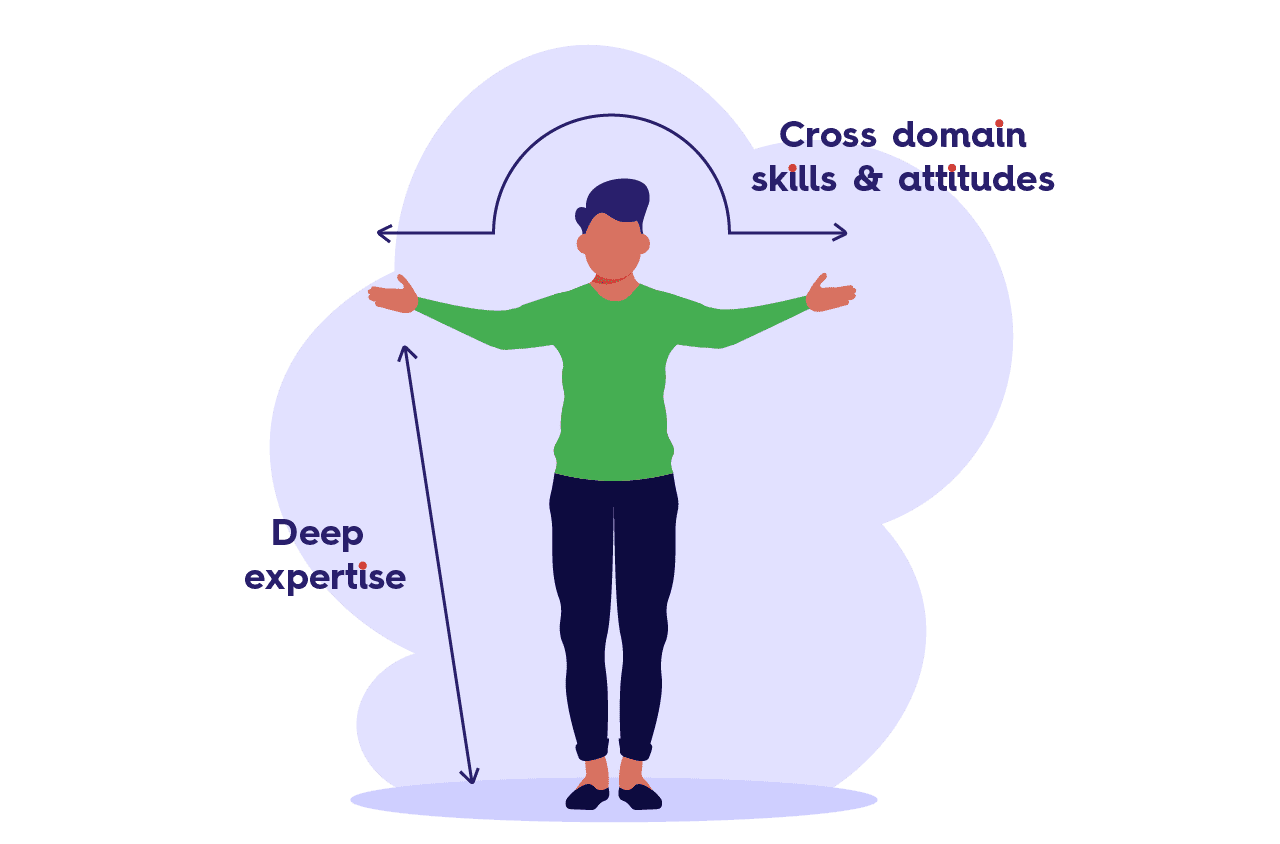
Figuur 3: 'T-shaped DevOps professional' ([
plaatje: agilescrumgroup.com
Kies op maat
Hieronder een kopie van de informatie die op kiesopmaat.nl staat, of zou moeten staan ;). De inschrijving voor de minor is jaarlijks in maart (1e kans) en mei (2e kans) en verloopt via kiesopmaat.nl of minoren-han.nl.
Meldt je ook aan via het aanmeldformulier van InfoSupport - onze bedrijfspartner in de minor.
DevOps (voltijd)
In deze multidisciplinaire minor staat de moderne techniek DevOps centraal. In een DevOps-team werken developers en beheerders samen om nieuwe features van een applicatie te ontwikkelen, en tegelijkertijd de bestaande features draaiende te houden.
Hierbij is er veel aandacht voor het garanderen van een hoge beschikbaarheid van een applicatie. We gaan kijken naar loosely coupled microservices, event-carried state transfer, Docker, Kubernetes, RabbitMQ, unit testen, acceptatie testen, build- en release-pipelines, logging, monitoring, site reliability engineering, kort-cyclisch development en natuurlijk de samenwerking tussen Dev en Ops. De minor bestaat uit twee gedeelten: een gedeelte met theorie en een kleinschalig project waarin zowel je theoretische als praktische kennis wordt voorbereid op het tweede deel: het uitvoeren van een grootschalig project voor een echte klant waarbij je je expertise optimaal kunt benutten. Beide delen worden verzorgd door de HAN en Info Support samen, waarbij de HAN vooral in het eerste en Info Support vooral in het tweede deal de lead zal nemen in de begeleiding.
De minor is alleen toegankelijk voor HBO studenten met een Software Engineering of Development profiel en voldoende studiepunten. Zie verder onder ‘ingangseisen’. Tijdens het project in blok 2 moet je mogelijk een Non Disclosure Agreement (NDA) tekenen en een OV kaart of eigen vervoer hebben i.v.m. ca. een dag per week in Utrecht of andere externe locatie buiten de HAN/Arnhem.
Afhankelijk van je instroom profiel besteed je tijdens deze minor verder aandacht aan de volgende onderwerpen:
- Deployment-tooling (CD/CI-tools, containerization, container orchestration)
- Management en beheer (configuration management, monitoring, logging, cloud providers)
- Test- en Behaviour Driven Development (TDD/BDD)
- Web- en applicatieservers
- Versiebeheer (git) en workflows hierin
- Operating system (linux)
- Netwerken, security en protocollen
- Proxies, load balancers, firewalls
- Chaos engineering, load testing
- Agile practices als story mapping
- DevOps specialisatie van developers bijvoorbeeld ORM, REST en (Domain driven) design en design patterns
- DevOps specialisatie voor infrastructuur specialisten zoals RBAC, log aggregation en Infrastructure as Code (IaC)
Leerdoelen
Na het volgen van deze minor beschik je over de theoretische kennis en praktische vaardigheden om in een professionele organisatie een project uit te voeren met Continuous Delivery door een DevOps aanpak in te voeren en te hanteren.
Ingangseisen
De minor is alleen toegankelijk voor HBO ICT studenten met een development profiel.
Vanwege het verdiepende karakter van de minor moet je ook een 4-e jaars student zijn. We gaan er dus van uit dat je bij aanvang van de minor je (meeloop) stage en verdiepende semester hebt afgerond. Op het moment van inschrijven voor de minor is dit idealiter ook zo, of ben je je verdiepende semester of (meeloop)stage aan het afronden.
Tijdens het project in blok 2 moet je mogelijk een Non Disclosure Agreement (NDA) tekenen en een OV kaart of eigen vervoer hebben i.v.m. ca. een dag per week in Utrecht of andere externe locatie buiten de HAN/Arnhem.
Inhoudelijk gelden verder de onderstaand eisen over je voorkennis en vaardigheden. Deze heb je nodig om tijdens de minor verder uit te bouwen of om mee te kunnen werken in het beroepsproduct aan het eind van de course fase, of het DevOps project in blok 2. Voor het toetsen van het instapniveau verzoeken we ook aangemelde studenten voor aanvang van de minor thuis een digitale ingangstoets te maken. Deze toets geeft jezelf een concreter beeld van de vereiste voorkennis en of je hier nog gaten in hebt. Verder is bij twijfel over toelating, omdat je nog te weinig studiepunten hebt, deze toets ook een mogelijkheid alsnog toegelaten te worden.
- Je kunt object georienteerd programmeren in een getypeerde taal en kent enkele OO design patterns en kan deze herkennen en toepassen (OO)
- Je kunt geautomatiseerde unit en integratie tests schrijven met gebruikmaking van een test framework en -tool (Unit testing)
- Je kunt ontwikkelen volgens Test Driven Development en kent TDD patterns als Red-Green-Refactor, Arrange, Act, Assert en concepten als sut, mocks, stubs, etc. (TDD)
- Je kent de werking van web protocollen als HTTP en DNS en dataformaten als XML en JSON
- Je kent de standaard 3-tier architectuur en principes van andere gelaagde architecturen
- Je kent een aantal basis UML technieken en kan requirements documentatie en technische documentatie opstellen
Rooster
- Er wordt vanuit gegaan dat studenten van maandag t/m vrijdag beschikbaar zijn, dus bijbaantjes of andere vakken van maandag t/m vrijdag (9.00-17.45 uur) volgen is geen optie.
Tijdens het project in het 2e blok ben je verder 1 of 2 dagen per week op locatie bij de opdrachtgever. Dit kan ook buiten Arnhem zijn, afgelopen jaar was dit bijvoorbeeld in Utrecht (vlakbij CS). Uitgangspunt is dat je OV kaart hebt.
De roostering zal plaatsvinden zoals bij de Academie IT & Mediadesign gebruikelijk: in de coursefase (MINDEC05) zes maal per week een dagdeel les, en in de projectfase (MINDEP01) 40 uur per week projectwerk.
Werkvormen
- Werkcolleges
- Projectopdracht
Toetsing
In de course fase (MINDEC05) zijn er wekelijkse huiswerk opdrachten in duo's, enkele individuele theorietoetsen (multiple choice) en geef je een presentatie over een eigen onderzoek. Tot slot maak je in de laatste 2 weken een DevOps beroepsproduct in teamverband. Dit is een uitbreiding van een bestaande demo applicatie onder een microservices architectuur. Hieraan voeg je zowel functionaliteit en bijbehorende tests toe als doe je werk aan de deployment pipeline, custom deployment, monitoring en opstellen architectuur documentatie).
Tijdens het grote project (MINDEP01) maak je een grote applicatie in teamverband met wekelijks klant contact Scrum meetings, met tussentijds en op het eind een beoordeling zowel voor het product als de individuele bijdrage. De DevOps aanpak hierbij volgt ook uit de werkwijze een minimal viable versie van de applicatie vroegtijdig in het project live te zetten en dit daarna up en running te houden tijdens updates.
Aanvullende informatie
Voor inhoudelijke informatie: Bart van der Wal E-mail: bart.vanderwal@han.nl Tel: 06-27081476
Inschrijven? Goed om te weten!
- Bij minoren die starten in september vindt, ná de inschrijfperiode in de maand maart, een loting plaats in april áls er op dat moment meer inschrijvingen zijn dan beschikbare plaatsen.
- Bij minoren die starten in februari vindt, ná de inschrijfperiode in de maand oktober, een loting plaats in november áls er op dat moment meer inschrijvingen zijn dan beschikbare plaatsen.
Bij de minoren waar nog plaats is, geldt daarna tot aan de sluiting van de inschrijfperiode: zodra een minor vol is, wordt deze gesloten, vol = vol.
Daarnaast geldt dat als het aantal aanmeldingen na vier weken ruim onder de norm ligt; deze minor mogelijk wordt teruggetrokken. Dus heb je interesse, meld je direct aan.
Schrijf je op tijd in!
Let op: Voor HAN studenten geldt dat zij zich, in geval van uitloten of geen doorgang van de eerste keuze NA de periode van besluitvorming (deze duurt een volledige maand), kunnen herinschrijven. Dit kan alleen op de dan nog beschikbare minoren die plaatsen vrij hebben.
Ook dan geldt: zodra een minor vol is, wordt deze gesloten.
Beoordelingscriteria en Templates
Deze sectie bevat alle beoordelingscriteria en templates die gelden voor alle projecten in de minor DevOps, zowel tijdens de course fase (beroepsproduct) als het eindproject (blok 2).
📋 Beschikbare documenten
- Beoordelingscriteria en Templates - Complete beoordelingscriteria voor individuele bijdrage
- CDMM (Capability Delivery Maturity Model) - Beoordelingscriteria voor groepsproducten
🎯 Toepassing
Deze criteria worden gebruikt voor:
- ✅ Beroepsproduct (course fase) - Individuele bijdrage en groepsproduct
- ✅ Eindproject (blok 2) - Individuele bijdrage en groepsproduct
- ✅ Alle projecten waar DevOps competenties worden beoordeeld
📝 Templates
Individuele bijdrage
Gebruik het Markdown template individuele bijdrage voor alle projecten.
Groepsproduct
Gebruik de CDMM criteria voor beoordeling van groepsproducten.
🔗 Verwijzingen
Beoordelingscriteria en Templates
- Datum: 11 okt 2021
- Bijgewerkt: 21 okt 2025
- Auteur: Bart van der Wal
1. Inleiding: Verantwoording eigen bijdragen
Naast je beoordeling als team voor het samen gemaakte product krijg je ook een individueel cijfer op basis van jou bijdrage aan dit product. Dit gebeurt voor alle projecten: beroepsproduct (course fase) en eindproject (blok 2).
📋 Keuzevrijheid 2025: In de course fase met DevOps BP (=PitStop uitbreiding) mag je optioneel om 2 van de 9 kopjes leeg laten. Typisch vul je in ieder geval wel de 'functionele uitbreiding' (onder 1), 'tech onderzoek' (4), 'leerervaringen' (8) en 'conclusie' (9) in, maar op zich is het vrije keuze. Tijdens het grote project zijn wel alle kopjes verplicht.
Je hoeft tijdens het project geen uitgebreid verslag te schrijven, en sowieso geen Word documenten, zoals in sommige andere projecten. Maar wel moet elk groepslid wel een eigen markdown bestand toevoegen en bijhouden (direct) in de docs folder van het team repository/project. Hieronder het template. Dit template bevat de volgende 9 kopjes. Bij elk kopje kort vermeld de competenties uit de OWE of 'devops maturity' aspecten die hier in ieder geval bij horen:
-
Code/platform bijdrage
- DevOps-1 Continuous Delivery
- CDMM: Design & Architecture
- CDMM: Test & Verification
-
Bijdrage app configuratie/containers/Kubernetes
- DevOps-2 Orchestration
- DevOps-4 Containerization
- CDMM: Design & Architecture
-
Bijdrage versiebeheer, CI/CD pipeline en/of monitoring
- DevOps-3 GitOps
- DevOps-5 SlackOps
- CDMM: Information & Reporting
- CDMM: Test & Verification
- CDMM: Build & Deploy
-
Onderzoek
- DevOps-6 Onderzoek
-
Bijdrage code review/kwaliteit anderen en security
- DevOps-4 DevSecOps
- CDMM: Culture&Organization
- CDMM: Test & Verification
-
Bijdrage documentatie
- CDMM: Design & Architecture
- DevOps-6 Onderzoek
-
Bijdrage Agile werken, groepsproces, communicatie opdrachtgever en soft skills
- DevOps-7 Attitude*
- CDMM: Culture & Organization
-
Leerervaringen
- DevOps-7 Attitude
- CDMM: Culture & Organization
-
Conclusie & feedback
- DevOps-7 Attitude
Dit document dient als bewijslast richting beoordelaars op meer afstand, maar ook voor je eigen overzicht en ter referentie tijdens de groepssessie voor beoordeling van de individuele bijdrages.
Om een basisvulling te vereisen maar ook al te grote omvang van het document te beperken ivm beoordeelbaarheid, vermeldt het template wat minimum- en maximumaantallen. Dit bestand houdt je bij tijdens het hele project.
Hieronder in sectie 2 wat eisen en richtlijnen over het 'invullen' van het template. In sectie 3 volgt het template zelf, om te copy-pasten naar je eigen repo. In sectie 4, 5 en 6 daarna nog wat achtergrondinformatie bij de individuele beoordeling, de individuele delta die dit geeft op het groepscijfer respectievelijk de algemene beoordelingscriteria die hierbij relevant zijn.
2. Eisen en richtlijnen Individuele verantwoording
Hieronder de richtlijnen in 4 subsecties, maar deze lijst is al de TL; DR:
- Zorg dat template teksten zo snel mogelijk weg zijn uit de templates, uiterlijk bij (en enige ;) tussentijdse beoordeling.
- Zorg dat verantwoording ook tussentijds al leesbaar en compleet is (tussentijds eventueel TODO's voor jezelf)
- Gebruik vrije tekst en bullets
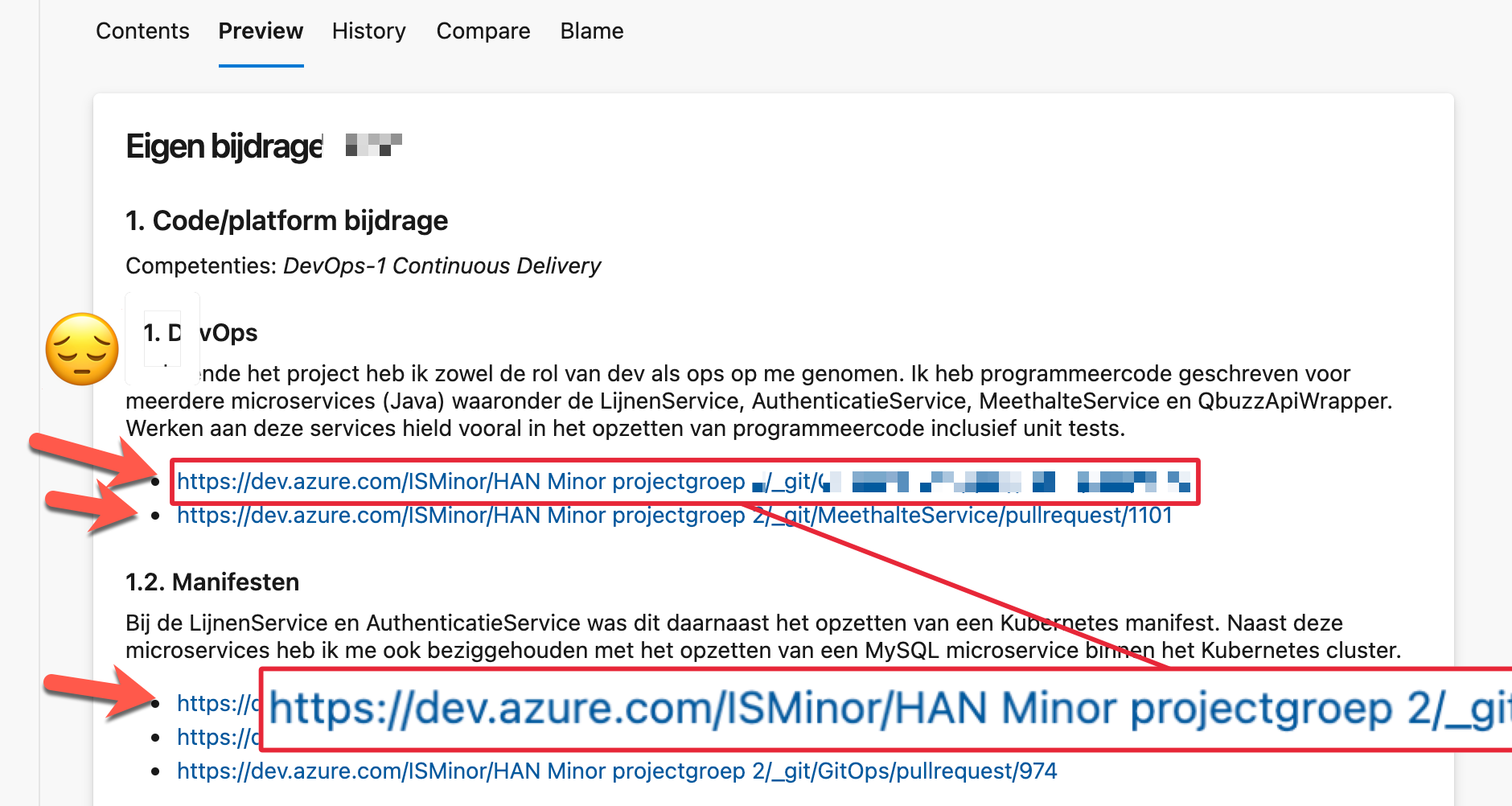
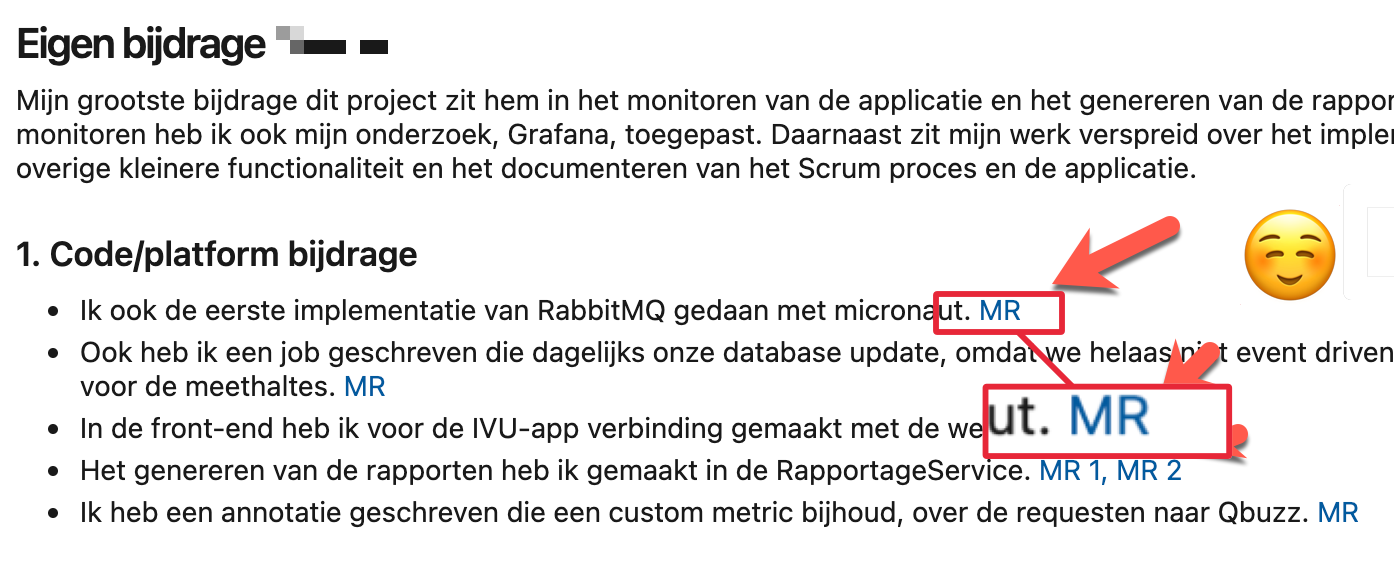
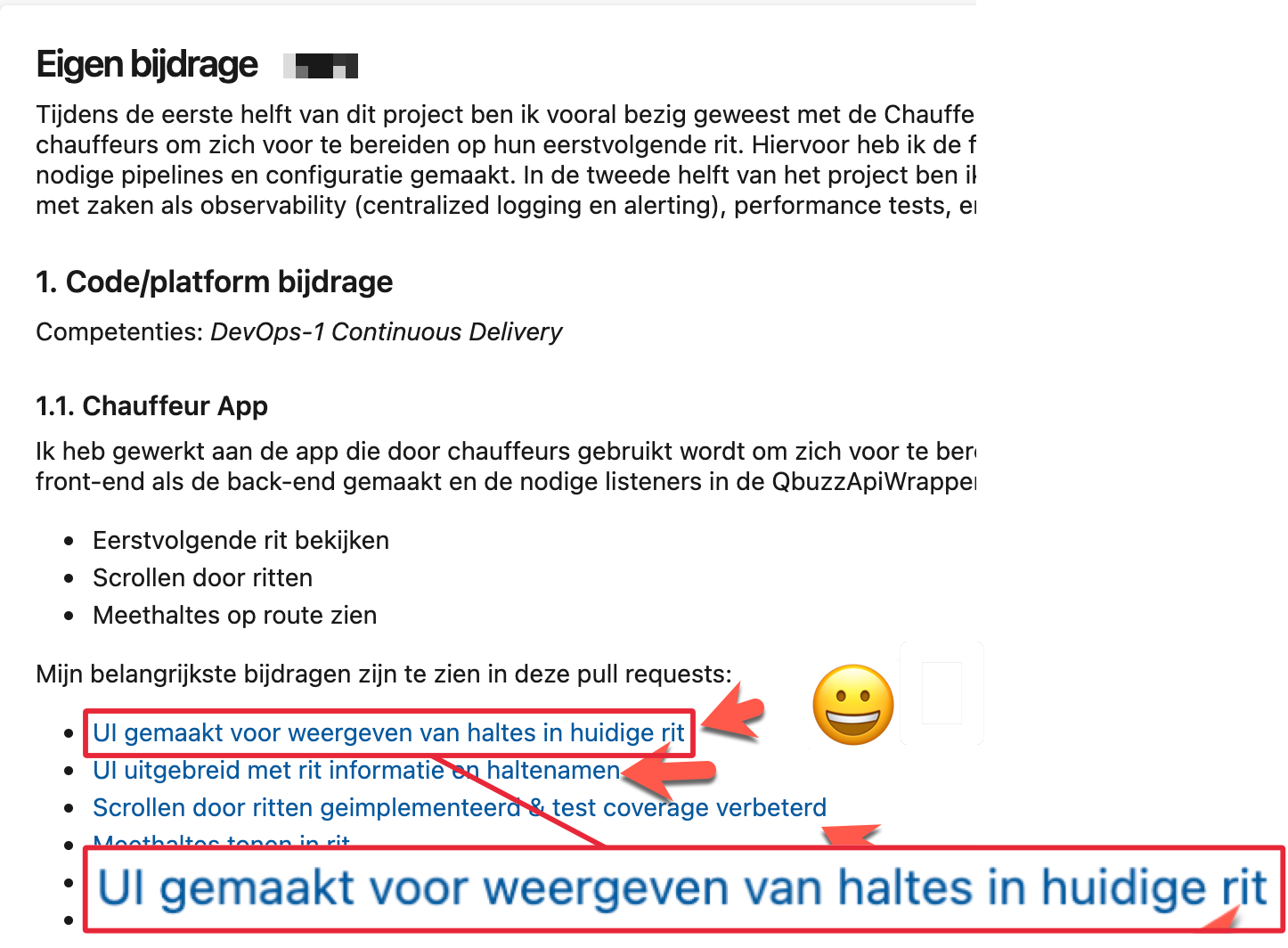
- Gebruik (semantische) linkteksten GEEN kale URL's.
2.1 Beoordelaar kijkt niet als er nog template teksten aanwezig zijn
Verwijder voor het inleveren alle template teksten! Zodat alleen de kopjes (en opgesomde competenties) overblijven!
De template teksten staat in de markdown als hulp. Maar aanwezigheid van deze (standaard) template teksten op het moment van beoordelen ziet de beoordelaar als een teken dat je er nog niet klaar mee bent. Dit heeft als gevolg dat hij/zij dus niet kan beoordelen. Niet (kunnen) beoordelen betekent een onvoldoende!
Vervang bijvoorbeeld <mijn-naam> door Eliezer Yudkowsky. NB: Dus NIET <Eliezer Yudkowsky >; de angle brackets (< en >) zijn om templateteksten aan te geven, dus bij invullen moet je deze WEGhalen.
2.2 Ook leesbaar en compleet bij tussentijdse beoordeling
Bij tussentijdse toetsing heb je al een volledige en leesbare versie, met minstens de minimale aantallen. Richting de eindbeoordeling werk je deze verder bij, en schrapt evt. punten als je anders over het maximum aantal gaat en je inmiddels grotere/belangrijker zaken hebt. Of als je punten kunt samenvoegen onder 1 noemer (N.B. Punten zijn evt. terug te vinden via versie historie).
Dus je vult ook al een voorlopige eindoordeel in. En bijvoorbeeld hebt ook al de helft van de tips en tops.
Mocht je er tussentijds achterkomen dat onder een kopje nog te weinig of zelfs GEEN werk en/of links kunt geven, neem voor je zelf dan wat TODO's op, met een richting, zodat je in de 2e helft kunt zorgen dat je wel voldoende variëteit en breedte in je werk hebt.
2.3 Gebruik vrije tekst én bullets
TL; DR Dus: gebruik een combinatie van beschrijvende teksten en korte bullet lijsten met links naar werk in het met team gebruikte 'code management systeem' waarmee beoordelaar je werk kan verifieren.
De bedoeling van deze verantwoording is dat het korte tekstuele beschrijving is. Voor structuur gebruik je hierbij ook bullets. Maar je gebruikt NIET alleen maar bullets, of alleen maar paragrafen. Je gebruikt een combinatie. Typisch is een paragraaf dan een inleiding bij een bullet lijst, zoals Qua Kubernetes configuratie deed ik het volgende. Of een toelichting bij iets interessantes. Schrijf ook een korte inleiding.
2.4 Gebruik linkteksten
- Maak van links shortlinks, dus met goede linktekst en niet de hele originele URL’s (die nemen anders groot deel van je documentatie in beslag, dat is ongewenst)
- Maak deze links ook naar bv. code diffs of pull requests i.p.v. direct naar volledige bestanden/folders in versiebeheer met integrale stukken code die van iedereen in het team kunnen (en horen!) te zijn.
- Plaats ook opmerkingen in pull requests (review opmerkingen) en github issues ().
Het agile principe van face-to-face contact is ook belangrijk, maar stem niet alles alleen maar mondeling af; zorg voor de traceerbaarheid en beoordeelbaarheid door externen. Zo heeft groepsgenoot ook iets om op terug te vallen na mondeling afstemmen (of deze zet zelf de mondeling gegeven feedback in het issue).
Als je dit onverhoopt tijdens het project te weinig gedaan hebt, kun je alsnog dit documenteren. In je markdown zelf maakt deze wellicht te groot, maar dan kan het in een taak/issue waar je in markdown naar linkt, of in de wiki o.i.d. (hier hebben jullie hopelijk ook team standaard voor, en anders kun je die wellicht met terugwerkende kracht opstellen, in kader van overdracht naar anderen, nu jullie dit project gaan verlaten).
Dus vervuil je markdown niet met hele lange URL links, maar kort deze in, of - beter nog - maak een linktekst die echt semantisch is, en ook thuishoort in een lopende tekst. In de tabel hieronder drie voorbeelden.
| Mwegh... | Okee. | Top! |
|---|---|---|
 |  |  |
3. Markdown template individuele bijdrage
# Eigen bijdrage <mijn-naam>
Als deliverable voor de individuele bijdrage in het beroepsproduct maak een eigen markdown bestand `<mijn-voornaam>.md` in je repo aan met tekst inclusief linkjes naar code en documentaties bestanden, pull requests, commit diffs. Maak hierin de volgende kopjes met een invulling.
Je schrapt verder deze tekst en vervangt alle andere template zaken, zodat alleen de kopjes over blijven. **NB: Aanwezigheid van template teksten na inleveren ziet de beoordelaar als een teken dat je documentatie nog niet af is, en hij/zij deze dus niet kan of hoeft te beoordelen**.
Je begin hier onder het hoofdkopje met een samenvatting van je bijdrage zoals je die hieronder uitwerkt. Best aan het einde schrijven. Zorg voor een soft landing van de beoordelaar, maar dat deze ook direct een beeld krijgt. Je hoeft geen heel verslag te schrijven. De kopjes kunnen dan wat korter met wat bullet lijst met links voor 2 tot 4 zaken en 1 of 2 inleidende zinnen erboven. Een iets uitgebreidere eind conclusie schrijf je onder het laatste kopje.
## 1. Code/platform bijdrage
Competenties: *DevOps-1 Continuous Delivery*
Beschrijf hier kort je bijdrage vanuit je rol, developer (Dev) of infrastructure specialist (Ops). Als Developer beschrijf en geef je links van minimaal 2 en maximaal 4 grootste bijdrages qua code functionaliteiten of non-functionele requirements. Idealiter werk je TDD (dus ook commit van tests en bijbehorende code tegelijk), maar je kunt ook linken naar geschreven automatische tests (unit tests, acceptance tests (BDD), integratie tests, end to end tests, performance/load tests, etc.). Als Opser geef je je minimaal 2 maximaal 4 belangrijkste bijdragen aan het opzetten van het Kubernetes platform, achterliggende netwerk infrastructuur of configuration management (MT) buiten Kubernetes (en punt 2).
## 2. Bijdrage app configuratie/containers/kubernetes
Competenties: *DevOps-2 Orchestration, Containerization*
Beschrijf en geef hier links naar je minimaal 2 en maximaal 4 grootste bijdragen qua configuratie, of bijdrage qua 12factor app of container Dockerfiles en/of .yml bestanden of vergelijkbare config (rondom containerization en orchestration).
## 3. Bijdrage versiebeheer, CI/CD pipeline en/of monitoring
Competenties: *DevOps-1 - Continuous Delivery*, *DevOps-3 GitOps*, *DevOps-5 - SlackOps*
Beschrijf hier en geef links naar je bijdragen aan het opzetten en verder automatiseren van delivery pipeline, GitOps toepassing en/of het opzetten van monitoring, toevoegen van metrics en custom metrics en rapportages.
NB Het gebruik van *versiebeheer* ((e.g. git)) hoort bij je standaardtaken en deze hoef je onder dit punt NIET te beschrijven, het gaat hier vooral om documenteren van processtandaarden, zoals toepassen van een pull model.
## 4. Onderzoek
Competenties: *Nieuwsgierige houding*
**Course BP (Spike Onderzoek):** Beschrijf hier je **spike onderzoek** naar CNCF technologieën en je **groepspresentatie**. Wat heb je onderzocht, welke bevindingen had je, en hoe heb je dit gepresenteerd aan je team? Link naar je onderzoeksmateriaal, prototypes of documentatie.
**Eindproject:** Beschrijf hier onderzoek naar het domein en nieuwe onderzochte/gebruikte DevOps technologieën. Verder heb je nu een complex domein waar je in moet verdiepen en uitvragen bij de opdrachtgever. Link bijvoorbeeld naar repo's met POC's, domein modellen of beschrijf andere onderwerpen en link naar gebruikte bronnen.
Als je eerder onderzochte technologie wel toepasbaar is kun je dit uiteraard onder dit punt noemen. Of wellicht was door een teamgenoot onderzochte technologie relevant, waar jij je nu verder in verdiept hebt en mee gewerkt hebt, dus hier kunt beschrijven. Tot slot kun je hier ook juist een korte uitleg geven over WAAROM jouw eerder onderzochte technologie dan precies niet relevant of inpasbaar was. Dit is voor een naieve buitenstaander niet altijd meteen duidelijk, maar kan ook heel interessant zijn. Bijvoorbeeld dat [gebruik van Ansible in combi met Kubernetes](https://www.ansible.com/blog/how-useful-is-ansible-in-a-cloud-native-kubernetes-environment) niet handig blijkt. Ook als je geen uitgebreid onderzoek hebt gedaan of ADR hebt waar je naar kunt linken, dan kun je onder dit kopje wel alsnog kort conceptuele kennis duidelijk maken.
## 5. Bijdrage code review/kwaliteit anderen en security
Competenties: *DevOps-7 - Attitude*, *DevOps-4 DevSecOps*
Beschrijf hier en geef links naar de minimaal 2 en maximaal 4 grootste *review acties* die je gedaan hebt, bijvoorbeeld pull requests incl. opmerkingen. Het interessantst zijn natuurlijk gevallen waar code niet optimaal was. Zorg dat je minstens een aantal reviews hebt waar in gitlab voor een externe de kwestie ook duidelijk is, in plaats van dat je dit altijd mondeling binnen het team oplost.
## 6. Bijdrage documentatie
Competenties: *DevOps-6 Onderzoek*
Zet hier een links naar en geef beschrijving van je C4 diagram of diagrammen, README of andere markdown bestanden, ADR's of andere documentatie. Bij andere markdown bestanden of documentatie kun je denken aan eigen proces documentatie, zoals code standaarden, commit- of branchingconventies. Tot slot ook user stories en acceptatiecriteria (hopelijk verwerkt in gitlab issues en vertaalt naar `.feature` files) en evt. noemen en verwijzen naar handmatige test scripts/documenten.
## 7. Bijdrage Agile werken, groepsproces, communicatie opdrachtgever en soft skills
Competenties: *DevOps-1 - Continuous Delivery*, *Agile*
Beschrijf hier minimaal 2 en maximaal 4 situaties van je inbreng en rol tijdens Scrum ceremonies. Beschrijf ook feedback of interventies tijdens Scrum meetings, zoals sprint planning of retrospective die je aan groepsgenoten hebt gegeven.
Beschrijf tijdens het project onder dit kopje ook evt. verdere activiteiten rondom communicatie met de opdrachtgever of domein experts, of andere meer 'professional skills' of 'soft skills' achtige zaken.
## 8. Leerervaringen
Competenties: *DevOps-7 - Attitude*
Geef tot slot hier voor jezelf minimaal 2 en maximaal **4 tops** en 2 dito (2 tot 4) **tips** á la professional skills die je kunt meenemen in toekomstig project, afstuderen of wellicht zelfs verdere loopbaan (de 'Transfer' uit STARRT). Beschrijf ook de voor jezelf er het meest uitspringende hulp of feedback van groepsgenoten die je (tot dusver) hebt gehad tijdens het project.
## 9. Conclusie & feedback
Competenties: *DevOps-7 - Attitude*
Schrijf een conclusie van al bovenstaande punten. En beschrijf dan ook wat algemener hoe je terugkijkt op het project. Geef wat constructieve feedback, tips aan docenten/beoordelaars e.d. En beschrijf wat je aan devops kennis, vaardigheden of andere zaken meeneemt naar je afstudeeropdracht of verdere loopbaan.
4. Werkwijze beoordeling individuele bijdrage
Voor je individuele bijdrage in het project krijg je ook een beoordeling.
4.1 Input voor beoordeling
Basis hiervoor is de input van je teambegeleider(s), en evt. observaties van de klant/opdrachtgever tijdens Scrum ceremonies of daarbuiten of andere door beoordelaars belangrijk gevonden punten. De inbreng tijdens Productdemo of de Review sessie kan ook doorslag geven als je ervoor nog te weinig zichtbaar was. Uiteraard weegt ook mee het correct en voor externen ook leesbaar en begrijpelijk invullen van bovenstaand template met je verantwoording van je individuele bijdrage.
4.2 Groepssessie individuele beoordeling
De uiteindelijke individuele beoordeling gebeurt n.a.v. een groepssessie. Dit klinkt wellicht tegenstrijdig, want je focust in de verantwoording op eingen werk, maar we gaan er vanuit dat je toelichting bekend is bij teamgenoten en geen verantwoording. Omdat samenwerking met groepsgenoten en bv. het reviewen van elkaars werk, of anderszins samenwerken centraal staat bij DevOps. Tijdens de sessie geef je ingevulde tekst toelicht. Deze meeting duurt een half uur tot een uur afhankelijk van je groepsgrootte. Je hebt hierbij ongeveer 5 minuten voor je eigen werk. Deze sessie plan je in met je begeleiders/beoordelaars. De begeleider vraagt tijdens deze sessie bijvoorbeeld het volgende:
- Waar ben je het meest trots op van je bijdragen aan het teamproduct?
- Waar heb je nog het minst laten zien?
- Vervolgens lopen we samen snel door je factsheet heen
Aan het eind van de sessie geeft de beoordelaar aan wat je delta op het groepscijfer is.
Als teamlid mag je opmerkingen/input geven, maar we proberen discussies te bewaren voor andere contactmomenten.
4.3 Gebruik links
Naast de tekst zelf is natuurlijk de kwaliteit van het daarin gelinkte bronmateriaal (zorg dat de links zelf ook werken, en bv. wijzen naar een diff of review van eigen werk, i.p.v. naar werk van anderen). Zorg ook dat het presentabel is door GEEN kale lange URL's te geven, maar de URL's zelf waar mogelijk in te korten maar ook netjes achter een link te stoppen met korte maar duidelijke linktekst in een duidelijke en actief geschreven zin (of herschrijf).
5. Delta op teamcijfers
Je eindcijfer is het groepscijfer en nog individuele 'delta' hierop. Deze delta is in principe 0, dus dat betekent dat je eindcijfer hetzelfde is als het groepcijfer. Maar als beoordelaars aanleiding hebben kunnen deze een delta geven die variëert van -1 tot +2 op het teamcijfer. Ook geldt dat als je als teamlid geheel niet of duidelijk te weinig hebt bijgedragen, of je bijdrage niet voldoende kunt verantwoorden, dan is je eindcijfer een onvoldoende, ongeacht het teamcijfer. Dit laatste betekent dus dat je het project een volgende editie over moet doen. Hetzelfde geldt uiteraard als na toepassen van een delta je eindcijfer onder de 5,5 zit.
2Project niet afgerond4.5Project gedaan maar onvoldoende bijgedragen (geen vormbehoud courses) en/of deze bijdrage niet voldoende verantwoord-1Op aantal punten tekort geschoten, maar wel significante bijdrage-0,5Op één of enkele punten tekortgeschoten op verwachte input of toegezegde bijdrage+0Project goed meegewerkt, gezorgd voor significante bijdrage en kwaliteit en vormbehoud van course+0,5Erkenning van belangrijke bijdrage op een aspect van het teamproduct of -proces+1Belangrijke extra invloed qua kwantiteit of kwaliteit van teamproduct binnen het team op één of enkele punten+2Op een aantal punten een essentiële positieve extra invloed qua kwaliteit, kwantiteit van werk
Om bovenstaande wat concreter te maken hieronder enkele (fictieve) beschrijvingen van projectsituaties en de hieruit voortkomende beoordeling.
5.1 Voorbeeld 1
Een team heeft als teamcijfer een 7 gehaald met een weinig opvallend project met wel een enthousaste en duidelijk einddemo. Eigenlijk al het gevraagde zat erin, zij het minimaal. Teamlid A heeft een belangrijke invloed gehad bij de realisatie van de database, en is 'above and beyond' gegaan en krijgt een 7+1=8. Teamlid B heeft steady gecodeerd, maar heeft geen enkele verslaglegging gedaan en kan achteraf ook onvoldoende terugvinden in aangemaakte issues of commit opmerkingen om dit nog te fixen voor de inlever deadline. Een 4.
5.2 Voorbeeld 2
Een team heeft een 6 gekregen. In dit team is Teamlid X in week 2 helaas uitgevallen (een 1). Het security aspect missen zij geheel, want heeft verder niemand opgepakt ondanks dat dit teamverantwoordelijkheid is. Wel is er een nieuw microservice en wijzigingen in back-end en front-end met noSQL storage. Teamlid Y heeft een bestaand issue nooit gefixt, hoewel dit wel met hem is afgesproken omdat dit bij zijn expertise hoorde. Achterliggende reden was dat zijn technologie toch niet in bleek te passen in het beroepsproduct en hierdoor was hij gedemotiveerd.
De team beslissing bij sprint 2 om dit te laten vallen en te documenteren als ADR was hij het eigenlijk niet mee eens. Maar dat durfde hij toen niet te zeggen. Omdat hij achter de schermen bleef 'doormodderen' kwam hij een week onvoldoende aan zijn issues toe. Gelukkig kon hij hier wel op reflecteren en heeft op de front-end in de week erna nog goed bijgedragen: (6-0.5 = 5.5).
Teamlid Z heeft alle issues van X opgelost, en ook de hele front-end opgezet, en hierbij ook een BDD aanpak gerealiseerd waardoor vanuit de front-end de hele applicatie geacceptatest kan worden: 6+2 = 8.
6. Beoordelingscriteria
Bij de beoordeling is uitgangspunt dus een ingevulde individuele bijdrage en uiteraard ook alles wat erachter zit qua product/configuratie en documentatie in gitlab/versiebeheer. De beoordelaars hebben verder ook indrukken beoordelaars tijdens SCRUM sessies en dergelijke. Tijdens het project hoef je niet alles te doen wat in de course behandeld is, maar je hebt hier wel gebruik van gemaakt en toont vormbehoud op de competenties uit de course fase (zoals ook vermeld in individuele bijdrage):
- DevOps-1 Continuous Delivery
- DevOps-2 GitOps
- DevOps-3 Containerization
- DevOps-4 DevSecOps
- DevOps-5 SlackOps
- DevOps-6 Onderzoek
- DevOps-7 Attitude
Verder kunnen beoordelaars ook algemene teamcompetenties meenemen zoals:
- Focus op kwaliteit en kwantiteit van het werk
- Pragmatisch houding (KISS) en rol pakken
- Teamgenoten helpen
- Kritische houding, focus op testen, security en reliability
- Aanspreekbaar zijn en verantwoordelijkheid nemen
- Nieuwsgierige en onderzoekende houding
CDMM Criteria Overview
📊 Open CDMM tabel als volledige pagina | ✅ CDMM Tracker (interactieve checklist)
🧑🤝🧑 Cultuur & Organisatie (CO)
CO - Basis (2)
- CO-001 Werk geprioriteerd
- CO-002 Gedefinieerd en gedocumenteerd proces
- CO-003 Frequente commits
CO - Beginner (4)
- CO-101 Eén backlog per team
- CO-102 Delen van pijn
- CO-103 Stabiel team per project
- CO-104 Basis Agile methode
- CO-105 Testen onderdeel van development
CO - Gemiddeld (6)
- CO-201 Multidisciplinair team (betrekken DBA, CM)
- CO-202 Component eigenaarschap
- CO-203 Handelen op metrics
- CO-204 Ops & Dev samen
- CO-205 Vast proces voor wijzigingen (DB/CM/Docs/Code/Artefacts)
- CO-206 Decentrale besluitvorming
CO - Gevorderd (8)
- CO-301 Dedicated tools team
- CO-302 Team verantwoordelijk tot productie
- CO-303 Deploy losgekoppeld van release
- CO-304 Continuous improvement (Kaizen)
CO - Expert (10)
- CO-401 Cross-functional team (=CO-201++)
- CO-402 No rollbacks (always roll forward)
⛪ Ontwerp & Architectuur (OA)
OA - Basis (2)
OA - Beginner (4)
- OA-101 Systeem opsplitsen in modules
- OA-102 API-gestuurde aanpak
- OA-103 (3rd party) Library management
OA - Gemiddeld (6)
- OA-201 Geen of minimale branching
- OA-202 Branch by abstraction
- OA-203 Configuratie als Code (CaC)
- OA-204 Feature hiding (feature toggle e.d.)
- OA-205 Modules omzetten naar componenten
OA - Gevorderd (8)
- OA-301 Volledige component gebaseerde architectuur
- OA-302 Strict api-based approach
- OA-303 Graph business metrics uit applicatie
OA - Expert (10)
- OA-401 Infrastructure as Code (IaC)
🏗️ Build & Deploy (BD)
BD - Basis (2)
- BD-001 Code in versiebeheer
- BD-002 Gescripte builds
- BD-003 Basis scheduled builds (CI)
- BD-004 Dedicated build server
- BD-005 Gedocumenteerde handmatige deploy
- BD-006 Enkele deployment scripts bestaan
BD - Beginner (4)
- BD-101 Polling builds
- BD-102 Opslag van build (milestone)
- BD-103 Handmatige tags en versies
- BD-104 Eerste stap naar standaardisatie deploys
- BD-105 DB wijzigingen in VCS
BD - Gemiddeld (6)
- BD-201 Auto-triggered builds (commit hooks)
- BD-202 Geautomatiseerde tags & versies
- BD-203 Build once deploy anywhere
- BD-204 Automatiseer meeste DB wijzigingen
- BD-205 Basis pipeline, prod deploy
- BD-206 Gescripte config wijzigingen
- BD-207 Standaard proces voor alle omgevingen
BD - Gevorderd (8)
- BD-301 Zero downtime deploys
- BD-302 Meerdere build machines
- BD-303 Volledig automatische DB deploys
BD - Expert (10)
- BD-401 Build bakery
- BD-402 Zero touch continuous deployment
🧪 Test & Verificatie (TV)
TV - Basis (2)
- TV-001 Automatische unit tests
- TV-002 Aparte testomgeving
TV - Beginner (4)
- TV-101 Automatische integratietests
TV - Gemiddeld (6)
- TV-201 Automatische component test (geïsoleerd)
- TV-202 Enkele automatische acceptatietests
TV - Gevorderd (8)
- TV-301 Volledige automatische acceptatietests
- TV-302 Automatische performance tests
- TV-303 Automatische security tests
- TV-304 Risico gebaseerde handmatige tests
TV - Expert (10)
- TV-401 Verifieer verwachte bedrijfswaarde
📈 Informatie & Rapporteren (IR)
IR - Basis (2)
- IR-001 Basis procesmetrics
- IR-002 Handmatige rapportages
IR - Beginner (4)
- IR-101 Meet het proces
- IR-102 Statische code analyse
- IR-103 Periodieke automatische kwaliteitsrapportage
IR - Gemiddeld (6)
- IR-201 Gedeeld informatiemodel
- IR-202 Traceerbaarheid ingebouwd in pipeline
- IR-203 Rapportagehistorie is beschikbaar
IR - Gevorderd (8)
- IR-301 Graphing-as-a-service
- IR-302 Dynamic test coverage analysis
- IR-303 Report trend analysis
IR - Expert (10)
- IR-401 Dynamische grafieken en dashboards
- IR-402 Cross-silo analysis
CDMM tabel (HTML)
Klik om de interactieve CDMM-tabel (met hover-tooltips) te tonen
Originele bron met grote afbeelding: InfoQ – The Continuous Delivery Maturity Model .
Projectrooster
Hieronder het rooster voor het project. Zie ook de via Slack gecommuniceerde Excel sheet. Toelichting hieronder. Als je inconsistentie tussen dit rooster en de .pdf opmerkt, meld dit dan bij de docent!
| Week | Maandag | Dinsdag | Woens | Donder | Vrijdag |
|---|---|---|---|---|---|
| Week 1 10-14 nov | Kick-off 🥪 📍 Amersfoort | DoR/WoW opst. | Planning 1 | ..ops | Tech Review 1 📍 Utrecht Tech Review 1 App basis, pipeline ingericht en productieomgeving GitOps-werkwijze aantonen; CI-pipeline met build/test/artefact; minimaal één front-end en back-end op Kubernetes... → Meer details en eisen |
| Week 2 17-21 nov | Vragenuur DevOps | dev.. | dev.. | ..ops | Sprint Review 1 📍 Utrecht Sprint Review 1 Product Increment conform overeengekomen sprintdoel en user stories. → Aandachtspunten Sprint 1 |
| Week 3 24-28 nov | Planning 2 | Retro 1 | dev.. | + Staging | Tech Review 2 📍 Utrecht Tech Review 2 Staging+productie, CD werkt+BODA Container registry gebruiken; pipeline bouwt image en geautomatiseerde deploy; parametrisatie voor meerdere omgevingen. Build Once Deploy Anywhere (BODA) betekent één Docker-image voor alle omgevingen... → Meer details en eisen |
| Week 4 1-5 dec | Vragenuur DevOps | dev.. | dev.. | ..ops | Sprint Review 2 📍 Utrecht |
| Week 5 8-12 dec | Ind TT | Retro 2 | dev.. | ..ops | Tech Review 3 📍 Utrecht Tech Review 3 Performance- en/of loadtesten Performance- en/of loadtesten met K6 o.i.d.; realistisch end-to-end scenario uit domein. Tijdelijke testomgeving automatisch opzetten/afbreken... → Meer details en eisen |
| Week 6 15-19 dec | Vragenuur DevOps | dev.. | dev.. | ..ops | Sprint Review 3 📍 Veenendaal |
| Kerst vakantie | |||||
| Kerst vakantie | |||||
| Week 7 5-9 jan | Planning 4 | Retro 3 | dev.. | ..ops | Tech Review 4 📍 Utrecht Tech Review 4 Observability & Resilience Verplicht: Observability/monitoring-stack (combineer applicatie- en platform-metrics) én Chaos Engineering (testen van fouttolerantie en resilience). Optioneel aanvullend: Specifieke K8S/CNCF tech of andere relevante technologieën onderzoeken en toepassen (bijv. RabbitMQ clustering, ELK stack, readonly copy van Postgres database, MCPS omgeving features, Azure DevOps features, security hardening, risico gebaseerde tests, health check/liveness endpoints in K8S, of andere project-specifieke tech). → Meer details en eisen |
| Week 8 12-16 jan | Vragenuur DevOps | dev.. | dev.. | ..ops | Sprint Review 4 📍 Amersfoort |
| Week 9 19-23 jan | Ind EIND | ||||
| Week 10 26-30 jan | Herkansingen toetsen courses |
Overzicht Project Blok 2
Projectduur: 9 weken, opdracht voor een echte klant
- Begeleiding en beoordeling door InfoSupport, eindbeoordeling door HAN.
Na de courses start het project in blok 2. Het doel van de courses is om voldoende basis te leggen voor dit project. Je werkt voor een echte opdrachtgever en levert zo snel mogelijk op naar een productieomgeving volgens DevOps-principes. Daarna blijf je doorontwikkelen, inclusief non-functional requirements en quality attributes.
De volledige eisen, competenties en beoordelingscriteria staan in de OWE. Voor een introductie: opdrachtbeschrijving. Meer details over het project volgen in week 9 van de course, waar je ook kennismaakt met de opdrachtgever. Zie eisen eindproject in blok 2 voor aanvullende informatie.
Projectaanpak
Het project volgt een Agile/Scrum-werkwijze met 4 sprints van elk 2 weken. Teams werken iteratief en incrementeel, waarbij elke sprint een werkend product increment oplevert. Er is geen vaste fasering zoals in traditionele waterval-projecten; in plaats daarvan wordt continu doorontwikkeld op basis van feedback van de opdrachtgever en nieuwe inzichten.
Bij de start van het project (kick-off en eerste sprint) is het belangrijk om het domein goed te begrijpen. Daarom wordt er in de eerste sprint een domein model opgesteld, samen met een glossary (woordenlijst). Zie pagina oveDomein Model op deze website voor meer informatie.
Belangrijke Details
- Projectduur: 40 uur per week
- PreGame: 2 dagen voor kick-off, User Storymapping en oriëntatie op ontwikkelomgeving.
- Scrum ceremonies: Teams verzorgen zelf alle ceremonies zoals Daily Standups, Sprint Planning, Retrospectives, etc.
- Begeleiding:
- Korte statusupdates op vrijdag door HAN-begeleiders.
- Communicatie via e-mail, Slack of korte Teams-calls.
- Korte statusupdates op vrijdag door HAN-begeleiders.
- Sprint Reviews: Met Product Owner op vrijdag in week 2, 4, 7, 9.
- Tussendoor: Vragenuur DevOps op maandag in alle weken.
- Bereid vragen goed voor en kom met concrete voorstellen of alternatieven.
Technische Reviews & Evaluaties
- Tech Review (om de week): Iedere sprint heeft een kernopdracht en een groeidoel. Lever bewijs aan in pipeline, repo of dashboards.
- Sprint Review: Eind van iedere sprint bij de opdrachtgever; statusupdates richting HAN op vrijdag.
- Beoordelingsmomenten:
- Beoordeling is op basis van het hele project, maar met name van de review momenten, met ook een offcieler moment in week 4 Sprint review en tussentijds individuele beoordeling begin week 5 op basis van markdown template/factsheet en het eindcijfer op bvasis van de laatste Sprint Review in Sprint 4 en eindsessie begin week 9 voor individuele veratwoording. Beoordeling door HAN-docent(en) op basis van input vanuit werk in repo, gegevens demo's en observaties en feedback van opdrachtgever/Produt Owner en de InfoSupport-begeleiders.
- Dinsdag voor beoordeling: groepssessie voor individuele verantwoording (tussentijdse cijfer en individuele verantwoording).
📋 Zie Eisen Eindproject voor gedetailleerde informatie over de tech reviews, sprint reviews en de koppeling met de beoordelingscriteria.
Werkdagen & Locatie
- Maandag, dinsdag, woensdag, donderdag: Zelfstandig werken aan DevOps-taken, thuis of op de HAN.
- Locatie-ontwikkeling: Vrijdagen op locatie voor demo's/reviews; deze duren meestal maximaal een half uur.
- Eindpresentatie (week 9): Alle groepen presenteren voor de opdrachtgever en elkaar.
Eisen aan eindproject van DevOps minor
| Datum | Wijziging |
|---|---|
| 5-12-2025 | Aandachtspunten per sprint aangevuld met code diagrammen (optioneel: class diagrams, data model, sequence diagrams), performance/load tests, BDD/Gherkin .feature bestanden (optioneel), en onderzoek naar monitoring/chaos engineering of andere relevante technologie in Sprint 4. |
| 7-11-2025 | Sectie "Tech Reviews en Sprint Reviews" toegevoegd met extra details 2025 over de high-level werkwijze tijdens het project. |
De opdrachtomschrijving voor het project in blok 2 volgt tijdens dat blok zelf. De requirements moet je 'agile' afstemmen met de klant/opdrachtgever.
De totale beoordeling bestaat uit een oordeel over jullie DevOps teamproduct en een oordeel over je individuele bijdrage op basis van je eigen verantwoording. De beoordeling over het teamproduct staat hieronder beschreven. De individuele beoordeling is volgens hetzelde model als die voor de Course BP.
Beoordeling groepscijfer
Hieronder de eisen en beoordelingscriteria voor het teamproduct. Onderstaand de 6 eisen met korte samenvatting, maar verdere secties geven de details hiervan:
- een ingevuld self assessment
- CDMM checkpoints met toelichtingen + cijfer indicatie 5 hoofdcategorieën
- a. Omgang Technologie
- techstack, devops tools, monitoring/metrics
- b. Jullie 'Way of Working'
- Scrum, Storymap, etc.
- c. Build en Deployment
- ontwikkelstraat, Azure DevOps, etc.
- d. Documentatie
- C4, continuous documentation, ADR's, etc.
- e. Soft Skills
- effectief Agile werken, communiceren en presenteren aan technische+niet technische stakeholders
Na de gedetailleerde beschrijving van criteria A t/m E volgt een sectie over Tech Reviews en Sprint Reviews, die de high-level werkwijze beschrijft en aangeeft hoe je tijdens het project bewijs levert voor de verschillende beoordelingscriteria.
De checkpoints gelden hierbij als vereisten en dus knock-outs voor het teamcijfer. De beoordelingsniveaus zijn beperkt tot onderstaande 5; dit ter beoordeling aan de begeleiders en opdrachtgever. Als één punt onvoldoende is, is het gehele eindcijfer een onvoldoende (e.g. het zijn knock-outs). Als er Twijfel is kun je het compenseren met Goed of Uitmuntend op andere beoordelingscriteria, om totaal boven de minimale 5.5 te komen om het project succesvol af te sluiten.
- O=knOck-out, 2.0, niet gedaan of niet aangetoond
- T=Tsja (Twijfelachtig), 4.0, twijfel of serieuze tekortkomingen
- V=Pass (Voldoende), 6.0, punt voldaan
- G=Goed , 8.0, met veel kwaliteit of kwantiteit en afgestemd met begeleiders/opdrachtgever
- U=Uitmuntend 10.0, je ging 'above and beyond' de vereisten
Self assessment
Bij je oplevering (tussentijds en eind) hoort ook een zelf als team samen opgesteld self assessment met het CDMM model (net als bij het beroepsproduct aan het einde van de course). Houdt vanaf het begin hiermee ook al in de gaten of je voldoende variatie in werkzaamheden hebt en op je 'DevOps volwassenheid'. Het CDMM is hierbij niet alleen het beoordelingsmodel, er zijn ook concretere eisen opgesteld onder de volgende vijf beoordelingscriteria A tot en met E hieronder.
A. Technologie
- ⛪ Design & Architecture
- 📈 Information & Reporting
- Je werkt met de technologiestack zoals de klant die gebruikt (of hebt een goede onderbouwing waarom je daar van afgeweken bent)
- De applicatie is opgedeeld in (Docker) containers en draait in een Kubernetes (cluster)
- Je hebt monitoring ingericht die de beschikbaarheid van de (onderdelen van de) applicatie inzichtelijk maakt
B. Way of Working
- 🧑🤝🧑 Culture & Organization
- Je hebt nauw contact met opdrachtgever/Product Owner (meer malen per week)
-
Je werkt volgens Scrum met een- of tweeweekse sprints, Scrum ceremonies en wekelijks contactmomenten
- Elke week een Review met demo
- met werkende software, uiterlijk week 2 à 3
- met monitoring, uiterlijk week 3 of 4
- Opleveren: Een overzicht van verbeterpunten uit de retrospectives (minimaal 1, liever meer, zinvolle procesverbetering per week en het resultaat van de verbetering)
- Elke week een Review met demo
-
In week 1 oriënteer je je op het project en legt je werkwijze als team vast (binnen gegeven kaders project)
- Een Definition of Ready
- Opleveren: Definition of Ready
-
Je week 1 maak je ook een User Story Map
- User story map en overige zaken
- Verdeeld in zinvolle slices die je gebruikt in de communicatie met de opdrachtgever en bijhoudt gedurende het project.
- High level user stories met prioritering en waar mogelijk onderliggende acceptatiecriteria, persona's e.d.
- Initiele backlog
- Opleveren: Gevulde backlog, User story map, elke week een foto of afbeelding van de bijgewerkte map
-
Je past code reviews toe
- Je hebt een systeem van pull requests ingericht met reviewopmerkingen in Azure DevOps (of ander gekozen Code management systeem)
- Bij persoonlijke beoordelingen (na 4 en 8 weken) tenminste 1 review laten zien van jouw over andermans code.
C. Build en Deployment
- 🏗️ Build & Deploy
- Je hebt na sprint 1 een 'productie omgeving' en werkt deze daarna bij
- Je hebt na sprint 2 à 3 werkende software in productie staan en bouwt daar vervolgens op voort
- Je denkt na over meerdere omgevingen, dus naast productie bv. een develop, QA of staging omgeving
- Je levert vanaf sprint 5 à 6 aantoonbaar vaker op dan enkel einde sprint, middels automatische uitrol
- Je hebt automatische tests in een build pipeline
D. Documentatie
- ⛪ Design & Architecture
- Je hebt je product gedocumenteerd met:
- Een goede README voor developers (volgens Microsoft richtlijnen)
- C4-diagram: minstens een Context en Container diagram, inlcusief toelichting op elk, als documentatie van je Software Architectuur
- Architectuurbeslissingen in de vorm van ADR’s
- Specificaties in de vorm van given-when-then’s (Gherkin)
-
Je hebt zelf een beeld van je DevOps volwassenheid via een self assessment van het CDDM
- met een realistisch deelcijfer/niveau op elk van de 5 categorieën
- en per cijfer/categorie ook eigen toelichting* over hoe je 'checkpunten' hebt gehaald en waar dit zichtbaar is in eigen werk (of (net) niet hebt behaald (wellicht met goede reden),
- Opleveren: Een overzicht van de (runtime) omgevingen, hoe ze zijn ingericht, en beheerd worden (incl. de koppeling met versiebeheer).
E. Soft skills
- 🧑🤝🧑 Culture & Organization
- Je werkt prettig samen met de opdrachtgever en geeft een professionele indruk
- Je werkt goed samen als team en creëert een goede werksfeer
- Je valt de opdrachtgever niet lastig met technische details, maar kunt issues en werkzaamheden vertalen naar bedrijfstermen
- Je schermt als team de opdrachtgever af van kleine afwijkingen van de planning
- Maar bij grote(re) tegenslagen communiceer je tijdig, zodat opdrachtgever kan meedenken over alternatieve richtingen
- Bij extra tijd en evt. opraken van werk denk je pro actief mee met business over mogelijk waardevolle features
Extra details 2025 Sprints
Deze sectie beschrijft de high-level Way of Working tijdens het project: hoe je door middel van gestructureerde reviews bewijs levert voor de beoordelingscriteria A t/m E hierboven.
Tijdens het project vinden er 4 Tech Reviews en 4 Sprint Reviews plaats. Deze reviews zijn gekoppeld aan de beoordelingscriteria A t/m E en helpen je om je DevOps-volwassenheid te tonen en te ontwikkelen.
I. Tech Reviews
Tech reviews vinden plaats om de week (eind week 1, 3, 5, 7) en richten zich op technische DevOps-vaardigheden. Iedere Tech Review heeft een kernopdracht en een groeidoel. Lever bewijs aan in documentatie, pipeline, K8S config of dashboards (alles in repo).
| Moment | Week | Tech review – kernopdracht | Groeidoel / verdieping |
|---|---|---|---|
| Tech review 1 | Week 1 | App basis, pipeline ingericht en productieomgeving -> GitOps-werkwijze aantonen; CI-pipeline met build/test/artefact; minimaal één front-end en back-end op Kubernetes | Codekwaliteit borgen: linting en/of statische analyse, kwaliteitsplatform naar keuze |
| Tech review 2 | Week 3 | Staging+productie, CD werkt+BODA Container registry gebruiken; pipeline bouwt image en geautomatiseerde deploy; parametrisatie voor meerdere omgevingen | Versiebeheer op images (semver/auto-tagging) |
| Tech review 3 | Week 5 | Performance- en/of loadtesten -> Met K6 o.i.d.; realistisch end-to-end scenario uit domein | Tijdelijke testomgeving automatisch opzetten/afbreken; pipeline-stap voor perftest |
| Tech review 4 | Week 7 | Observability & Resilience -> Verplicht: Observability/monitoring-stack (combineer applicatie- en platform-metrics) én Chaos Engineering (testen van fouttolerantie en resilience). Optioneel aanvullend: Onderzoeken én toepassen van specifieke K8S/CNCF tech of andere relevante technologieën die nuttig is binnen het project. Denk aan RabbitMQ clustering, custom applicatie specifieke metrics en/of gebruik ELK i.p.v. Grafana of andere Observability tools, sharding/duplication of database server (readonly copy e.d.), MCPS omgeving features, Azure DevOps features, security: verder afsluiten/hardening van productie omgeving, risico gebaseerde handmatige tests, duidelijker onderscheid maken tussen health check en liveness endpoints in K8S met realistische invulling, of andere project-specifieke tech) | Per teamlid kan er ook een persoonlijke verdieping zijn in een specifieke technologie die relevant is voor het project; alternatieve observability (bijv. logaggregatie of tracing); healthchecks en schaalgedrag aantonen |
Video: Tech Review 3 – loadtesten (NotebookLM)
Korte toelichting (punten om te behandelen in TR3):
- Welk type loadtest heb je? Welke gebruikersscenario’s test je?
- Aantal gelijktijdige gebruikers dat je applicatie minimaal/maximaal aankan.
- Bottlenecks: waar zit de beperking? Hoe meet je dat? Wat is de follow-up?
- Testbeperkingen en aanvullende nuttige tests.
- Vooruitblik TR4: welke tech/onderzoek per teamlid?
Belangrijk: Dit is voorlopige planning die een goed handvat geeft, maar tech moet zoveel mogelijk in dienst staan van de opdracht (demand pull over technology push). Buiten het vaste kader van 'MSA in K8S op Azure' kan deze planning tijdens het project op basis van input van opdrachtgever/InfoSupport nog bijgewerkt worden.
Koppeling met beoordelingscriteria:
- A. Technologie: Bewijs per tech review van GitOps-werkwijze, CI/CD-pipelines, container registry, deployment tooling, monitoring/performance tooling, chaos engineering, en/of specifieke CNCF/project-relevante technologieën (tooling naar keuze)
- C. Build en Deployment: CI/CD met build, test, artefact push, geautomatiseerde deploys, GitOps-triggers, performance-teststage en tijdelijke omgevingen
- D. Documentatie: Dashboards, testresultaten en review-logboek per sprint (opdracht + evt. groeidoelen)
Opmerking: De tooling is naar keuze; de focus ligt op het aantonen van de DevOps-principes en werkwijzen, niet op specifieke tools. Overleg met je begeleiders als je alternatieve tooling wilt gebruiken.
II. Sprint Reviews
Sprint reviews vinden plaats aan het einde van iedere sprint (onderwijsweek 2, 4, 6, en 8) bij de opdrachtgever/Product Owner. In tegenstelling tot Tech reviews hebben Sprint reviews geen vaste indeling van onderwerpen, maar richten zich op de functionele voortgang en afstemming met de opdrachtgever.
In de andere week (niet de sprint review week) is er een Teams video call met de opdrachtgever voor het stellen van vragen en korte afstemming.
Koppeling met beoordelingscriteria:
- B. Way of Working: Scrum-ritme over 4 sprints met planning, review, retro en statusupdates aantoonbaar (artefacts, acties, groeiopdrachten). User story map bijhouden en refinement van user stories.
- E. Soft skills: Samenwerking met PO, InfoSupport en HAN; actieve voorbereiding reviews, reflectie op groeidoelen en professionele communicatie. Vertalen van technische zaken naar bedrijfstermen.
III. Aandachtspunten per sprint
Per sprint ben je met onder andere onderstaande zaken bezig. Deze aandachtspunten zijn een hulpmiddel, kijk zelf naar de acceptatiecriteria/werkwijze A t/m E hierboven. Qua tonen van gemaakt werk/bespreken aandachtspunten tijdens de Tech review vs. Sprint review moet je hier zelf goed over nadenken. Wie is de doelgroep. Het indelen van de punten uit het volgende lijstje hieronder hoort bij beoordelingscriterium E3.
-
Sprint 1:
- User Story Map en Domein Model opstellen
- C4 Context model
- Opzet applicatie met front-end en back-end en message bus
- Evt. wireframes + API design
- CI/CD pipeline opzetten
- Individuele verantwoording (tenminste template hebben staan)
- Template van CDMM staat er en vindbaar vanuit root README
- Opzet ADR's
-
Sprint 2:
- C4 Container en meerdere Component diagrammen
- Pipeline verbeteren (beter CD-stuk)
- Evt. linting toevoegen + styleguides
- Overzicht van omgevingen opstellen (zie D3)
- Evt. code diagrammen: class diagrams, data model/database schema (waar relevant voor je domein)
- Refinement van user stories in acceptatiecriteria
- Afstemming van user stories op basis van feedback van opdrachtgever/PO en projectbegeleiders
- Individuele verantwoording (template teksten weg, 1e helft van bullets per kopje, max 2 van 9 kopjes nog leeg)
- CDMM voor ca. helft ingevuld en idee van hoe in volgende sprints naar Voldoende of hoger
- Retrospective notulen/uitkomsten
-
Sprint 3:
- Alles verder uitbreiden
- Documentatie van pipeline maken
- Meer ADR's toevoegen
- Acceptatiecriteria verder uitwerken
- README's inrichten
- C4-documentatie bijwerken
- Evt. code diagrammen bijwerken/uitbreiden (class diagrams, data model, sequence diagrams waar relevant)
- Performance/load tests implementeren (K6 of vergelijkbaar) met realistische end-to-end scenario's
- Evt. UML sequence diagrams van kritieke flows en/of load test scenario's
- Overzicht van omgevingen bijwerken
- Bij begeleiders voorstel doen of uitvragen nieuw te gebruiken technologieën in Sprint 4 (per teamlid één technologie)
- Refinement van user stories
- Individuele verantwoording bijgewerkt
- Retrospective notulen/uitkomsten
-
Sprint 4:
- Alles verder uitbreiden en afronden
- Documentatie compleet maken (pipeline, ADR's, README's)
- Meer ADR's toevoegen voor gemaakte keuzes
- Onderzoek en implementatie van gekozen technologieën (per teamlid één: monitoring, chaos engineering, of andere relevante tech die bijdraagt aan het project)
- Evt. BDD/Gherkin tests:
.featurebestanden met acceptatietests (Cucumber, SpecFlow, Req'n'Roll o.i.d.) - Acceptatiecriteria finaliseren
- C4-documentatie compleet maken
- Evt. code diagrammen compleet maken (class diagrams, data model, sequence diagrams waar relevant)
- Performance/load test resultaten en analyse documenteren
- Overzicht van omgevingen compleet maken
- Individuele verantwoording afgerond
- Retrospective notulen/uitkomsten
Toelichting
Merk op dat de punten onder de beoordelingscriteria A. Technologie, B. Way of Working, C. Build en Deployment, D. Documentatie en E. Soft skills grofweg knock-outs zijn van het minimale verwachte werk, de te gebruiken werkwijze en de op te leveren zaken (deliverables).
De Tech Reviews en Sprint Reviews hierboven geven aan hoe je tijdens het project gestructureerd bewijs levert voor deze criteria. Voor het komen tot een concreet cijfer kijken begeleiders naar de hoeveelheid (kwantieit) en de kwaliteit van met team gemaakte product, en ook omgang en goed hanteren van Agile proces en samenwerken als team. Bedenk hierbij dat het gemaakte product een DevOps product is, dus focus niet alleen op code en functionaliteit, maar toon DevOps volwassenheid. Andersom, focus je niet alleen op pipelines, build bakeries etc. maar maak ook een product, want zonder features en requirements heb je geen DevOps nodig.
Retrospective notulen/uitkomsten: Bij elke sprint hoort een retrospective waarbij je notulen/uitkomsten vastlegt. Wissel hierbij bijvoorbeeld af tussen sterke en zwakke punten van het team (bijv. met SWOT of Sails methode) en individuele tips en tops op voor de volgende retro. Of het liefst altijd beiden natuurlijk, maar bepaal zelf wat het meest nuttig is en niet alleen overhead geeft.
Hoe naar ruim voldoende, goed, of hoger?
Voor het aantonen van hogere 'Devops volwassenheid' (en dus eindcijfer boven een 6) moet je — net als in de coursefase — het CDMM er weer bij pakken en naast de Basis, Beginner en Gemiddeld ook naar de hogere checkpunten kijken, Gevorderd en Expert. De XX-30X en XX-40X checkpoints en jezelf hiermee assessen. Hou het niet bij alleen afvinken, maar beargumenteer per checkpunt onder de verschillende niveaus van de beoordelingscriteria waarom je het wel of niet of deels hebt. Om je beschrijving enigszins kort te houden helpt het wel om ook te linken naar concreet werk in je code management systeem. Dus neem een link op maar denk ook aan een goede linktekst vergelijkbaar met hoe je dit in individuele fact sheet doet.
Zeker bij de hogere punten XX-30X en XX-40X moet je — behalve zeggen DAT je het doet — ook uitleggen/beargumenteren HOE je hier dan aan voldoet. Voor het afvinken van deze criteria moet je ook 'bewust bekwaam' zijn en concreet aangeven welk werk jij en je team hebben gedaan. Anders kan een beoordelaar aanvoeren dat het een 'toevalstreffer is'. Ook is het zelden voldoende om te zeggen 'Dit checkpunt hebben we omdat we Tool X gebruiken'. Bijvoorbeeld 'Cross Silo analysis voldoen we aan omdat we Prometheus en Grafana gebruiken'. Geef of beschrijf in plaats daarvan een concreet scenario van een 'cross silo analysis' met deze tool. Lees ook de toelichting bij verschillende checkpoints in de 'lijst van devops concepten'.
Een goede redenering en argumentatie is dus nodig voor een goed cijfer. Je kunt ook een checkpunt afvinken, maar aangeven dat je er deels nog niet aan voldoet, maar wel een oplossingsrichting geven. Dus maai liever het gras voor de voeten weg van mogelijke kritiek of vragen door de beoordelaar, dan er over te zwijgen.
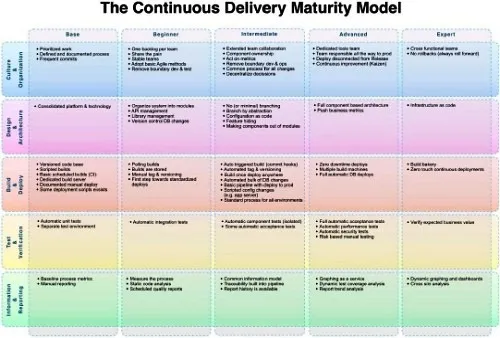
Figuur 1: Het Continuous Delivery Maturity Model van infoq.com
Merk overigens op dat het CDMM van InfoQ is, iets anders is dan InfoSupport. Als je zelf overigens een ander moderner, simpeler, passender of anderszins beter maturity model weten of vinden dan het CDMM uit de coursefase, dan kun je deze in overleg met de begeleiders ook gebruiken voor dit self assessment! Plumlogix' model is wat simpel en enkel 'cretologie' zonder onderscheid tussen niveaus, dus dit moet je allemaal zelf definiëren en beargumenteren. Het Nederlandse NISI heeft nog een recenter maturity model, CD3M genaamd, maar de term 'Continuous Intelligence' hierin is wellicht nog wat vaag. Het CDMM van InfoQ (feb 2013) is nog van (net) voor de tijd dat veel huidige DevOps tools ontstonden (bijvoorbeeld Docker (1.0 in maart 2013 uit dotCloud) of Kubernetes (2014, open-source versie onder de naam 'Borg') bestonden of gemeengoed waren). Zelfs microservices werden net iets later pas hot. Maar het CDMM bevatte conceptueel al wel heel veel zaken zoals een 'Build bakery' (dit idee zit in de base images uit Docker) en 'microservices' zijn de 'componenten' uit OA205: 'Modules omzetten naar componenten' (e.g. van modulaire monolith naar microservices, waar OA-101 'Systeem opsplitsen in modules' nog te zien is als de stap is van een niet-modulaire monoliet naar een wel-modulaire) monoliet.
Figuur 2: Een alternatief DevOps Maturity Model van plumlogix.com
Bronnen
- Porras, A. (2025, 23 oktober). How to Perform Load Testing on a Distributed System with k6. Geraadpleegd op 11-12-2025 via https://blog.4geeks.io/how-to-perform-load-testing-on-a-distributed-system-with-k6/
Domein Model, glossary naar DDD, Design thinking en meer
| Datum | Wijziging |
|---|---|
| 06-01-2026 | Quiz toegevoegd, Double Diamond sectie uitgebreid met ICT-documenten per diamond, link naar Design Council pagina en Jonathan Ball video toegevoegd, Einstein plaatje toegevoegd, figuren hernummerd. |
| 18-11-2025 | Uitbreiding met subset relatie tussen probleem- en oplossingsdomein, privacy by design en koppeling aan DDD/Design Thinking. Toevoeging van leeswijzer, sectienummers, opdrachten voor eigen casus, korte uitwijding over ethische aspecten en uitleg over doelgroep (niet-technische stakeholders). |
Deze workshop behandelt het opstellen van een domein model bij de start van een software development project. Het domein model past goed bij methoden als Domain-Driven Design (DDD), maar sluit ook aan bij Design Thinking, die bv. ook Media Design professionals gebruiken. Beide benadrukken het belang van eerst een probleem goed begrijpen voordat je naar oplossingen kijkt. Je leert het onderscheid tussen probleemdomein en oplossingsdomein, en hoe je een domein model kunt vertalen naar software-architectuur. Tussendoor komt ook ethische overweging aan bod: niet alles wat je kunt opslaan, moet je ook opslaan (privacy-by-design).

We behandelen een uitgebreide casus over een bibliotheeksysteem met verschillende varianten van domeinmodellen als voorbeeld. Belangrijk: Pas deze theorie toe op je eigen projectcasus. Sectie 1 geeft een inleiding over het domein model en de glossary, sectie 2 behandelt het conceptuele onderscheid tussen probleem- en oplossingsdomein, sectie 3 gaat over datatypes en terminologie, sectie 4 behandelt subdomeinen en bounded contexts, sectie 5 bevat concrete voorbeelden van domeinmodellen voor de bibliotheek casus, sectie 6 geeft kwaliteitscriteria in de vorm van een checklist, en sectie 7 biedt verdieping voor wie verder wil lezen.
"If I had an hour to solve a problem, I'd spend 55 minutes thinking about the problem and five minutes thinking about solutions." — Albert Einstein
1. Inleiding
Bij de start van het project (kick-off en eerste sprint) is het belangrijk om het domein goed te begrijpen. Daarom wordt er in de eerste sprint een domein model opgesteld, samen met een glossary (woordenlijst).
Een domein model is een visuele representatie van de belangrijkste concepten, entiteiten en hun relaties binnen het probleemdomein. Het is primair een communicatiemiddel, niet een tussenstap in het ontwerp. Larman (2004) noemt het ook wel een "visual dictionary". Het helpt het team om een gedeeld begrip te ontwikkelen van de businesslogica. Na validatie met niet-technische stakeholders vormt het de basis voor de software-architectuur. De glossary is een tabel met belangrijke termen uit het domein en hun uitleg, wat helpt om ambiguïteit te voorkomen en een gemeenschappelijke taal te ontwikkelen.
Belangrijk: Domeinmodellen moeten klein en overzichtelijk blijven. In Larman's boek staan alleen maar kleine diagrammen - dit is bewust, niet omdat Larman niet kan modelleren. Modellen zijn ook voor mensen met beperkte (cognitieve) capaciteit.
Als het model te groot wordt, kun je het opsplitsen in subdomeinen volgens Domain-Driven Design (DDD) principes. Studenten die DDD patterns zoals Aggregate hebben gehad, kunnen hier ook naar vooruit denken bij het opsplitsen in subdomeinen. Een domein model ter grootte van een A4-vel is de maximale grootte om te lezen en te bespreken.
Figuur 1: Domain-Driven Design (DDD) Strategic Design Patterns - Ubiquitous Language, Bounded Context en Context Mapping (Lambrych, 2024).
Zie ook sectie 4 voor uitleg over subdomeinen en bounded contexts, en criterium DM-6 voor meer informatie over Context Mapping.
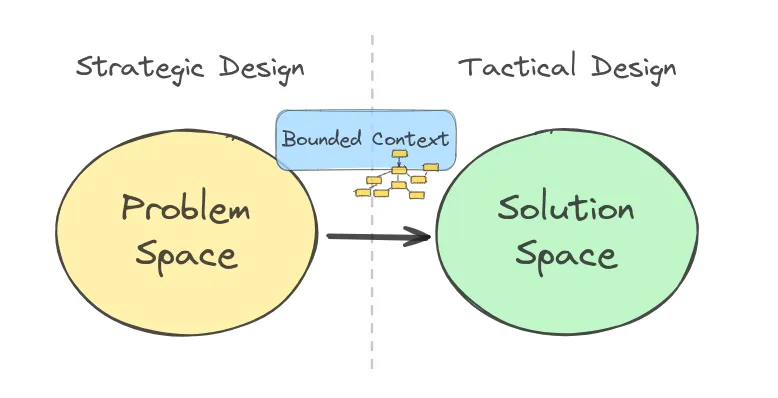
Let op: Het domein model bevindt zich in het probleemdomein, niet in het oplossingsdomein. Het gaat om de concepten en relaties in de business/wereld, niet om software classes of models in de code. Het domein model helpt om het probleem te begrijpen voordat je naar de oplossing (software) kijkt. Uiteraard is er wel een relatie tussen het probleemdomein en het oplossingsdomein te maken. In de Realisatie fase kun je nog wel een domain layer met models/entities maken en een DB datamodel opstellen (bijvoorbeeld in je Software Guidebook), waarin stukken uit het domein model terug te vinden zijn.
2. Probleem- vs. oplossingsdomein - Subset relatie
Het oplossingsdomein is vaak een subset van het probleemdomein (zie verzamelingenleer: een subset is een deelverzameling waarbij alle elementen van de subset ook in de oorspronkelijke verzameling zitten). Dit betekent dat niet alle concepten en attributen uit het probleemdomein automatisch in het oplossingsdomein terechtkomen.
2.1 Voorbeeld: Klant entiteit
Bijvoorbeeld, een Klant in het probleemdomein heeft mogelijk veel meer eigenschappen dan nodig zijn voor de software:
- Naam en klantnummer → wel nodig in oplossingsdomein
- Favoriet boekentype (bijvoorbeeld "science fiction" of "thriller") → mogelijk niet nodig voor MVP, maar kan later worden toegevoegd voor personalisatie
- Speelcomputer type (bijvoorbeeld "Nintendo", "PlayStation" of "PC") → bepaalt welk type games de klant typisch leent, maar mogelijk niet nodig voor eerste versie
- Geslacht (hij/zij/anders) → niet nodig voor functionaliteit, en vanuit privacy by design principe slaan we dit niet op tenzij er een goede reden is (bijvoorbeeld voor gepersonaliseerde aanhef in brieven/e-mails bij overschreden leenlimiet)
Deze "kandidaatvelden" kunnen in latere sprints/releases worden toegevoegd via extra features, maar worden bewust weggelaten in de eerste versie om het model simpel te houden en privacy te beschermen.
2.2 Ethische overwegingen: wenselijkheid van data opslag
Hoewel met de uitbreiding van opslagcapaciteit jarenlang ook veelal zoveel mogelijk data in applicaties lieten opslaan, met het motto "baat het niet dan schaadt het niet" of "We zien later wel wat we met de data doen" is dit sinds een aantal jaar aan het veranderen. Bij het kiezen wat je wel of niet implementeert, speelt niet alleen technische haalbaarheid of functionele noodzaak een rol, maar ook ethische overwegingen. Dit sluit aan bij de HAN speerpunten slim, schoon en sociaal:
- Slim: Technisch gezien kun je veel data verzamelen en analyseren, maar dat betekent niet dat je dat ook moet doen
- Schoon: Door alleen noodzakelijke data op te slaan, voorkom je onnodige complexiteit en potentieel misbruik
- Sociaal: Het beschermen van privacy en voorkomen van discriminatie en profilering is een maatschappelijke verantwoordelijkheid
Dus niet alles wat je kunt meten, moet je ook willen opslaan. Denk kritisch na over de gevolgen van het verzamelen en gebruiken van data, vooral wanneer dit kan leiden tot profilering of discriminatie van gebruikers.
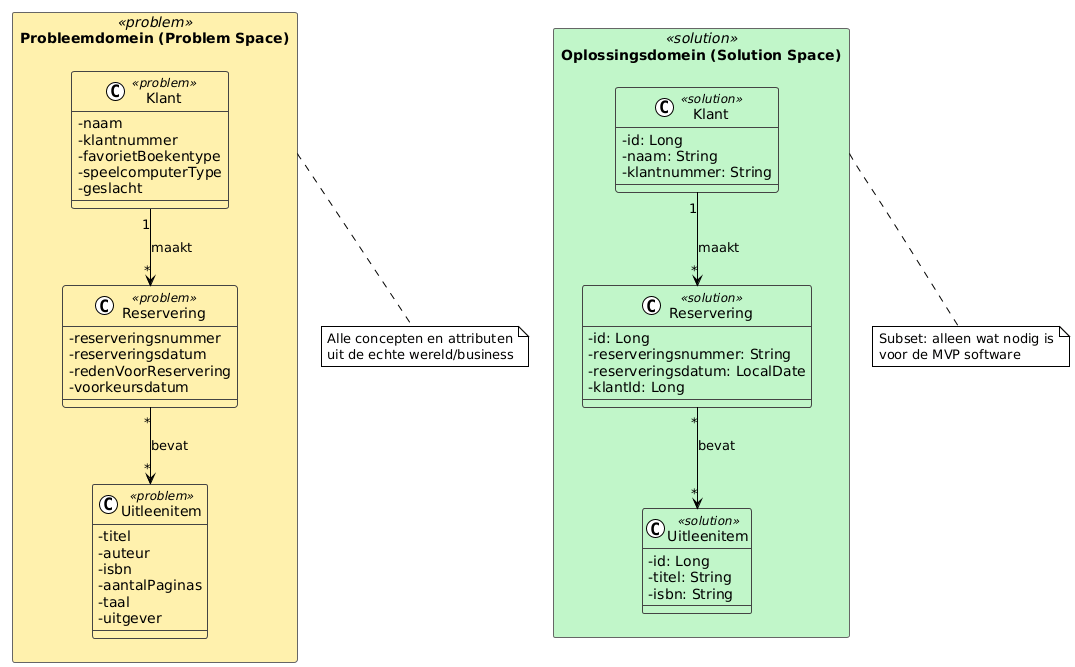
Figuur 2: Probleemdomein vs Oplossingsdomein — het oplossingsdomein bevat een subset van de concepten uit het probleemdomein (Lambrych, 2024).
NB: We hebben de inkleuring in figuur 2 aangepast in lijn met Figuur 1: geel voor probleemdomein, groen voor oplossingsdomein.
📋 PlantUML Code - Probleemdomein vs Oplossingsdomein
@startuml
!theme plain
skinparam classAttributeIconSize 0
skinparam packageStyle rectangle
' Kleuren uit Lambrych figuur
skinparam package {
BackgroundColor<<problem>> #FFF1AD
BackgroundColor<<solution>> #C1F6C9
BorderColor #666666
}
skinparam class {
BackgroundColor<<problem>> #FFF1AD
BackgroundColor<<solution>> #C1F6C9
BorderColor #444444
}
package "Bibliotheek" <<problem>> {
class Klant <<problem>> {
- naam
- klantnummer
- favorietBoekentype
- speelcomputerType
- geslacht
}
class Uitleenitem <<problem>> {
- titel
- auteur
- isbn
- aantalPaginas
- taal
- uitgever
}
class Reservering <<problem>> {
- reserveringsnummer
- reserveringsdatum
- redenVoorReservering
- voorkeursdatum
}
Klant "1" --> "*" Reservering : maakt
Reservering "*" --> "*" Uitleenitem : bevat
}
package "Bibliotheek" <<solution>> {
class Klant <<solution>> {
- id: Long
- naam: String
- klantnummer: String
}
class Uitleenitem <<solution>> {
- id: Long
- titel: String
- isbn: String
}
class Reservering <<solution>> {
- id: Long
- reserveringsnummer: String
- reserveringsdatum: LocalDate
- klantId: Long
}
Klant "1" --> "*" Reservering : maakt
Reservering "*" --> "*" Uitleenitem : bevat
}
note bottom of "Bibliotheek"
Links: Probleemdomein - alle concepten
uit de echte wereld/business
Rechts: Oplossingsdomein - subset,
alleen wat nodig is voor de MVP
end note
@enduml
Glossary - Klant: Probleemdomein vs. Oplossingsdomein
| Attribuut | Voorbeeld | In MVP? | Toelichting |
|---|---|---|---|
| naam | "Jan de Vries" | ✅ Ja | Nodig voor identificatie van de klant |
| klantnummer | "BIB-2024-00142" | ✅ Ja | Unieke identificatie, nodig voor uitleenadministratie |
| favorietBoekentype | "science fiction", "thriller" | ❌ Nee | Niet nodig voor MVP, kan later worden toegevoegd voor personalisatie |
| speelcomputerType | "Nintendo Switch", "PlayStation 5" | ❌ Nee | Bepaalt welk type games klant typisch leent, maar niet nodig voor eerste versie |
| geslacht | "man", "vrouw", "anders" | ⚠️ Privacy | Niet nodig voor functionaliteit; privacy by design — alleen opslaan indien nodig voor gepersonaliseerde aanhef in communicatie |
Tabel: Vergelijking attributen Klant in probleemdomein vs. oplossingsdomein. Attributen met ✅ komen in de MVP, attributen met ❌ zijn kandidaten voor latere releases, en ⚠️ geeft privacy-gevoelige attributen aan.
Opdracht: Identificeer voor je eigen projectcasus minimaal drie entiteiten uit het probleemdomein. Voor elke entiteit, maak een lijst van attributen die:
- Wel nodig zijn in het oplossingsdomein (voor de MVP)
- Mogelijk niet nodig zijn voor de MVP, maar later kunnen worden toegevoegd
- Ethisch niet wenselijk zijn om op te slaan (bijvoorbeeld vanwege privacy by design)
2.3 Design Thinking en de Double Diamond
Hoewel beginnende ICT'ers het belang van 'stilstaan bij het probleem' op basis van een quote van Einstein wellicht wel inzien (Figuur X), is in de praktijk toch de neiging om snel de code in te duiken, omdat hier ook nog allerlei technische uitdagingen en onbekendheden zijn. En ook omdat het probleemdomein heel simpel is. Een simpele opdracht als het 'FizzBuzz' drankspelletje, priemgetallen berekenen of de oppervlakte van verschillende figuren als een vierkant en driehoek berekenen, of een bekende casus in het onderwijs zoals een onderwijsadministratie met Student-Docent-Course-Cijfer e.d. Kortom 'academische problemen' of wellicht zelfs 'speelgoed domeinen' te noemen. In de praktijk zijn dit allemaal opgeloste problemen en is er vooral geld te verdienen als ICT met applicaties in complexe domeinen zoals het Verzekeringsdomein, of 'netbeheer' van electrische netwerken met heel veel business of organisatie logica.
Om nog even extra stil te staan is een mooie model dat vanDouble Diamond model uit Design Thinking. De kern hierin is een duidelijk onderscheid tussen probleemdomein en oplossingsdomein komt overeen met het
Dit model beschrijft twee fasen van divergeren (verbreden) en convergeren (vernauwen):
-
Probleemdomein (Problem Space) — de eerste diamond:
- Discover (divergeren): Verken het probleem breed, verzamel informatie
- Define (convergeren): Definieer het kernprobleem
- ICT-documenten: Domein model, glossary, requirements, SRS/user stories, (high level) use case model, of in Software Guidebook: Constraints, Context en C4 Context diagram
-
Oplossingsdomein (Solution Space) — de tweede diamond:
- Develop (divergeren): Verzin verschillende oplossingen
- Deliver (convergeren): Kies en implementeer de beste oplossing
- ICT-documenten: Software Architecture Document (SAD), Software Design Document (SDD), fully dressed use cases, of in Software Guidebook: Functional Overview, Code, Data, Deployment etc.
Let op: Er zijn verschillende varianten van design thinking. De Double Diamond gebruikt 4 fasen (Discover, Define, Develop, Deliver), terwijl andere modellen zoals die van Stanford d.school 5 fasen gebruiken: Empathize, Define, Ideate, Prototype en Test. Beide modellen hebben hetzelfde doel: eerst het probleem goed begrijpen voordat je naar oplossingen kijkt.
Tip: Zie voor meer informatie de officiële Double Diamond pagina van de Design Council (z.d.), waar ook een korte video staat waarin Jonathan Ball (een van de oorspronkelijke bedenkers) het model uitlegt.
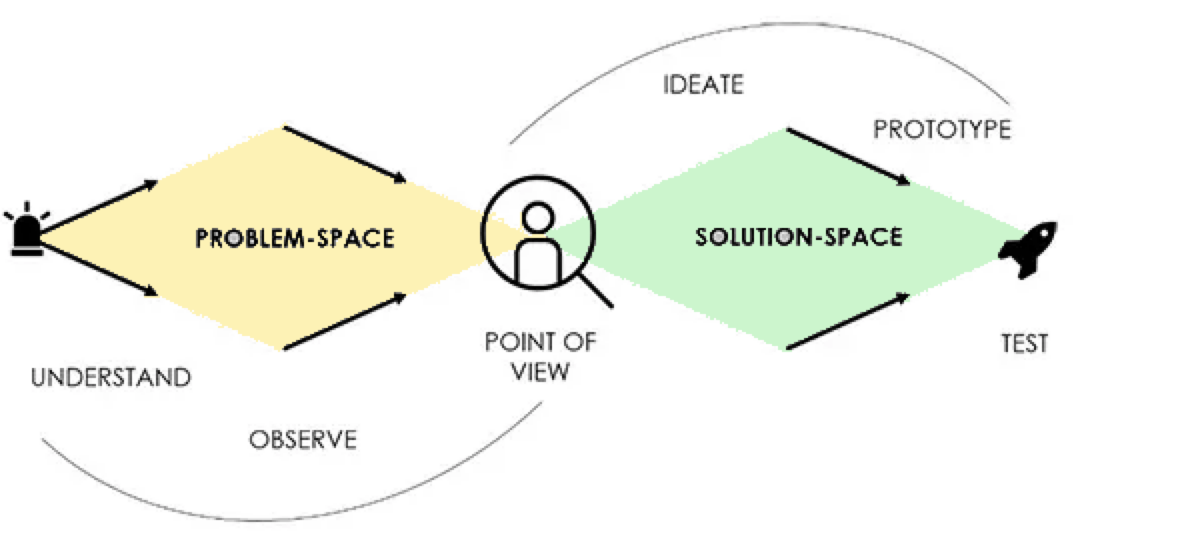
Figuur 3: Double Diamond model - Probleemdomein (Problem Space) en Oplossingsdomein (Solution Space) (Gupta, 2019)
De take away van dit verhaal is dat je bij het maken van software een goede balans moet vinden tussen het probleem voldoende goed begrijpen (zodat je niet een ander probleem oplost dan de opdrachtgever bedoelde) en pragmatisch een zo simpel mogelijke oplossing realiseren (zodat je niet strandt in analysis paralysis of accidental complexity).
"Everything should be made as simple as it can be, but not simpler." — Albert Einstein
Opdracht: Verzin voor deze casus nog enkele velden uit het probleemgebied die wel in het probleemdomein voorkomen maar niet in het oplossingsdomein.
💡 Tip: Denk eerst zelf na voordat je de antwoorden bekijkt! Sleep met je muis over het blok hieronder (of tik en houd ingedrukt op mobiel) om de voorbeelden te zien.
Voorbeelden voor verschillende entiteiten
Klant:
- Leeftijd → niet nodig voor MVP, mogelijk later voor leeftijdsrestricties bij games
- Postcode → niet nodig voor MVP, mogelijk later voor statistieken of lokale promoties
- Email voorkeur (wel/niet nieuwsbrief) → niet nodig voor MVP, mogelijk later voor marketing
- Aantal kinderen → bepaalt mogelijk welke boeken klant leent, maar niet nodig voor eerste versie
Uitleenitem:
- BoekBeschadigScore (per klant) → een bibliotheek zou kunnen denken aan het bijhouden van een score per klant van hoeveel beschadigde boeken hij/zij inlevert, om bij inleveren meer te controleren. Dit is echter een vorm van profilering die kan leiden tot verkeerde conclusies en discriminatie (denk aan de misstanden bij de toeslagaffaire bij de Nederlandse belastingdienst). Zelfs al zou je dit technisch kunnen meten, is het ethisch niet wenselijk om dit te implementeren. Dit illustreert dat niet alles wat je kunt meten ook moet worden opgeslagen.
- Aantal pagina's → fysieke eigenschap die bestaat, maar niet nodig voor uitleenfunctionaliteit
- Taal (Nederlands, Engels, etc.) → bestaat in echte wereld, maar mogelijk niet nodig voor eerste versie
- Uitgever → bestaat in echte wereld, maar niet nodig voor uitleenfunctionaliteit
Exemplaar:
- Locatie in bibliotheek (bijv. "Rij 3, Plank B") → bestaat fysiek, maar mogelijk niet nodig voor eerste versie als alle exemplaren op één plek staan
- Aanschafprijs → financieel gegeven dat bestaat, maar niet nodig voor uitleenfunctionaliteit
- Laatste schoonmaakdatum → onderhoudsinformatie die bestaat, maar niet nodig voor MVP
Reservering:
- Reden voor reservering (bijv. "voor schoolproject") → bestaat mogelijk in gesprekken, maar niet nodig voor MVP
- Voorkeursdatum (wanneer klant het graag wil hebben) → bestaat mogelijk in gesprekken, maar niet nodig voor eerste versie
3. Datatypes in domeinmodellen
Datatypes opgeven bij de attributen (zoals String, Date, etc.) zijn optioneel in een domeinmodel. Op dit detailniveau hoef je nu nog niet na te denken, deze denk je later uit en voeg je toe).
Opdracht: Voor je eigen projectcasus: kies één entiteit uit je domein model en bepaal of je datatypes wilt toevoegen. Bedenk ook of er concepten zijn waar je twijfelt of het een aparte entiteit of attribuut (van een entiteit) moet zijn. Leg uit waarom.
Opmerking: Als je twijfelt of iets een object (klasse/entiteit) moet worden of een attribuut, kies dan bij twijfel voor een klasse/entiteit. Dit maakt het model expliciet en voorkomt dat je later belangrijke concepten mist.
4. Subdomein vs. Bounded Context vs. Microservice
Volgens Evans (2003):
- Een subdomein is een deel van het probleemdomein (bijvoorbeeld "Orderbeheer" of "Voorraadbeheer").
- Een bounded context is een conceptueel/architecturaal concept in het oplossingsdomein - het is een context waarin een bepaald domeinmodel geldig is. Een bounded context kan worden geïmplementeerd als een microservice, maar dat hoeft niet (het kan ook een module in een monoliet zijn, of meerdere microservices).
- Een microservice is een deployment/technisch concept - een zelfstandig deploybare service. Een bounded context kan je implementeren als één of meerdere microservices.
De relatie tussen subdomeinen en bounded contexts is dat een subdomein vaak wordt gemapped naar een bounded context in de oplossing. Maar dit is niet per se een 1-op-1 relatie; één bounded context kan meerdere subdomeinen bevatten, of één subdomein kan over meerdere bounded contexts worden verdeeld.
Opdracht: Voor je eigen projectcasus: bepaal of je domein model groot genoeg is om op te splitsen in subdomeinen. Als je model klein is (past op één A4), hoef je dit niet te doen. Als je model groter wordt, identificeer dan minimaal twee subdomeinen en leg uit waarom je deze splitsing maakt.
5. Voorbeeld domein model - Bibliotheek casus
Hieronder staan twee varianten van een domein model voor een bibliotheeksysteem: een initiële (eenvoudige) versie (Figuur 4) en een uitgebreide versie (Figuur 5). Je kunt deze visualiseren met de PlantUML Online Server of met de VS Code PlantUML Extension.
Tip: Bij alle zeven diagrammen in deze les staat de PlantUML broncode in een uitklapbaar blok. Dit is zodat je de code kunt kopiëren en aanpassen voor je eigen projectcasus.
5.1 Initiële versie (eenvoudig)
Deze versie bevat alleen de basisconcepten en is geschikt om te starten met het domeinmodel.
Figuur 4: Initiële domein model voor het bibliotheeksysteem met basisconcepten.
📋 PlantUML Code - Initiële Domein Model
@startuml
!theme plain
skinparam classAttributeIconSize 0
class Klant {
- naam
- klantnummer
}
class Reservering {
- reserveringsnummer
- reserveringsdatum
}
class Uitleenitem {
- titel
- auteur
- isbn
- jaar van uitgifte
}
class Categorie {
- naam
}
Klant "1" --> "*" Reservering : maakt
Reservering "1" --> "*" Uitleenitem : bevat
Uitleenitem "*" --> "1" Categorie : heeft
note right of Klant
Een klant kan meerdere
reserveringen maken
end note
note right of Reservering
Een reservering kan
meerdere items bevatten
end note
note right of Uitleenitem
Beschrijving van een item
(bijv. "Harry Potter deel 1").
ISBN en jaar alleen voor boeken.
end note
note right of Categorie
Voorbeelden: boek, game,
stripboek
end note
@enduml
Glossary - Initiële versie
| Term | Definitie |
|---|---|
| Klant | Een persoon die items kan reserveren en lenen bij de bibliotheek. Heeft een uniek klantnummer. |
| Reservering | Een verzoek van een klant om een of meerdere items te reserveren. Heeft een reserveringsnummer en reserveringsdatum. |
| Uitleenitem | Een beschrijving van een item dat uitgeleend kan worden (bijvoorbeeld een boek, game of stripboek). Bevat titel, auteur, ISBN (voor boeken, bijvoorbeeld "978-90-1234-567-8") en jaar van uitgifte. |
| Categorie | Een classificatie van uitleenitems, zoals "boek", "game" of "stripboek". |
5.2 Uitgebreide versie
Deze versie bevat meer detail en maakt onderscheid tussen beschrijvingen en fysieke exemplaren, en voegt entiteiten toe voor Auteur en Conditie.
Figuur 5: Uitgebreide domein model met onderscheid tussen beschrijvingen en fysieke exemplaren.
📋 PlantUML Code - Uitgebreide Domein Model
@startuml
!theme plain
skinparam classAttributeIconSize 0
class Klant {
- naam
- klantnummer
}
class Reservering {
- reserveringsnummer
- reserveringsdatum
- ophaaldatum
- inleverdatum
}
class Uitleenitem {
- titel
- isbn
- jaar van uitgifte
}
class Auteur {
- naam
}
class Exemplaar {
- exemplaarnummer
- aanschafdatum
}
class Conditie {
- naam
}
class Categorie {
- naam
}
Klant "1" --> "*" Reservering : maakt
Reservering "1" --> "1" Exemplaar : bevat
Exemplaar "1" --> "1" Uitleenitem : is van
Exemplaar "1" --> "1" Conditie : heeft
Uitleenitem "*" --> "1" Categorie : heeft
Uitleenitem "1" --> "*" Exemplaar : heeft
Uitleenitem "*" --> "*" Auteur : geschreven door
note right of Klant
Een klant kan meerdere
reserveringen maken
end note
note right of Reservering
Een reservering verwijst
naar een specifiek exemplaar.
Reserveringsdatum: wanneer gemaakt.
Ophaaldatum: deadline voor ophalen.
Inleverdatum: wanneer ingeleverd.
end note
note right of Uitleenitem
Beschrijving van een item
(bijv. "Harry Potter deel 1").
Kan meerdere exemplaren hebben.
ISBN en jaar alleen voor boeken.
end note
note right of Exemplaar
Fysiek exemplaar dat
daadwerkelijk uitgeleend wordt
end note
note right of Conditie
Voorbeelden: als nieuw,
veelgebruikt, beschadigd
end note
note right of Categorie
Voorbeelden: boek, game,
stripboek
end note
@enduml
Glossary - Uitgebreide versie
| Term | Definitie |
|---|---|
| Klant | Een persoon die items kan reserveren en lenen bij de bibliotheek. Heeft een uniek klantnummer. |
| Reservering | Een verzoek van een klant om een specifiek exemplaar te reserveren. Heeft een reserveringsnummer, reserveringsdatum (wanneer gemaakt), ophaaldatum (deadline voor ophalen) en inleverdatum (wanneer ingeleverd). |
| Uitleenitem | Een beschrijving van een item dat uitgeleend kan worden (bijvoorbeeld "Harry Potter deel 1"). Bevat titel, ISBN (alleen voor boeken, bijvoorbeeld "978-90-1234-567-8") en jaar van uitgifte. Een uitleenitem kan meerdere fysieke exemplaren hebben. |
| Exemplaar | Een fysiek exemplaar van een uitleenitem dat daadwerkelijk uitgeleend kan worden. Heeft een uniek exemplaarnummer en aanschafdatum. Elke uitleenitem kan meerdere exemplaren hebben. |
| Auteur | De schrijver of maker van een uitleenitem. Een uitleenitem kan meerdere auteurs hebben (co-auteurs), en een auteur kan meerdere items geschreven hebben. |
| Conditie | De fysieke staat van een exemplaar, zoals "als nieuw", "veelgebruikt" of "beschadigd". |
| Categorie | Een classificatie van uitleenitems, zoals "boek", "game" of "stripboek". |
5.3 Dataklassen in het oplossingsdomein
Het domeinmodel hierboven bevindt zich in het probleemdomein - het gaat om de concepten en relaties in de business/wereld. Larman's domeinmodel is statisch en bevat meestal geen methodes. In het oplossingsdomein (de software) worden deze concepten geïmplementeerd als OO classes met specifieke datatypes en methodes. Martin Fowler's domain model bevindt zich in het oplossingsdomein en bevat wel methodes die dynamisch gedrag representeren (hoewel een class diagram nog steeds een statisch UML diagram is - binnen de UML diagram is een UML sequence diagram voor het dynamische gedrag tonen (een bepaalde sequentie van methode aanroepen op runtime)).
Terminologie: In het oplossingsdomein worden de classes soms ook wel "Business Class Diagram" genoemd, maar de term "Domein" is generieker van 'business', want omvat ook organisaties die niet per se tot het bedrijfsleven worden gerekend, zoals overheid, non-profit organisaties, of educatieve instellingen. Daarom gebruiken we liever de term "Domein".
Recap verwarrende terminologie — "domein model" in twee betekenissen:
De term "domein model" wordt helaas voor twee verschillende dingen gebruikt. Deze workshop gaat vooral over die van Craig Larman, maar de term kan verwarrend zijn, omdat de 2e soort (degene die Martin Fowler gebruikt) WEL degelijk in het oplossingsdomein zit:
-
Larman's domein model (probleemdomein): Een communicatiemiddel voor stakeholders, zonder technische details. Dit is wat we in sectie 2 bespraken als een subset van het probleemdomein dat naar het oplossingsdomein gaat.
-
Fowler's domain model (oplossingsdomein): De entiteiten/models in je code met business logica — de "domain layer" in een layered architecture. Dit is wat je in frameworks als Spring Boot of .NET terugziet als
@Entityclasses en/of models in eenmodel/folder e.d. Idealiter voeg je in deze models ook methodes toe naast de attributen, om echt Object Oriented te programeren: data+methodes, als je alle methodes voor domein logica alleen in services stopt krijg je een anemic domain model (Fowler, 2003) (wel geschikt voor simpele CRUD applicaties, maar typisch NIET voor complex 'core domain' met DDD aanpak i.p.v. CRUD)1.
De subset-relatie geldt voor de domain layer: niet alle concepten uit het probleemdomein worden geïmplementeerd. Maar tegelijkertijd bevat de complete applicatie juist méér dan het probleemdomein: Controllers, Repositories, Services, DTOs, en technische attributen zoals id en createdAt. Deze extra classes vallen echter in andere lagen (Application, Infrastructure) en maken geen deel uit van de domain layer.
Kortom: de domain layer is een subset van het probleemdomein, maar de totale applicatie is een uitbreiding. In een UML klassendiagram van alleen de domain layer laat je de technische classes weg; in een compleet klassendiagram van de hele applicatie komen ze juist wel voor.
💡 DDD vs CRUD
Waar een CRUD-aanpak vertrekt vanuit data en generieke bewerkingen (Create, Read, Update, Delete), vertrekt Domain-Driven Design vanuit het probleemdomein en de betekenis van businessregels. In die zin is DDD het tegenovergestelde van CRUD-denken: niet "welke data slaan we op?" maar "welke concepten en regels bepalen het gedrag van het systeem?"
Let op: Figuur 6 toont een voorbeeld van hoe je het probleemdomein kunt vertalen naar het oplossingsdomein. In de praktijk kunnen er nog extra technische attributen bijkomen (zoals id, createdAt, updatedAt) en kunnen relaties worden geïmplementeerd als foreign keys of referenties. Ook komen er in het oplossingsdomein classes zoals Controllers en Repositories bij, maar deze vallen in een andere laag dan de Domein laag (bijvoorbeeld de Application laag of Infrastructure laag volgens layered architecture).
Figuur 6: Dataklassen in het oplossingsdomein met OO datatypes en methodes.
📋 PlantUML Code - Dataklassen Oplossingsdomein
@startuml
!theme plain
skinparam classAttributeIconSize 0
class Klant {
- id: Long
- naam: String
- klantnummer: String
+ maakReservering(exemplaar: Exemplaar): Reservering
+ getActieveReserveringen(): List<Reservering>
}
class Reservering {
- id: Long
- reserveringsnummer: String
- reserveringsdatum: LocalDate
- ophaaldatum: LocalDate
- inleverdatum: LocalDate
- klantId: Long
- exemplaarId: Long
+ isOpgehaald(): Boolean
+ isIngeleverd(): Boolean
+ haalOp(): void
+ leverIn(): void
}
class Uitleenitem {
- id: Long
- titel: String
- isbn: String?
- jaarVanUitgifte: Integer?
- categorieId: Long
+ getBeschikbareExemplaren(): List<Exemplaar>
+ heeftBeschikbaarExemplaar(): Boolean
+ voegAuteurToe(auteur: Auteur): void
}
class Auteur {
- id: Long
- naam: String
+ getGeschrevenItems(): List<Uitleenitem>
}
class Exemplaar {
- id: Long
- exemplaarnummer: String
- aanschafdatum: LocalDate
- uitleenitemId: Long
- conditieId: Long
+ isBeschikbaar(): Boolean
+ updateConditie(conditie: Conditie): void
+ getLeeftijd(): int
}
class Conditie {
- id: Long
- naam: String
}
class Categorie {
- id: Long
- naam: String
+ getItems(): List<Uitleenitem>
}
Klant "1" --> "*" Reservering
Reservering "1" --> "1" Exemplaar
Exemplaar "1" --> "1" Uitleenitem
Exemplaar "1" --> "1" Conditie
Uitleenitem "*" --> "1" Categorie
Uitleenitem "1" --> "*" Exemplaar
Uitleenitem "*" --> "*" Auteur : many-to-many
note right of Reservering
Foreign keys: klantId, exemplaarId
end note
note right of Uitleenitem
isbn en jaarVanUitgifte
zijn nullable (alleen voor boeken)
end note
note right of Exemplaar
Foreign keys: uitleenitemId, conditieId
end note
@enduml
5.4 Subdomeinen: Uitlenen en Collectie onderhoud
Wanneer een domeinmodel te groot wordt, kun je het opsplitsen in subdomeinen volgens Domain-Driven Design (DDD) principes. Hieronder wordt het bibliotheeksysteem opgesplitst in twee subdomeinen: Uitlenen (Figuur 7) en Collectie onderhoud (Figuur 8).
5.4.1 Subdomein: Uitlenen
Dit subdomein bevat alle concepten die nodig zijn voor het uitlenen van items aan klanten.
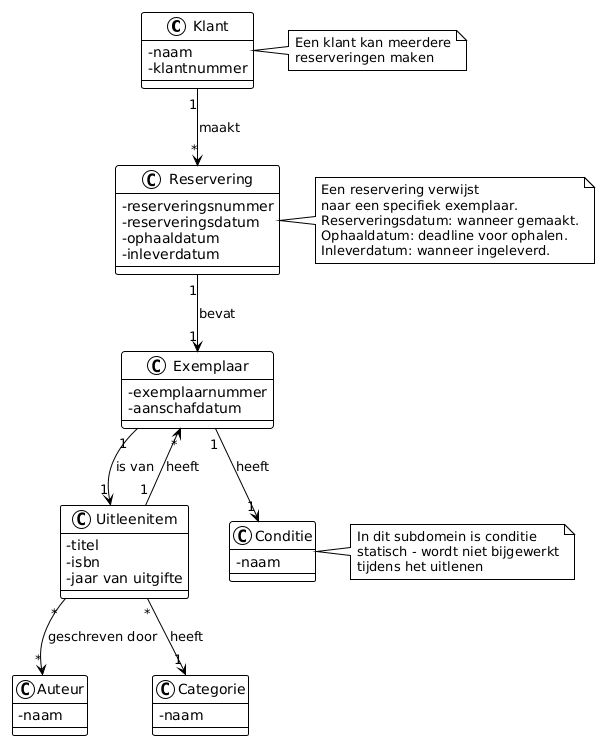
Figuur 7: Subdomein Uitlenen — concepten voor het uitlenen van items aan klanten.
📋 PlantUML Code - Subdomein Uitlenen
@startuml
!theme plain
skinparam classAttributeIconSize 0
class Klant {
- naam
- klantnummer
}
class Reservering {
- reserveringsnummer
- reserveringsdatum
- ophaaldatum
- inleverdatum
}
class Uitleenitem {
- titel
- isbn
- jaar van uitgifte
}
class Auteur {
- naam
}
class Exemplaar {
- exemplaarnummer
- aanschafdatum
}
class Conditie {
- naam
}
class Categorie {
- naam
}
Klant "1" --> "*" Reservering : maakt
Reservering "1" --> "1" Exemplaar : bevat
Exemplaar "1" --> "1" Uitleenitem : is van
Exemplaar "1" --> "1" Conditie : heeft
Uitleenitem "*" --> "1" Categorie : heeft
Uitleenitem "1" --> "*" Exemplaar : heeft
Uitleenitem "*" --> "*" Auteur : geschreven door
note right of Klant
Een klant kan meerdere
reserveringen maken
end note
note right of Reservering
Een reservering verwijst
naar een specifiek exemplaar.
Reserveringsdatum: wanneer gemaakt.
Ophaaldatum: deadline voor ophalen.
Inleverdatum: wanneer ingeleverd.
end note
note right of Conditie
In dit subdomein is conditie
statisch - wordt niet bijgewerkt
tijdens het uitlenen
end note
@enduml
5.4.2 Subdomein: Collectie onderhoud
Dit subdomein bevat alle concepten die nodig zijn voor het beheren en onderhouden van de collectie. In dit subdomein heeft een exemplaar een status 'Uitgeleend' (boolean) en is conditie dynamisch - het kan worden bijgewerkt door een boekkeurder. Klanten komen niet voor in dit subdomein.
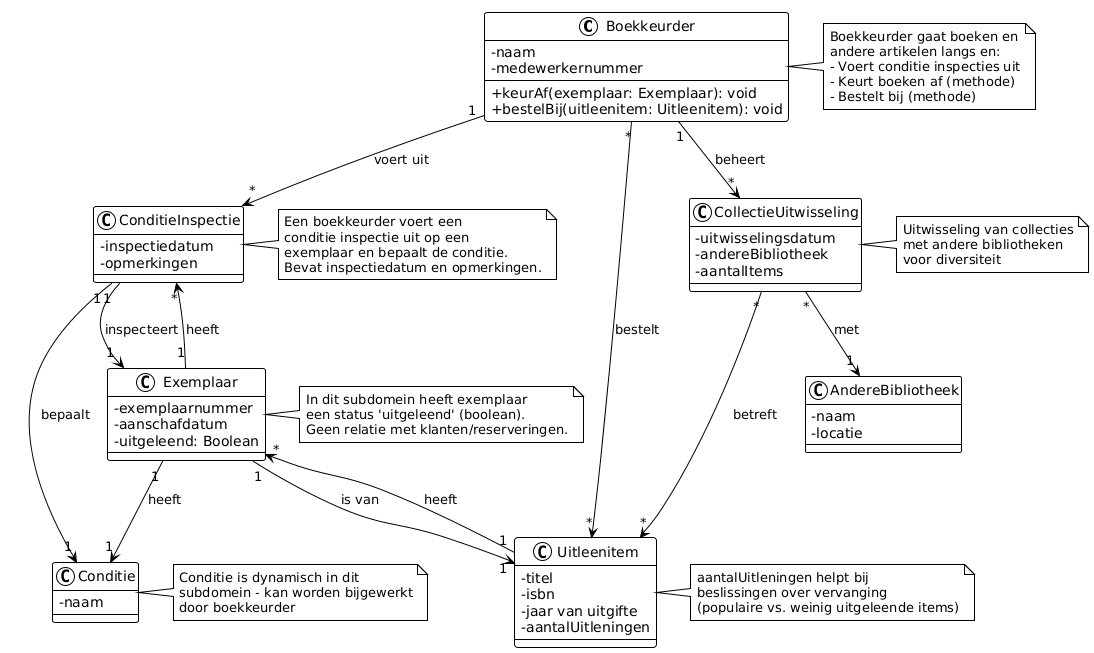
Figuur 8: Subdomein Collectie onderhoud — concepten voor het beheren en onderhouden van de collectie.
📋 PlantUML Code - Subdomein Collectie onderhoud
@startuml
!theme plain
skinparam classAttributeIconSize 0
class Boekkeurder {
- naam
- medewerkernummer
+ keurAf(exemplaar: Exemplaar): void
+ bestelBij(uitleenitem: Uitleenitem): void
}
class Uitleenitem {
- titel
- isbn
- jaar van uitgifte
- aantalUitleningen
}
class Exemplaar {
- exemplaarnummer
- aanschafdatum
- uitgeleend: Boolean
}
class Conditie {
- naam
}
class ConditieInspectie {
- inspectiedatum
- opmerkingen
}
class CollectieUitwisseling {
- uitwisselingsdatum
- andereBibliotheek
- aantalItems
}
class AndereBibliotheek {
- naam
- locatie
}
Boekkeurder "1" --> "*" ConditieInspectie : voert uit
ConditieInspectie "1" --> "1" Exemplaar : inspecteert
ConditieInspectie "1" --> "1" Conditie : bepaalt
Boekkeurder "*" --> "*" Uitleenitem : bestelt
Exemplaar "1" --> "*" ConditieInspectie : heeft
Exemplaar "1" --> "1" Uitleenitem : is van
Uitleenitem "1" --> "*" Exemplaar : heeft
Exemplaar "1" --> "1" Conditie : heeft
Boekkeurder "1" --> "*" CollectieUitwisseling : beheert
CollectieUitwisseling "*" --> "1" AndereBibliotheek : met
CollectieUitwisseling "*" --> "*" Uitleenitem : betreft
note right of Boekkeurder
Boekkeurder gaat boeken en
andere artikelen langs en:
- Voert conditie inspecties uit
- Keurt boeken af (methode)
- Bestelt bij (methode)
end note
note right of ConditieInspectie
Een boekkeurder voert een
conditie inspectie uit op een
exemplaar en bepaalt de conditie.
Bevat inspectiedatum en opmerkingen.
end note
note right of Exemplaar
In dit subdomein heeft exemplaar
een status 'uitgeleend' (boolean).
Geen relatie met klanten/reserveringen.
end note
note right of Conditie
Conditie is dynamisch in dit
subdomein - kan worden bijgewerkt
door boekkeurder
end note
note right of CollectieUitwisseling
Uitwisseling van collecties
met andere bibliotheken
voor diversiteit.
Dit kan leiden tot een 3e subdomein
"Boekdistributie": vrachtwagen voor
honderden boeken over grote afstand
(tussen steden), of fiets/kar voor
kleine afstand (twee bibliotheken in
één stad, maandelijks 20 boeken).
Vragen: rijduur, aantal uitladers, etc.
Dit diagram werken we NIET uit.
end note
note right of Uitleenitem
aantalUitleningen helpt bij
beslissingen over vervanging
(populaire vs. weinig uitgeleende items)
end note
@enduml
Glossary - Subdomein Collectie onderhoud
| Term | Definitie |
|---|---|
| Boekkeurder | Een medewerker die boeken en andere artikelen in de bibliotheek langsgaat. Voert conditie inspecties uit, keurt boeken af en bestelt bij. |
| ConditieInspectie | Een inspectie door een boekkeurder van een exemplaar om de conditie te bepalen. Bevat inspectiedatum en opmerkingen. |
| Exemplaar | In dit subdomein heeft een exemplaar een status 'uitgeleend' (boolean) in plaats van een relatie met klanten/reserveringen. De conditie wordt bepaald via conditie inspecties. |
| Conditie | De fysieke staat van een exemplaar. In dit subdomein wordt conditie bepaald via conditie inspecties door een boekkeurder (in tegenstelling tot het Uitlenen subdomein waar conditie statisch is). |
| CollectieUitwisseling | Het uitwisselen van items tussen bibliotheken om de collectie diverser te maken of weinig uitgeleende items te vervangen door populairdere items. |
| AndereBibliotheek | Een andere bibliotheek waarmee collecties kunnen worden uitgewisseld. |
| Uitleenitem | Bevat aantalUitleningen om te helpen bij beslissingen over welke items populair zijn en welke vervangen kunnen worden. |
Shared Kernel: In de praktijk zouden deze subdomeinen mogelijk verschillende bounded contexts worden in het oplossingsdomein. Concepten zoals Uitleenitem en Exemplaar komen in beide subdomeinen voor. Volgens Evans (2003) kun je hiervoor een Shared Kernel patroon gebruiken: een expliciet gedeeld model tussen bounded contexts. Dit moet zorgvuldig worden beheerd, omdat wijzigingen in de shared kernel beide bounded contexts beïnvloeden. Alternatief is om deze concepten te dupliceren per bounded context (Conformist of Separate Ways), maar dan moet je wel synchronisatie regelen.
Opdracht: Maak voor je eigen projectcasus een domein model en glossary. Begin met een initiële (eenvoudige) versie met alleen de belangrijkste concepten. Zorg dat het model klein blijft (past op één A4). Maak het model met Mermaid of PlantUML (via de PlantUML Online Server of de VS Code PlantUML Extension) en voeg een glossary tabel toe met definities van alle termen. Valideer je domein model met niet-technische stakeholders (bijvoorbeeld je opdrachtgever of product owner) om te controleren of je het probleem goed hebt begrepen.
6. Kwaliteitscriteria voor domein model
6.1 Doelgroep: (ook) niet-technische stakeholders
Het domein model is primair bedoeld voor communicatie met niet-technische stakeholders, zoals opdrachtgevers, product owners, en andere belanghebbenden, om te valideren of je het probleem goed hebt begrepen. Na validatie kun je het domein model gebruiken als basis voor je implementatie, maar je hoeft niet alle entiteiten uit het domein model te implementeren in je OO domain layer - kies alleen wat nodig is voor je MVP.
Belangrijk: Omdat het domein model bedoeld is voor niet-technische stakeholders, moet je in het domein model geen technische OO-concepten gebruiken zoals:
- Overerving (inheritance)
- Interfaces of abstracte classes
- Polymorfie
- Entities vs. Value Objects (DDD concepten)
Ook DDD-concepten zoals Entities en Value Objects horen niet in het domein model thuis. Deze concepten zeggen een opdrachtgever meestal niets en geven het gevoel dat "dit diagram niet voor mij is maar voor developers", waardoor ze er niet goed naar kijken.
In de oplossingsfase (bijvoorbeeld in je Software Guidebook of domain layer) kun je wel kijken naar het onderscheid tussen Entities en Value Objects uit DDD, en object-georiënteerde concepten zoals overerving, interfaces en polymorfie gebruiken. Maar dit hoort niet in het domein model zelf, omdat dat model bedoeld is om het probleem te begrijpen en te communiceren, niet om de oplossing te ontwerpen.
Let op: Als je toch OO-concepten zoals overerving, compositie of aggregatie in een diagram wilt gebruiken (bijvoorbeeld in een technisch diagram voor developers), voeg dan altijd een legenda en goed beschrijvende labels toe. Zoals Simon Brown aangeeft in zijn presentatie "The lost art of Software Design" (26 oktober 2022): zonder legenda en duidelijke labels zijn diagrammen moeilijk te begrijpen, zelfs voor technische stakeholders. Dit geldt echter niet voor het domein model zelf, dat bedoeld is voor niet-technische stakeholders.
6.2 Checklist
Gebruik onderstaande Checklist 1 om te controleren of je domein model en glossary voldoen aan de kwaliteitseisen. Druk op Ctrl+D om aanvullende details te tonen.
Checklist 1: Kwaliteitscriteria domein model
- DM-1: Maak het domein model begrijpelijk voor de opdrachtgever: Je gebruikt entiteitnamen die herkenbaar zijn voor de opdrachtgever en je gebruikt Ubiquitous Language (de taal die stakeholders in het domein gebruiken) consistent in het diagram, de glossary en de toelichting. Je gebruikt domeintermen zoals "Boeklener" in plaats van generieke termen zoals "Klant" of "Gebruiker". Je vermijdt OO "weasel words" zoals "UitleenInstantie" of "LeenCategorie" — je gebruikt liever concrete domeintermen zoals "Bibliotheek" of "Uitleenperiode".
- DM-2: Je richt het domein model niet al op een oplossing: Je domein model beschrijft het probleemdomein, niet al het oplossingsdomein. Het criterium is niet 'gaat ons (beoogde) systeem dit opslaan?'2, maar 'zijn alle relevante entiteiten uit het probleemdomein aanwezig?'.
- DM-3: Je voegt een legenda toe aan het domein model: Als je relaties of pijlen gebruikt, voeg je een legenda toe die uitlegt wat de verschillende soorten relaties betekenen. Je gebruikt niet teveel verschillende soorten pijlen en je bewaart technische OO-concepten zoals overerving, interfaces voor latere uitwerking van de oplossing, zodat je nu op het probleem focust.
Opdracht: Bedenk zelf minimaal twee aanvullende kwaliteitscriteria voor een domein model die Checklist 1 niet geeft. Denk bijvoorbeeld aan aspecten zoals: validatie met stakeholders, onderhoudbaarheid, of andere aspecten die belangrijk zijn voor een goed domein model. Leg uit waarom deze criteria belangrijk zijn en hoe je ze zou kunnen controleren.
7. Verder lezen/verdiepen
Subdomeinen en Context Mapping
Als je het domein model opsplitst in subdomeinen (zie criterium DM-6), maak je meerdere domeinmodellen, elk met een eigen toelichting. Je voegt ook een algemene introductie toe waarin je de subdomeinen introduceert. Zorg dat je de subdomeinen een korte maar beschrijvende naam geeft, zoals 'Uitleensysteem' en 'Collectie beheer' uit het voorbeeld in sectie 5.
Als je echt richting 'Software Architect' niveau wilt stijgen, kun je ook nadenken over en verdiepen in de Context Mapping techniek uit DDD. Dit is het derde strategische pattern uit DDD naast de 'Ubiquitous Language' en 'Bounded Context' patterns. Context mapping gaat over welke relatie subdomeinen onderling hebben, wie is client (upstream) en wie is server (downstream), zijn er 'generic subdomains' (zoals authenticatie), of shared kernels. Zie voor meer informatie de video "The Ultimate Guide to Context Mapping in Domain Driven Design" (Master AWS with Yan, 27-11-2024).
Subdomein Overzicht vs. Context Map
Er is een belangrijk onderscheid tussen een Subdomein Overzicht (probleemdomein) en een Context Map (oplossingsdomein):
- Subdomein Overzicht: Toont de verschillende business-domeinen en hun onderlinge afhankelijkheden op conceptueel niveau. Dit is wat je maakt voordat je naar de oplossing kijkt. Het laat zien hoe de business is georganiseerd, welke domeinen informatie uitwisselen, en wat de kernactiviteiten zijn.
- Context Map: Toont hoe bounded contexts (applicaties/modules) op elkaar aansluiten, met technische patterns zoals Shared Kernel, Customer-Supplier, Conformist, Anti-Corruption Layer, etc. Dit is een oplossingsdomein-diagram.
Interessant is dat er vaak een natuurlijke mapping is tussen subdomeinen en bounded contexts — dit is het effect van Conway's Law: "Organizations design systems that mirror their own communication structure." De applicaties die een organisatie bouwt, volgen vaak de afdelingsstructuur. Een Subdomein Overzicht kan daarom een goede voorspeller zijn voor de latere architectuur.
Voorbeeld: Subdomein Overzicht Bibliotheek
Figuur 9 toont een voorbeeld van een Subdomein Overzicht voor de bibliotheek casus. Dit diagram toont de subdomeinen op business-niveau, met hun onderlinge afhankelijkheden en classificatie (core, supporting, generic).
Figuur 9: Subdomein Overzicht — business-niveau overzicht met core, supporting en generic subdomeinen.
📋 PlantUML Code - Subdomein Overzicht
@startuml
!theme plain
skinparam rectangle {
roundCorner 10
}
title Subdomein Overzicht - Bibliotheeksysteem
' Core subdomeinen (primaire business)
rectangle "**Uitlenen**\n(Core)" as Uitlenen #LightGreen
rectangle "**Collectie Onderhoud**\n(Core)" as Collectie #LightGreen
' Supporting subdomeinen (ondersteunend)
rectangle "**Klantbeheer**\n(Supporting)" as Klant #LightBlue
rectangle "**Boekdistributie**\n(Supporting)" as Distributie #LightBlue
' Generic subdomeinen (generiek, evt. off-the-shelf)
rectangle "**Notificaties**\n(Generic)" as Notificatie #LightGray
rectangle "**Betalingen**\n(Generic)" as Betaling #LightGray
' Relaties tussen subdomeinen
Uitlenen --> Klant : heeft klantgegevens\nnodig
Uitlenen --> Collectie : checkt beschikbaarheid\nexemplaren
Uitlenen --> Notificatie : triggert\nherinneringen
Uitlenen --> Betaling : int boetes bij\nte laat inleveren
Collectie --> Distributie : vraagt aanvulling\nbij tekort
Distributie --> Collectie : levert nieuwe\nexemplaren
Klant --> Notificatie : ontvangt\nberichten
Klant --> Betaling : betaalt\nlidmaatschap
' Legenda
legend right
|= Kleur |= Type |= Betekenis |
| <#LightGreen> | Core | Kernactiviteit, unieke waarde |
| <#LightBlue> | Supporting | Ondersteunend, kan uitbesteed |
| <#LightGray> | Generic | Generiek, off-the-shelf mogelijk |
endlegend
@enduml
Toelichting bij het diagram:
- Core subdomeinen (groen): Dit zijn de kernactiviteiten die de bibliotheek uniek maken. Hier investeer je het meest in maatwerk.
- Supporting subdomeinen (blauw): Ondersteunende domeinen die nodig zijn maar niet de kern vormen. Ze zijn wel domeinspecifiek — een bibliotheek heeft andere klantgegevens nodig (lidmaatschappen, leenrechten, leeftijdscategorieën) dan bijvoorbeeld een webshop.
- Generic subdomeinen (grijs): Generieke functionaliteit die elk bedrijf nodig heeft, ongeacht het domein. Deze kun je vaak kopen als off-the-shelf oplossing (bijv. Twilio voor notificaties, Mollie voor betalingen).
Supporting vs. Generic — wat is het verschil?
Het onderscheid tussen Supporting en Generic is soms subtiel. De kernvraag is: "Is dit specifiek voor mijn domein, of heeft elk bedrijf dit nodig?"
| Subdomein | Classificatie | Redenering |
|---|---|---|
| Klantbeheer | Supporting | Een bibliotheek heeft domeinspecifieke klantgegevens: lidmaatschapstype, leenrechten, reserveringslimiet. Dit is anders dan klantbeheer bij een webshop of bank. |
| Boekdistributie | Supporting | Specifiek voor bibliotheken — uitwisseling van collecties tussen vestigingen is uniek voor dit domein. |
| Notificaties | Generic | E-mail/SMS versturen is universeel. Elk bedrijf doet dit. Je kunt een standaarddienst zoals SendGrid of Twilio gebruiken. |
| Betalingen | Generic | Geld innen is universeel. Je gebruikt liever Mollie of Stripe dan zelf een betalingssysteem bouwen. |
Let op: De grens is niet altijd scherp. Je zou kunnen beargumenteren dat "Klantbeheer" ook generic is (elk bedrijf heeft klanten). Maar zodra je domeinspecifieke attributen toevoegt (zoals "maximaal aantal gelijktijdige uitleningen"), wordt het Supporting. De classificatie hangt af van hoeveel domeinlogica erin zit.
De pijlen tonen welk subdomein informatie nodig heeft van een ander subdomein. Dit is nog geen technische integratie — het toont de business-afhankelijkheden. In een latere Context Map zou je deze relaties vertalen naar concrete integration patterns.
Let op: Dit Subdomein Overzicht is een optioneel verdiepingsdiagram. Voor de meeste projecten in de minor is een enkel domein model voldoende. Maak dit overzicht alleen als je domein model te groot wordt en je het wilt opsplitsen (zie criterium DM-6).
Quiz
Test je kennis over domein modellen, DDD en Design Thinking met deze multiple choice quiz:
Dat is het datamodel i.p.v. het domeinmodel.
Zie het uitklapblok "DDD vs CRUD" in sectie 5.3 voor meer uitleg over dit verschil.
Bronnen
- Design Council. (z.d.). The Double Diamond. Design Council. Geraadpleegd op 6 januari 2026, van https://www.designcouncil.org.uk/our-resources/the-double-diamond/
- Evans, E. (2003). Domain-Driven Design: Tackling Complexity in the Heart of Software. Addison-Wesley Professional. Geraadpleegd op 6 januari 2026, van https://www.domainlanguage.com/ddd/
- Fowler, M. (2003, 25 november). AnemicDomainModel. martinfowler.com. Geraadpleegd op 6 januari 2026, van https://martinfowler.com/bliki/AnemicDomainModel.html
- Gupta, N. (2019, 7 februari). Problem Space vs Solution Space. Medium. Geraadpleegd op 6 januari 2026, van https://medium.com/@nikhilgupta08/problem-space-vs-solution-space-f970d4ace5c
- Lambrych, J. (2024, 25 juni). Domain-Driven Design (DDD): Strategic Design Explained. Medium. Geraadpleegd op 6 januari 2026, van https://medium.com/@lambrych/domain-driven-design-ddd-strategic-design-explained-55e10b7ecc0f
- Larman, C. (2004). Applying UML and Patterns: An Introduction to Object-Oriented Analysis and Design and Iterative Development (3rd ed.). Prentice Hall. Geraadpleegd op 6 januari 2026, van https://www.craiglarman.com/wiki/index.php?title=Book_Applying_UML_and_Patterns
- Master AWS with Yan. (2024, 27 november). The Ultimate Guide to Context Mapping in Domain Driven Design [Video]. YouTube. Geraadpleegd op 6 januari 2026, van https://www.youtube.com/watch?v=6_pQRH9wYtU
- Wikipedia contributors. (2024). Subset. Wikipedia, The Free Encyclopedia. Geraadpleegd op 6 januari 2026, van https://en.wikipedia.org/wiki/Subset
Lesrooster
Hier het lesoverzicht van de minor. Tijdens de minor volgen wellicht nog wat wijzigingen. Onder de tabel verdere toelichting.
Onderwijsweek 1 t/m 3
| Onderwijsweek 1 GitOps Week 36 1-7 sep 2025 | Onderwijsweek 2 Containerization Week 37 8-14 sep 2025 | Onderwijsweek 3 Continuous Delivery Week 38 15-21 sep 2025 | |
|---|---|---|---|
| Maandag ochtend | Linux 101 | Linux bash script | Micro front-ends - Deadline week opdracht 2 |
| Maandag middag | Lesvrij, aan weekopdracht werken |  InfoSupport 1/4 InfoSupport 1/4 | Lesvrij, aan weekopdracht werken |
| Dinsdag ochtend | Docker 101 | Docker 102 | C4 & Continuous Documentation + Oefentoets |
| Woensdag middag | Getting Git (eenmalig 's ochtends) | InfoSupport 2/4 | Lesvrij |
| Donderdag ochtend | - Opdracht 1 Deadline - git workflows (.NET/TDD) | ADR & ORM - Linux bash opdracht deadline | - Opdracht 3 Deadline Deeltoets 1 |
Onderwijsweek 4 t/m 6
| Onderwijsweek 4 Orchestration/DevSecOps Week 39 22-28 sep 2025 | Onderwijsweek 5 SlackOps Week 40 29 sep-5 okt 2025 | Onderwijsweek 6 BP Spike (sprint 1) Week 41 6-12 okt 2025 | |
|---|---|---|---|
| Maandag ochtend | RabbitMQ 1/2 | BDD - Behaviour Driven Development (vervolg op RabbitMQ) | - Workshop Story Mapping - Teams Backlog |
| Maandag middag | | Kubernetes 102 | Sprint 1 planning 📍 R26 Arnhem |
| Dinsdag ochtend | K8s 101: Architecture + 12factor presentaties |  | - Spike Ontwikkelen |
| Woensdag middag | Semantic Versioning | Lesvrij | |
| Donderdag ochtend | Tussen deadline wk opdracht 5 + Lesvrij (vragenuur 9:00-10:00) | Bespreking opdracht wk4+5 | DevOps tech presentaties (onderzoeks presentatie pitch) |
| Donderdag middag | Deeltoets 2 (13:45-15:15) |
Onderwijsweek 7 t/m 9
| Onderwijsweek 7 BP (sprint 2) Week 43 20-26 okt 2025 | Onderwijsweek 8 BP (sprint 3) Week 44 27 okt-2 nov 2025 | Onderwijsweek 9 Demo's + beoordelingen / Herkansing Week 45 3-9 nov 2025 | |
|---|---|---|---|
| Maandag ochtend | Sprint 1 review (demo) + Sprint 1 retrospective 📍 Veenendaal | Sprint 2 review (demo) + Sprint 2 retrospective 📍 Veenendaal | Productdemo's groepen |
| Maandag middag | Sprint 2 planning 📍 R26 Arnhem | Sprint 3 planning 📍 R26 Arnhem | Groepssessie Individuele verantwoording bijdrage |
| Dinsdag ochtend | C4 diagrammen (Context + Container) gereed | Peer assessment ADR's (min. 2) gereed | Lesvrij |
| Woensdag middag | ... | | |
| Donderdag ochtend | Naar staging | Herkansing (totaal)toets |
Wekelijk Organisatie
Contacttijd:
- 1 sessie met gastdocent
- 3 sessies met cursusdocent
Huiswerk:
Het huiswerk staat per les gegeven. Ook is er een wekelijkse weekopdracht die je in duo's maakt (of later grotere groep) en waarbij je onderling zelf de taken uit die weekopdracht moet verdelen. Je moet zelf goed plannen om zowel les huiswerk te maken als de weekopdracht. Zie Weekopdrachten werkwijze voor uitgebreide informatie over de werkwijze, groepsvorming, peer review en inleverprocedures.
Studiejaar 2025/2026 - Kalenderweken
| Weeknr | Datum | Onderwijsweek |
|---|---|---|
| 35 | 25-31 augustus 2025 | Kick-off donderdag 28 aug |
| 36 | 1-7 september 2025 | OW 1 |
| 37 | 8-14 september 2025 | OW 2 |
| 38 | 15-21 september 2025 | OW 3 |
| 39 | 22-28 september 2025 | OW 4 |
| 40 | 29 september - 5 oktober 2025 | OW 5 |
| 41 | 6-12 oktober 2025 | OW 6 |
| 42 | 13-19 oktober 2025 | Herfstvakantie |
| 43 | 20-26 oktober 2025 | OW 7 |
| 44 | 27 oktober - 2 november 2025 | OW 8 |
| 45 | 3-9 november 2025 | OW 9 |
Belangrijke data:
- 28 augustus 2025: Kick-off minor (donderdag 9:00-12:15, Ruitenberglaan 26)
- 5 september 2025: Deadline indienen afstuderen P1 OW-5
- 6-24 oktober 2025: Intekenen onderwijs P2
Programmaoverzicht
Week 1 t/m 5 - Wekelijks een DevOps-gerelateerd onderwerp.
- Activiteiten: Theorie, opdrachten, lessen.
In de eerste vijf weken leer je de basis van DevOps ter voorbereiding op afsluitende opdrachten. Dit gebeurt via het flipped classroom model, waarbij je zelfstandig thuis online bronnen bestudeert, zoals blogs, video's en opgegeven documentatie.
Week 6 t/m 8: Eindopdracht - Beroepsproduct
- Doel: Eindtoets voor de course, met toepassing van de onderzochte technologie in het DevOps-beroepsproduct.
- Activiteit: Ontwikkelen van een DevOps-beroepsproduct in teams van 4-5 personen met vergelijkbaar ambitieniveau.
- Inhoud: Uitbreiding van een softwaresysteem, inclusief configuratie, images, dependencies, CI/CD, database (seed scripts), en documentatie.
- Lesuren: Voor vragen, feedback en korte workshops.
Meer info: Week 6 t/m 8 Beroepsproduct.
Week 9: Eindpresentatie en Beoordeling
-
Activiteiten:
- Eindpresentatie: Groepspresentatie met demo van het beroepsproduct en toelichting op het proces.
- Individuele sessie: Verantwoording van ieders bijdrage aan het teamproduct.
- Bezoek opdrachtgever: Oriëntatie op volgende projectfase.
-
Beoordeling:
- Criteria: Kwaliteit, kwantiteit, toepassing van DevOps 'Way of Working' (WoW) en maturity.
- Basis: Observaties van begeleiders, het werk, backlog en documentatie.
- Iteratief en incrementeel waar mogelijk, maar met geplande momenten (WaterScrumFall).
Meer info in het beoordelingsmodel (zie iSAS).
Les 0 - Intro Minor & Kick-off 2025/2026
DevOps is een cultuur van samenwerking tussen software developers en infrastructuur beheerders (=operations) en eventueel nog andere specialisten
Het doel van DevOps is om eindgebruikers waardevolle software te leveren en snel en succesvol in te kunnen spelen op veranderingen in het domein van deze software.
Kick-off Programma
Datum: Donderdag 28 augustus 2025
Tijd: 9:00-12:15
Locatie: Ruitenberglaan 26 (lokaal: zie je rooster)
| Tijd | Onderdeel | Verantwoordelijke | Opmerking |
|---|---|---|---|
| 9:00-9:45 | Intro/Overzicht minor (focus course fase) | HAN | OWE: Rooster, opdrachten, toetsing, 'hoe haal ik de minor?' |
| 9:45 | Introductie klant | InfoSupport, Sebastiaan | Welke klant van InfoSupport doen jullie de opdracht dit jaar voor? |
| 10:00 | Onderlinge kennismaking + duo's vormen | HAN | Toewijzing C#/Java v. opdracht niet vergeten |
| 10:30-10:45 | Pauze | - | Denk aan de beweegnorm ;) |
| 10:45-11:30 | Microservices Architecture Overview (project fase) | InfoSupport - Marco | Vooruitblik op te leren en te gebruiken Software Architectuure |
| 11:30-12:15 | T-shaped professional (DevOps is a culture, not a role) | HAN - Bart | DevOps is samenwerken |
Wat wordt behandeld?
- Introductie minor: Overzicht van de course fase en project fase
- Kennismaking: Onderlinge kennismaking en eventueel introductie van de klant
- Teamvorming: Vorming van duo's voor de eerste weekopdracht
- Microservices: Overzicht van microservices architectuur (project fase)
- DevOps cultuur: T-shaped professional concept en DevOps als cultuur
Voorbereiding
Geen voorbereiding, omdat dit introductie les is. Wel voor volgende lessen!
Lesprogramma
- Aanwijzingen Registratie
- Samen kijken naar de video-introductie voor de minor.
- .pdf slides/presentatie van de minor.
- InfoSupport Project Periode 2 presentatie.
PAUZE - 15 min.
- Eenvoudige spellen in de klas, in groepen werken en elkaars namen leren.
PAUZE - 15 min.
- Lesoverzicht - Samen controleren
- Introductie van de wekelijkse opdracht en hoe deze is georganiseerd.
- Hoe cijfers worden berekend voor Dev en DevOps
EIND - Mentimeter
Microservices Architecture
- Microservices in 9 Stappen
- STAP 1 - Geen Monolith maar Microservices Architecture
- Keywords:
- Modulaire Monolith
- Strangle Monolithic Application
- BFF: Backend For Frontend
- STAP 2 - Message Bus
- STAP 3 - Containerization Microservices
- STAP 4 - Naar Kubernetes met pods, services, ingress, etc.
- STAP 5 - Kubernetes Orchestration
- STAP 6 - Pipeline Code Bouwen
- STAP 7 - Image Registry
- STAP 8 - GitOps → Reconciliation
- STAP 9 - Monitoring (analytics, SlackOps)
- Keywords:
- STAP 1 - Geen Monolith maar Microservices Architecture
T-shaped professional
- 'T-shaped professional'
- Mentimeter
Leerdoelen
- Je hebt een idee van DevOps cultuur, wat een T-shaped professional is en de relatie ertussen
- Je hebt al een idee van wat een MicroService Architecture (MSA) is waar we naar toe werken in deze minor en de onderdelen hiervan
- Je kent het verschil tussen MSA en een monoliet en kent het idee van het 'Strangler' pattern
Quiz
Test je kennis over T-shaped professionals met deze multiple choice quiz:
Appendix: Optionele voorbereiding - Boekentips voor de zomervakantie
Om je goed voor te bereiden op de minor DevOps, is het een goed idee om tijdens de zomervakantie vooraf een van de volgende boeken te lezen:
📚 Aanbevolen boeken van Gene Kim
The Phoenix Project** (Roman)
- Een roman over DevOps transformatie in een fictief bedrijf
- Leert je DevOps principes door een verhaal
- Perfect voor beginners die DevOps willen begrijpen
The Unicorn Project (Roman)
- Vervolg op The Phoenix Project
- Focus op developer experience en moderne software development
- Geeft inzicht in de uitdagingen van legacy systemen
The DevOps Handbook
- Praktische gids met concrete implementatiestrategieën
- Meer technisch en theoretisch dan de romans
- Voor studenten die dieper in de materie willen duiken
🎯 Waarom deze boeken?
Deze boeken helpen je om:
- DevOps als cultuur te begrijpen (niet alleen tools)
- De uitdagingen van software delivery te herkennen
- De waarde van samenwerking tussen Dev en Ops te zien
- Voorbeelden uit de praktijk te kennen voor discussies
📖 Hoe/wat te lezen?
- Begin met The Phoenix Project als je nog weinig van DevOps weet
- Lees The Unicorn Project als je meer wilt weten over developer experience
- Pak The DevOps Handbook als je praktische implementatiestrategieën zoekt
Rubric Course (blok 1)
Berekening van de Cijfers
- Theorie Test - 50% van het cijfer
- 2 deeltoetsen (gemiddelde moet hoger dan 5,5 zijn)
- Herkansing: 1 grote toets
- Beroepsproduct - 50% van het cijfer
- 3 weken code + documentatie
- Weekopdrachten (huisopdrachten)
- 5 wekelijkse opdrachten, afvinken (=voldoende/onvoldoend), Voldoende als je oefening hebt gemaakt en feedback van anderen hebt gekregen en verwerkt.
CDMM als Beoordelingsmodel
Als beoordelingsmodel voor de weekopdrachten en het beroepsproduct (BP) dat je maakt — gebruiken we het Continuous Delivery Maturity Model (CDMM) zoals gedefinieerd in een blogpost op de website InfoQ. Deze onderscheid vijf categorieen (rijen) met elk 5 niveaus (kolommen) met een aantal 'checkpunten'.
Hieronder een korte opsomming van de 5 categorieën uit het CDMM, met per categorie een beschrijving van belangrijke aspecten. Maar moet je ook zelf de details achterhalen van de 'checkpoints', zoals onderaan de pagina verder beschreven, toegelicht onder 'DevOps concepten' op deze website, maar ook in het originele 'InfoQ' artikel (Böstrom et al., 2013).
- 🧑🤝🧑 Culture & Organization: Multidisciplinair samenwerken, conform Agile manifesto, verminderen silo's en gedeelde verantwoordelijkheid conform 'DevOps is not a role', etc. (Agile).
- ⛪ Design & Architecture: Just in time design, continuous documentation, microservice architectuur, High Availability, autonomy over authority, etc. (C4, IaC, clustering)
- 🏗️ Build & Deploy: Gescripte pipelines, continuous integration, continuous deployment, koppeling aan versiebeheer, 'automate all the things' etc. (GitOps)
- 🧪 Test & Verification: Leesbare en liefst uitvoerbare specificaties, geautomatiseerd testen, testpiramide, opstellen en meten bedrijfsmetrics, etc. (TDD, BDD, test pyramid)
- 📈 Information & Reporting Inzicht in issues/backlog, metrics vanuit productie, beeld hard- en softwaregebruik, log aggregatie, visualisatie, 'strengthen feedback loops', etc. (SlackOps)
Bovenstaand de categorieën nog even in het Engels en als toelichting een indicatie van hogere maturity per punt met wat kernpunten. Het Maturity model geeft meer stapsgewijze opbouw in niveaus met bij elk niveau checkpunten om af te vinken. Deze vind je hier CDMM CHEAT SHEET.
Om niet direct te verdwalen in het detail kun je eerst overzicht te krijgen via de toelichting in subsecties hier eronder.
- Sectie A geeft een toelichting van het gebruik CDMM als beoordelingsmodel voor cijferindicatie.
- Sectie B licht de vijf beoordelingscriteria toe die dit model bevat.
- Sectie C beschrijft de samenhang met (en mapping naar) de thema's, opdrachten en lessen van de course fase.
- Sectie D licht de indeling van de teampresentatie momenten toe.
- Sectie E iets over de impliciete aanname dat je geautomatiseerd testen en aan TDD doet.
Voor het eind beroepsproduct van de coursefase krijg je ook een individueel cijfer. Deze is veelal gelijk aan het teamcijfer, maar zoals elders is toegelicht hoe elk teamlid hiervoor de verplichte 'verantwoording van de individuele bijdrage' geeft, via een persoonlijk markdown bestand (waarvoor een template format is), en een mondelinge toelichting hierbij tijdens de Review.
A. Toelichting gebruik CDMM als beoordelingsmodel
Dit model is opgesteld voor ICT organisaties, om de fase van adoptie van DevOps patterns en het toepassen van Continuous Delivery aan te geven. In deze course gebruiken we dit ook voor bepalen van niveau van jullie als DevOps team. Je DevOps team zien we daarbij dus zien als een kleine DevOps organisatie.
Het model kent vijf beoordelingscategorieën met elk vijf beschreven niveaus: base, beginner, intermediate (=gemiddeld), advanced en expert. Voor de becijfering koppelen we grofweg een cijfer aan elk niveau:
- 😴
baseniveau cijfer**2** - 🥱
beginnerniveau, een**4** - 😐
gemiddeldniveau een**6** - 🙂
gevanceerdniveau een**8** - 😎
expertniveau een**10**
Het voldoende niveau (dus een 6) is dus intermediate oftewel gemiddeld. Hier ben je voldoende volwassen. Bij lager zit je op onvoldoende, maar dat betekent in dit geval niet dat je aanpak niet adequaat is.
Deze 'Beginner' punten moet je dus wel inrichten, dit zijn traptreden die je moet nemen naar hoger niveau. Op tenminste een aantal punten moet je ook naar gemiddeld of hoger zitten voor een voldoende. Je hebt immers een DevOps minor gevolgd, dus een bedrijf verwacht dan dat je meer DevOps kennis hebt dan de gemiddelde instappende ICT'er. Het staat de beoordelaar vrij om een tussenliggend cijfer te geven op de deelaspecten, dus bijvoorbeeld een 5, 7 of 9 is ook mogelijk (een 1 betekent dat je niks hebt gedaan of ingeleverd).
Bij de beoordeling levert de docenten/beoordelaars wel maatwerk, dus rekening houdend met omstandigheden. Bij beoordeling is het niet allen een kwestie van simpelweg afvinken, maar belangrijkste is dat je ook zelf kunt beoordelen waar je staat, de gebruikte termen goed kunt interpreteren, koppelen aan je eigen en je teams werk. Kortom dat je aantoont dat je een 'bewust bekwame' DevOps professional bent.
Verdere opmerkingen:
- Termen in
monocasefont (dus met backticks ` in markdown) verwijzen naar specifieke concepten of labels zoals beschreven in het CDMM-model. - De termen 'beoordelingscriteria' en 'categorieën' gebruiken we in de tekst als synoniemen en verwijzen naar dezelfde onderdelen.
B. De 5 beoordelingscriteria
Onderstaand de vijf beoordelingscriteria waar je in je team laten op 'intermediate' niveau moet scoren. Als indicatie een korte beschrijving en wat voorbeelden. Maar voor beoordeling moet je de hele rubric bekijken en bekijk voor uitleg van alle 'etc.' in onderstaande het originele InfoQ artikel als verdere achtergrond. Merk op dat achter elk criterium uit CDDM tussen haakjes ook een ruw equivalent van de criteria uit de OWE.
- 🧑🤝🧑 Cultuur & Organisatie - CO: DevOps is een cultuur (en geen rol). Van basis versiebeheer en ad hoc proces tot projectgebaseerde teams met volledig gedefinieerd DevOps proces. Het team heeft gezamenlijke verantwoordelijkheid en backlog en hanteert een Agile aanpak en ceremonies (bv. Scrum), etc. (DevOps-1 - Continuous Delivery)
- ⛪ Design & Architectuur - OA: Ontwerp van je software architectuur. Van monoliet naar microservices mapping op infrastructuur (evt. IaC), focus op NFR's voor bv. autoscaling, twelve-factor app principles, etc. (DevOps-3 - Containerization/Orchestration)
- 🏗️ Build & Deploy - BD: Van wat handmatige stappenplan naar volautomatische build met kwaliteitschecks en een Canary of bluegreen deploy vanuit zelf ingerichte pipeline, dev/prod parity etc. (DevOps-2 GitOps)
- 🧪 Test & Verificatie - TV: Van wat (goede) unit tests¹ naar volledige testpiramide, load tests en tests van bedrijfswaarde. De mate van TDD, acceptatietests, BDD, security, refactorings, review-proces en -inspanningen etc. (DevOps-4 - DevSecOps)
- 📈 Informatie & Rapportering - IR: Van standaard hardware monitoring naar realtime applicatiespecifieke metrics en cross applicatie en cluster informatie, A/B tests. Hoe goed monitor je de applicatie, static code analyse, loglevels/-aggregatie, productspecifieke rapportages, etc? (DevOps-4 - SlackOps)
De CDMM CHEAT SHEET is feitelijk overgenomen uit een plaatje bij dit artikel wat een samenvatting van het artikel vormt, in de vorm van afvinkbare 'checkbox punten'. Deze zijn verdeeld over vijf categorieen die elk weer vijf niveaus van 'volwassenheid' hebben.
{kind=link}
Wijzigingen t.o.v. originele CDMM
De wijzigingen ten opzicht van het originele CDMM van InfoQ zijn erg beperkt en spreken deels voor zich, maar hier voor de nieuwsgierigen.
- Ten opzichte van het InfoQ artikel is elk item/checkbox vertaald naar het Nederlands.
- Elk checkpunt nu een eigen code (bv. CO-003), die kort de categorie en het niveau aangeeft.
Tot slot zijn de volgende checkpoints in het CDMM toegevoegd:
- CO-206 Trunk based development - In lijn met punt 'CO-201 *minimale branching' is het logisch dat developers in versiebeheer zoveel mogelijk op de trunk werken (bv.
main). Zie verder het artikel hierover uit 2018 op InfoQ hierover, 5 jaar na het CDMM artikel :) (InfoQ, 2019) - Punt DB wijzigingen in VCS is verplaatst vanuit categorie 'Ontwerp & Architectuur' naar 'Build & Deploy' als BD-105 in lijn met de overige hogere checkpoints rondom 'db' zoals 'Automatiseer meeste DB wijzigingen* die ook in deze categorie staan. Deze hangen meer samen met automatiseren van deploys met pipeline en versiebeheer standaarden dan met de applicatie architectuur. Wel kun je argumenteren dat het gebruik van een ORM tool met migrations wel weer deels een (software) design of architectuur keuze is. Wel een ADR waard in ieder geval. Dan zouden BD-303 en BD-402 juist naar de categorie OA moeten, maar i.v.m. consistentie doen we dit niet.
- Punt CO-302 'Strict API based approach or message bus/broker ingevoegd, in verband met missende focus van InfoQ op gebruik Message bus/broker.
Gebruik checkpunten voor self assessments
De checkpunten ga je gebruiken in de weekopdracht en beroepsproduct, maar het is wel de bedoeling naast de code OOK de naam op te nemen in je eigen product documentatie, toelichting bijdrage team en dergelijke. Dus NIET enkel de code, want dan wordt het erg cryptisch (en moet de lezer dit weer opzoeken).
Bijvoorbeeld:
Het gezamenlijk zelf komen tot een besluit tijdens de sprint retrospective — in plaats van naar de PO te kijken voor een besluit — zien wij als voorbeeld van CDMM CO-206 - Decentrale besluitvorming). Dit toont aan dat wij als team al voldoende scoren op criterium Cultuur en Organisatie.
Op een eventuele vraag van de beoordelaar waarom jullie dan nog niet 'handelen op metrics' (C0-203) moeten je dan zelf idealiter een antwoord formuleren (wellicht is "Promotheus doen we pas in week 5" een goede verdediging ;))
C. Mapping van de 'CDMM checkboxes' op de weekthema's/-opdrachten
Tijdens de lesweken in de course fase richt je in opdrachten vooral op stappen Basis en Beginner. Tijdens het DevOps beroepsproduct ontwikkeling (laatste 3 weken) ga je je als het goed is ontwikkelen naar hoger niveau een of manier criteria (maar tenminste vormbehoud).
Hieronder een klein opzetje van de mapping. Merk op dat het merendeel van de checkboxes nog ingedeeld moet worden. Waarbij je sommige in twee of meer categorieen kunt/moet indelen (zoals BD-207 'standaard proces voor alle omgevingen' in containerization en Continuous Deployment en OA-103 in containerization en devSecOps).
- Wk1 - GitOps: CO-003, BD-001 Code in versiebeheer, BD-103 Handmatige tags en versies, BD-201 Auto triggered builds (commit hooks), TV-001 Automatische unit tests, IR-102 Statische code analyse, TV-201 Automatische component test (geisoleerd), ...
- Wk2 - Containerization: OA-103 (3rd party) library management, BD-203 Build once deploy anywhere, BD-204 Automatiseer meeste DB wijzigingen, BD-206 , BD-401
- Wk3 - Continuous Delivery/BDD: CO-001, CO-101, BD-205, BD-206, IR-101, IR-202, TV-301 ...
- Wk4 - Rabbit MQ: CO-105 Testen onderdeel van development, OA-201 Geen of minimale branching, OA-301 Volledige component gebaseerde architectuur, TV-101 Automatische integratietests, TODO OA-302 Strict API based approach or message bus/broker
- Wk5 - Orchestration/DevSecOps: OA-201 Geen of minimale branching, TV-002, TV-303, TV-304, OA-103, ...,
D. Beoordelingsmomenten
De beoordeling van dit beroepsproduct gebeurt op basis van 3 onderdelen. Deze komen langs twee beoordelingsmomenten; een Productdemo en een Code review. Hier een overzicht met ook beoordelingscriteria per onderdeel.
- Productdemo Het tonen van het product en het updaten en live monitoren ervan tijdens een korte teamdemonstratie voor beoordelaar(s)/opdrachtgever
- Code review Product en code/config review. Langer overleg met alleen team en beoordelaar(s):
- toelichting individuele bijdrage
- vragen van beoordelaars
- bespreking van jullie self assessment b. Kwaliteit van proces, README en de verdere achterliggende documentatie
- verloop sprints en Scrum ceremonies
- doornemen scrumborden, issues, user stories, traceerbaarheid wijzigingen via issues, commit messages, pull requests en review opmerkingen
- doornemen/toetsen README en begrijpelijkheid documentatie (C4 + UML en overige diagrammen en (verplichte) tekstuele toelichting)
D1. Productdemo Toelichting
De productdemo duurt circa een kwartier en daarna max een kwartier vragen. De presentatie gebeurt voor de beoordelaars. Omdat jullie in principe op basis van een redelijk bekende product hoef je aan introductie hiervan niet veel tijd te bestenden en licht je vooral je eigen uitbreiding hiervan toe, en demo't deploy van product increment en monitoring hiervan.
Voordat de demo is doe je met het hele team een self assessment van het gemaakte DevOps product en gevolgde proces en vult in een self-assessment.md voor alle 5 BC's een cijfer in op basis van niveaubeschrijvingen in de rubric in. Je schrijft hierbij ook een argumentatie voor de invulling, met enkele steekwoorden per BC en ook een of meer paragrafen voor de eindcijfer.
Bij beoordeling geldt dat alle te beoordelen zaken aanwezig zijn in ingeleverde beroepsproduct en ook in je documentatie te vinden zijn. Je werkt dus NIET in Word documenten, maar in tekst en markdownbestanden geintegreerd samen bij de broncode en configuratiebestanden.
Merk op dat de beschrijvingen van de 'lagere niveaus', basis, en beginner niet per se tekortkomingen beschrijven, maar ladders zijn op een trap die je moet nemen richting een voldoende en hopelijk zelfs goed cijfer. Op een aantal criteria zit je gelukkig wel al direct op een 6 door bijvoorbeeld gezamenlijke backlog voor DevOps te gebruiken en een Test en/of Behaviour Driven aanpak te gebruiken.
Als gezegd moet je alle belangrijke zaken, zoals behaalde non functional requirements, of je proces als DevOps team ook zelf kort beschrijven in je documentatie. Je moet ook weten waar je zelf staat. De niveaubeschrijvingen zijn geen kant en klare recepten, dus je moet zelf ook een interpretatie hiervan doen en invulling. Bij twijfel stem zaken - als het goed is vooraf - af met de beoordelende docent(en). Het expert (=extreem) niveau dat bij een 10 en hierbij ga je above en beyond, dus moet je ook zelf aangeven waarom je op het niveau zit.
D2. Code Review Toelichting
Bij een tweede langer assessment met alleen de docenten en je team gaan we ook in op kwaliteit code, match configuratie met infrastructuur model en gewenste NFR's? Als intro hiervoor bespreken jullie de grove rol- en werkverdeling en elk teamlid geeft toelichting van eigen bijdrage in het product (minstens 1 bijdrage waar je trots op bent, en kwaliteit kunt beargumenteren en een stuk werk waar je concrete verbeterpunten kunt noemen).
De kwaliteit van de README beoordelen docenten bijvoorbeeld door terplekke zelf de code te pullen uit versiebeheer en containers of clusters te runnen o.b.v. jullie README. En daarnaast te bekijken of documentatie voldoende aangrijpingspunten biedt voor nieuwe developer in team om het product snel te begrijpen en aan verder te bouwen.
Voor individuele beoordeling geef je verantwoording van je eigen bijdrage in het groepsproduct en bv. aan de hand van je markdown document ook meer details van het toepassen van de onderzochte technologieen uit de spike. Als gezegd hebben deze tools/technologieen hopelijk een positieve uitwerking op je eindproduct gehad. Denk aan verbeterde/makkelijkere monitoring, hogere productiviteit, betere security, betere code kwaliteit, geautomatiseerde pipeline etc.
D3. Eindcijferbepaling en wegingsfactoren
Tot slot nog evenover de weging; om dit EXPLICIET te maken: er is GEEN hard voorgeschreven weging tussen de 5 beoordelingscriteria om tot een eindcijfer te komen. Normaliter zullen alle vijf de criteria even zwaar wegen, en is er vaak een lijn qua product. En geeft een onvoldoende op een aspect reden tot twijfel. Maar het gaat meer om je eigen beoordeling en - vooral - beargumentering hiervan. Daarom moet je ook een self assessment doen; zie onder.
Het kan zijn dat sommige aspecten minder van belang waren in jullie opdracht en op zichzelf onvoldoende waren. Maar het overall toch voldoende was doordat een ander aspect buitengewoon goed is gedaan, of zaken door externe en niet te voorspellen zaken juist erg tegenvielen.
Merk ook op dat het eindproduct zelf geen eigen cijfer krijgt. Dit is bewust (dit is overigens tijdens projectblok anders, waar de opdrachtgever ook een deelcijfer geeft). Geen cijfer voor eindproduct betekent natuurijk NIET dat je geen product increment moet hebben. Dit is verplicht. Maar we willen niet dat je inzet op heel complexe functionaliteit en daarbij de DevOps basics uit het ogen verliest. Of bv. logging of monitoring aan de kant schuift. Maa zonder product (increment) is er geen proces. En beter product en logische 'bedrijfswaarde' geeft meer gelegenheid DevOps skills te tonen en een betere demo en leidt indirect toch tot een hoger cijfer.
Bijvoorbeeld een groter product increment of uitgebreide refactoring in bestaande code of opsplitsen van microservice in 1 container in 2 aparte, geeft ook een langer commit spoor, meer unit tests, een aanleiding voor extra Q&A omgeving, een demo canary deploy voor subfunctionaliteit I, een A/B test van een andere functionaliteit, data migratie van feature X, en (zelf onderzochte) InfraStructure As Code configuratie voor microservice Z. Een groter product increment geeft natuurlijk ook meer aanleiding voor een complexere architectuur. Ga je voor een simpele CRUD microservice, of kies je juist complexe logica die ook een 'domain driven' ontwerp vraagt, met wellicht caching in miroservice en synchronisatie tussen microservives, een event-driven en/of CQRS aanpak met eventual consistentie, inzet van een message broker etc.
E. Speciale noot over (geautomatiseerd) testen
¹ Merk tot slot op dat het instapniveau (dus 2) niveau qua Test en Verificatie direct 'code is onder test', dus geautomatiseerde tests. Terwijl dit in het beroepsveld lang nog niet bij alle bedrijven gebeurt. In de course gaan we in op BDD (ook wel ATDD = Acceptance Test Driven Design of 'Specification by Example' genoemd), waar ISM studenten ook nog een rol bij kunnen spelen in het opstellen. Maar er is in de minor binnen contacturen niet de tijd om TDD 'vanaf de grond' aan te leren. Maar TDD en gerelateerde patterns en principe als Arrange, Act, Assert (AAA) en Red, Green Refactor veronderstellen we wel als bekend bij developers. Zorg dat je hier ook mee geoefend hebt, of alsnog oefent!
Continuous Integration is a software development practice where members of a team integrate their work frequently, usually each person integrates at least daily - leading to multiple integrations per day. Each integration is verified by an automated build (including test) to detect integration errors as quickly as possible.
De grondlegger van de term Continuous Integration Martin Fowler hamert in vele van zijn blogs op TDD aanpak en legt in blog met titel 'Is high quality software worth the cost?' aan dat deze vraag op een verkeerde veronderstelling berust, omdat kwaliteitssoftware juist goedkoper is om te onderhouden in plaats van duurder (zie figuur 1).
Figuur 1: High (internal) quality software is goedkoper i.p.v. duurder! Aldus Martin Fowler (2019).
In deze lijn trekken in de DevOps wereld over het algemeen door, bv. Continuous Delivery voorman David Farley (van het gelijknamige 'seminal' boek). Met 'goed' bedoelen we hier:
- behoorlijke test coverage, in ieder geval van complexe code (hoge cyclomatische complexiteit)
- leesbare testcode met cyclomatische complexiteit van 1)
- gericht op gedrag en testen van interface i.p.v. implementatie details
- en zonder 'unit testing anti patterns' (zoals 'Liar', 'Excessive setup', 'The giant' en 'The mockery' zie deze video van David Farley).
Bronnen
- Boström, P & Palmbor., T 6 februari 2013. The Continuous Delivery Maturity Model, geraadpleegd 13-1-2021 op https://www.infoq.com/articles/Continuous-Delivery-Maturity-Model
- Fowler, M. 19 mei 2019, Is high quality software worth the cost. Geraadpleegd 20-10-2021 op https://martinfowler.com/articles/is-quality-worth-cost.html
- InfoQ (2018). Trunk Based Development as a Cornerstone for Continuous Delivery. InfoQ.com. Geraadpleegd 5-9-2024 op https://www.infoq.com/news/2018/04/trunk-based-development/
DevOps lijst van concepten
Onderstaande tabel bevat een lijst van woorden, of — beter — concepten (want een concept bestaat soms uit meerdere woorden). De tabel bestaat nu vooral uit een toelichting op de checkpunten uit het CDDM beoordelingsmodel. Voor het beantwoorden van vaker terugkomende vragen zoals:
Wat wordt er bedoelt met het punt BD-203 - Build Once deploy anywhere?
Hoe dan ook, van deze termen moet je de betekenis kennen als je de minor hebt gevolgd. Alleen de uitleg in de tabel lezen is niet altijd voldoende voor goed begrip. Je moet ook de context uit de les erover kennen. Maar het kan wel een begin zijn, of manier om snel iets terug te zoeken.
Toelichting
In de DevOps minor leer je DevOps tools en DevOps concepten. Nu zijn tools meestal tijdelijk, zeker in een snel ontwikkelend vakgebied als DevOps. Maar (basis) concepten hebben een veel langere houdbaarheid, goede concepten zelfs oneindig...
Figuur 1 toont ludiek wat termen uit het wild, waar je ook veel buzzwords tegenkomt. Als DevOps professional moet je onderscheid kunnen maken tussen waardevolle concepten, en buzzwords.

In ieder geval is het doel wel dat deze termen ook aansluiten bij de beroepspraktijk en bestaande DevOps terminologie. De meeste woorden zijn dan ook Engels.
Hoewel de meeste feitelijk ook Nederlands zijn, of feitelijk deel uit maken van de internationale DevOps taal of jargon. Idealiter, als een concept een goede 'semantische' naam heeft, is ook voor ICT'ers de Van Dale soms een aardig begin. En zou je de originele betekenis/oorspring niet altijd terug moeten zoeken ('Death of the author' principe). Maar in de praktijk is vaak enkel de termn maar is dit niet toereikend heb je meer bronnen nodig om deze` goed te begrijpen (zie het voorbeeld uit figuur 3).

Figuur 2: Discussie thread op Twitter X over 'deployment' vs. 'release' (bron: Steve "ardalis" Smith 9-11-2023 op X)
Het plaatje in Figuur 2 toont een (vrij) recente discussie rondom checkpoints CO-302 uit het CDMM.
| Concept/begrip | Uitleg |
|---|---|
| DevOps | Cultuur van samenwerken |
| Green field vs. brown field | Nieuwbouw project vs bestaand project en/of nieuwe/nieuwste technologie vs legacy technologie. |
| TODO | ... |
| OA-001 Geconsolideerd platform & en technologie | Dit betekent dat je als organisatie een keuze hebt gemaakt qua technologie, meestal met erbij horende training, ervaring van huidige medewerkers. Bijvoorbeeld Java, of dotNet. Of Wordpress voor simpele corporate sites maar SiteCore voor complexere sites, en of multi-tenant opdrachten. Dit hoort bij lagere niveaus, omdat je bij microservices aanpak juist 'Polyglot X' kunt doen, zoals InfoSupport dat noemt, om programmeertaal of stack te laten varieren per microservice. Maar aanname is hierbij wel vaak weer een basis technologie als Kubernetes of Docker Swarm o.i.d die deze polyglot X mogelijk maken. Kortom: deze krijg je eigenlijk gratis bij gebruik PitStop, mits je gebruikte technologie maar documenteert. |
| BD-006 Enkele deployment scripts bestaan | Dit zijn wat handmatige deploy scripts die als basis kunnen dienen voor automatisering op de hogere levels (e.g. 'automate all the things'). |
| BD-101 Polling builds | Ik ga uit dat dit polling model is waarbij in plaats van dat je 'git distribution' (bv. GitHub met GitHub Actions) recht geeft te pushen naar de (runtime) omgeving via opslaan credentials o.i.d., er een tool is op een andere plek, buiten je Git systeem, (bv. ArgoCD), die periodiek checkt (bv. elke minuut) of er in je Git repo of ander versiebeheer een nieuwere versie staat en zo ja dan die code pakt, build en containerized en evt. test. Merk op dat het testen van de build onlosmakelijk verbonden is met Continuous Integration in de definitie van Martin Fowler’s hiervan: "Each of these integrations is verified by an automated build (including test) to detect integration errors as quickly as possible." |
| BD-203 Build Once Deploy Anywhere | Het Build Once Deploy Anywhere (BODA) principe houdt in dat je één keer een artefact bouwt. Zoals een .jar, .war, maar in de container age is dit natuurlijk een Docker-image (met daarin een .jar of andere applicatie), en ditzelfde artefact gebruikt voor alle omgevingen: van test en staging tot productie. Je koppelt een specifieke commit aan het artefact en automatiseert tagging en versiebeheer, zodat je elke build uniek kunt traceren.Je beheert configuraties buiten het artefact via omgevingsvariabelen, in lijn met het 12 Factor App-principe. Door configuraties niet hard mee te bouwen, voorkom je de noodzaak om omgevingsspecifieke artefacten te maken, zoals spotitube-prod.war of spotitube-staging.war. Met één geteste en goedgekeurde build kun je direct deployen naar productie, zonder opnieuw te bouwen. Je standaardiseert het deploymentproces over alle omgevingen. Dit proces omvat ook geautomatiseerde database-migraties en gescripte runtimeconfiguratie-aanpassingen. Door deze aanpak creëer je een uniforme delivery pipeline die alle stappen omvat: van source control tot productie. Dit minimaliseert fouten, verhoogt de betrouwbaarheid en versnelt het deploymentproces. Met tools zoals ArgoCD en andere CI/CD-oplossingen automatiseer je het combineren van configuraties met de artefacten en rol je deze efficiënt uit naar meerdere omgevingen. Dit is logisch voor verdere standaardisatie, maar is in Cloud tijdperk nog lang niet altijd standaard bij bedrijven (blog). |
| BD-204 Automatiseer meeste DB wijzigingen | Dit punt kun je bv. afvinken met het gebruik van de in de course fase (kort) behandelde Entity Framework (EF) Code first aanpak. Deze ondersteunt (automatische) data migraties (o.b.v. een 'single source of truth', namelijk de code). Maar alleen het gebruik van EF is voor dit punt echter niet voldoende. Je moet dan ook minstens één voorbeeld hebben van een daadwerkelijke en 'niet triviale' data migratie. Vaak hebben teams een standaard migratie voor het opzetten van de initiële database. E.g. een migratie van 'niets' naar iets. Of deze is evt. opgesplitst in een 'create' stuk en een 'insert' migratie, maar ook dat is nog triviaal (e.g. simpel). 'Niet triviaal' wil zeggen dat je de databasestructuur verandert door bijvoorbeeld een tekstveld om te zetten naar een foreign key naar een stamtabel (vaak hoort hier wijziging in de UI bij van een vrij tekstveld naar een dropdown, en/of back-end veld omzetten naar Enum i.p.v. String o.i.d.). Bij deze structuur wijziging moet je ook bestaande data migreren in je Up() én Down() methode. Of alles goed gaat moet je dan vervolgens testen, en typisch is handmatig schrijven van wat migratie code nodig. Voor afvinken moet je zo'n (voorbeeld van) een migratie ook kort toelichten in je CDMM of elders. Helemaal interessant maak je het als je een serie van wijzigingen hebt die je apart lokaal test, maar vervolgens op een test omgeving gecombineerde doorvoert (migreert) en test, liefst ook tegen kopie van productie, of gelijkwaardige set om te voorkomen dat je dit als eerste op productie doet en hierbij pas eventuele integratie problemen optreden. Let wel, dat dit is in een kleine project wel lastig te verwezenlijken. Dit vraagt ook een goede toepassing binnen het domein en afstemmen met de opdrachtgever. Als er voor de opdrachtgever geen winst in de nieuwe datastructuur zit, is de effort moeilijke te verkopen. Voor dit punt helpt het wel om heel vroegtijdig live gaan (in week 1 of 2) met een simpele datastructuur en ook bijbehorende test dataset. En hierop ook de opdrachtgever of andere testers laten werken om productie achtige gegevens in te voeren. Op deze test data kun je daarna je (niet triviale) migratie kunt doorvoeren. |
| BD-206 Gescripte config wijzigingen | Als je config wijzigigingen gescript hebt, kun je dit script testen op een test omgeving, en checken dat config wijzigingen doen wat je wilt, voordat je het op productie ook doet. Voorkomt fouten en zorgt voor herhaalbaarheud. Versnelt ook het proces, omdat je niet handmatig stap voor stap de config wijzigingen uit moet voeren, of op productie foutgevoelig met een editor config aanpast. |
| CO-201 Multidiscl. team (betrekken DBA, CM) | In plaats van een aparte developer team en operations team (die CM=Configuration Management) doen. En wellicht ook aparte DB admin of admins, plaats je iedereen in het team, zodat mensen vroegtijdig(er) overleggen (shift left), en wijzigingen niet tijdens deploy aan het eind vastlopen, omdat een probleem bovenkomt die iemand van andere discipline had kunnen zien aankomen. Denk bijvoorbeeld ook aan security mensen (e.g. van DevOps naar een DevSecOps team). |
| CO-202 Component eigenaarschap | Hoewel het hele team verantwoordelijk is voor alles, is het wel goed om een of enkele mensen eigenaar te maken van een component. Denk bij een component bijvoorbeeld aan een microservice. Dit sluit ook aan bij de 'Pizza rule' uit DevOps (NetFlix): het team verantwoordelijk voor 1 microservice moet (bij onderhoud) aan 1 pizza genoeg hebben. Dus 2 of 3 mensen? |
| CO-203 Handelen op metrics | Studenten vraag: > "[...] Hoe zouden wij dit moeten uitvoeren in dit project? We hebben niet echt gebruikers waarop we kunnen reageren." Antwoord: Als er geen echte gebruikers zijn, moet je deze faken. Sowieso is het een best practice om een test dataset aan te leggen in een database of andere data storage. Ook om je requirements duidelijk te krijgen, en gekozen abstracties te testen. Dit onder de noemer “Sometimes three good examples are more helpful to understand the requirements than a bad abstraction.”' - Peter Hruschka (domainstorytelling.com, 2023). |
| CO-206 Decentrale besluitvorming | Agile is naast cross-functional en collaberatief ook niet hiërarchisch (Wrike, z.d.). Er is dus NIET één baas, voorzitter of product owner die alles beslist. De product owner is weliswaar verantwoordelijk voor het houden van overzicht van het product en WAT erin komt. Maar HOE je dit realiseert besluiten de teamleden samen, en voor decentrale besluitvorming betekent dit dat een beslissing idealiter bij de persoon die de meeste relevante kennis heeft, qua domein en/of technisch (zie ook <a href="CO-202>CO-202 Component eigenaarschap). Een probleem kan ook om 3:00 's nachts optreden, en idealiter kan er op dat moment ook een beslissing genomen worden om het op te lossen, zonder 'de baas' uit bed te bellen om een beslissing te nemen over wel/niet release van een fix en evt. release. Wel houdt CO-206 in dat je ook samen een proces opzet, waarbij je met hele team later bv. een post mortem over zo'n issue houdt, en meer structurele fix inplant, na een nachtelijke work-around/bugfix, en bv. ook je (DevOps) proces optimaliseert om kans op een soortgelijke fout later te verkleinen. Terzijde: er is ook een interessante link tussen 'decentralized decision making' en het concept 'epistocracy' zoals beschreven door Jason Brannon in zijn 'scherpe' boek 'Against democracy' (2017, voor de duidelijkheid: geen ICT boek :P). |
| CO-301 Dedicated Tools team | Er is een apart team in het bedrijf dedicated gericht op DevOps tools inrichten, beheren en onderzoeken. Sinds circa 2022 kwam dit principe ook onder de noemer Platform Engineering naar voren (State of DevOps, 2023). Dit houdt in dat er één apart team verantwoordelijk is voor het 'platform' waarop de IT draait. Dit lijkt op een soort interne 'Platform as a Service (PAAS)', maar sommigen spreken liever van 'Platform as a Product' (taloflow.ai, 2024, teamtopologies.com, 2021). Of pessimistisch (of realistisch?) gezegd: Het team van 'DevOps tools experts' is zo druk met hun werkzaamheden, dat ze geen tijd meer hebben voor ontwikkelwerkzaamheden in regulier teams. NB: Merk op dat het woord 'apart' een beetje indruist tegen de 'DevOps cultuur' van 'break down silo's. En een 'specialistisch' team gaat ook tegen het multi-disciplinaire karakter van DevOps teams, waarbij ook juist een Polyglot X aanpak mogelijk is. Dus dat elke deelapplicatie/microservice een andere techniek heeft (the right tool for the right job). Ook bij polyglot X is echter het (container) platform meestel wel geconsolideeerd (dat wil zeggen er zijn regels over, zodat alle teams in het bedrijf dezelfde taal en frameworks gebruiken). Dit is bijvoorbeeld Kubernetes en de de DevOps aanpak geeft veel nieuwe andere tools en technologie die aansluiten bij DevOps zoals Git, Kubernetes, Ansible, Argo. Iedereen kent de basis, maar een expertise team op dit gebied levert voor grotere bedrijven wel winst op. |
| CO-304 Continuous improvement (Kaizen) | Creëer een cultuur van continue verbetering waarin alle medewerkers actief bijdragen aan verbetering; voed deze cultuur met events gericht op specifieke verbetergebieden (Vorne Industries, z.d.). |
| CO-303 - Deployment loskoppelen van release | Hoewel ICT'ers de termen 'release' en 'deployment' vaak als synoniemen gebruiken, geeft dit CDMM checkpoint aan dat een volwassen DevOps deze 2 van elkaar los kan koppelen. Een release is een set samenhangende wijzigingen, een product increment in Scrum termen. Het 'increment' samen met het product samen leidt tot een potentially shippable product. Een nieuwe versie van je applicatie. Het 'potentially' stelt eisen aan dat de nieuwe features (voldoende) bugvrij zijn, en samenhangend. Maar het laat dus vrij of je de nieuwe versie ('release') daadwerkelijk beschikbaar stelt voor naar eindgebruikers ('productie'). Dit is dan een 'business beslissing'. Het loskoppelen heeft twee varianten. Je kan er de nieuwe release alleen deployen op een (accceptatie test omgeving, en dan beslissen er op door te itereren door nieuwe inzichten die je krijgt. Je kunt ook via bv. een 'dark release' of 'feature toggle' de onderliggende code van de functionaliteit wel degelijk opleveren, maar deze nog niet activeren (feature toggle) of bereikbaar maken (dark release). Het 'loskoppelen' gaat erom dat je dit makkelijk in kunt stellen, zodat de twee concepten 'release' en 'deployment' duidelijk van elkaar gescheiden zijn. Zie figuur 1. |
| CO-402 Cross Silo analysis | Dit punt uit Information & Reporting is geavanceerd en vereist de nodige domeinkennis en overzicht van de organisatie. Dit punt is gelieerd aan Conway’s Law over de link tussen de structuur van de applicaties/microservices en de structuur van de organisatie die de applicaties gebruiken/laten bouwen. Basis eis is dat je meerdere microservices draait die Kan je systeem ook metrieken rapporteren waardoor je verbanden tussen verschillende organisatie onderdelen (silo's) kunt zien? Dat je organisatieonderdelen onderling kunt vergelijken op bepaalde aspecten? Zulke informatie geeft voor een bedrijf vaak optimalisatie mogelijkheden. Zoals InfoQ aangeeft: "Moving to expert level in this category typically includes improving the real time information service to provide dynamic self-service useful information and customized dashboards. As a result of this you can also start cross referencing and correlating reports and metrics across different organizational boundaries,. This information lets you broaden the perspective for continuous improvement and more easy verify expected business results from changes." |
| OA-001 Geconsolideerd platform & technologie | Een bedrijf kiest voor een enkele technologie, of combi van bij elkaar passende technologieen (e.g. stack) voor alle applicaties. Bv. Windows (platform) en GEEN macOS. Of programmeertaal/ontwikkelomgeving .NET. Dus een medewerker kan dan niet bij een nieuwe opdracht opeens Java kiezen, ook al is er wellicht een library in Java die al 50% van de requirements vervult, die er (nog) niet voor .NET is. En een developer kan ook niet een Elixir project kiezen voor opdracht waar dit past (maar hoge concurrency eisen bv. proberen te voldoen via gebruik RabbitMQ). Of "Geen MySQL, want "we hebben een SQL Server licentie, en 3 DB admins met MS DP-300 certificaat. Dit is erg pragmatisch en komt dus veel voor, want geeft standaardisatie, maar is tegelijkertijd wel de tegenhangen van de Polyglot X aanpak die DevOps in principe mogelijk maakt (merk op dat Polyglot X zeker niet verplicht is bij DevOps). |
| CO-402 No rollbacks (always roll forward) | Dit checkpunt vereist wat zelfstudie, want dit punt vraagt wat verdieping en kun je over discussieren. Lees bijvoorbeeld kritische beschouwing van Jim Bird over roll forward en andere DevOps best practices of misconcepties (Bird, 2011). Dit punt moet je discussieren en toelichten als je dit punt wilt afvinken in je CDMM, met liefst beschrijving van eigen concrete situatie in je software ontwikkeltraject waar je een roll forward deed, of juist automatische rollback kon doen, en hoe dan. |
| OA-102 API-gestuurde aanpak | De microservices praten met elkaar met (geconsolideerde) interface, bv, RESTful API's of service bus (of RabbitM!). Dit maakt PolyGlot X aanpak mogelijk, niet alle applicaties hoeven bv., meer in Java (voorloper aanpak voor innovatie is andere taal op zelfde Virtual Machine zoals JVM (met Java, Kotlin, Scala)) of .NET met C#, F# of VB.NET voor CLR. |
| OA-203 Configuration as Code (CaC) | De (software) configuratie van een applicatie staat OOK in versiebeheer, zodat je het verloop hiervan over de tijd kunt zien en terugvinden (ivm auditing ook: wie heeft op 28 oktober deze setting aangepast?). Evt. kan configuratie hierbij in aparte repository staan dan code in verband met security, waar andere mensen (dan developer) verantwoordelijk voor zijn (denk aan connection strings die anders toegang tot productie db zouden geven (niet confogm AVG/GDPR)). Denk bij configuratie aan welk OS, welke software/middleware, maar ook zaken als welke software instellingen zoals IP adressen van machines). Verder kun je naast configuratie van applicatie zelf, ook denken aan configuratie van bijvoorbeeld een deployment pipeline die je applicatie build uit de code en oplevert naar een (runtime) omgeving. CaC vraagt dus de 'scripted pipelines' van Jenkins 2.0, de oude 'via UI' manier in Jenkins 1.0 geldt niet als CaC (maar wellicht kun je via UI ingestelde settings wel exporteren en dan inchecken in VCS en daarna hiermee verder werken). Hier is verder veel online over te vinden. |
| OA-204 Feature hiding (feature toggle e.d.) | Functionaliteit kan gedeployed zijn maar nog niet zichtbaar of geactiveerd voor eindgebruikers. Met een feature toggle schakel je codepaden aan/uit of kies je varianten (A/B). Dit maakt het mogelijk om release los te koppelen van deploy en om veilig te experimenteren (bv. dark release). Voorbeeld van een eenvoudige toggle in Java/Spring staat in de les over Git workflows: feature toggles – Java voorbeeld. |
| OA-205 Modules omzetten naar componenten | De monoliet is al wel modulair opgezet, de bestaande modules hang je in eigen microservice, bv. met eigen Docker container, zodat je ze los van elkaar kunt gaan opleveren. Heeft als potentieel probleem wel 'testing pyramid of hell'  |
| OA-301 Volledige component gebaseerde architectuur | Next level van OA-205, met het 'strangle pattern' is een evt. oude monoliet (volgens 'monolithFirst' aanpak van Fowler) volledig omgezet in microserves |
| OA-302 Strict API based approach of message bus/broker | 'API‑first' (regelmatig gezien als een “13e principe” aanvullend op 12‑Factor) betekent dat je het contract vóór de implementatie ontwerpt en vastlegt (bijv. met OpenAPI voor sync HTTP of AsyncAPI voor events). Dit stimuleert loskoppeling, contract‑testing, documentatie en polyglot teams. Bij event‑driven integreer je via een broker (bijv. RabbitMQ/Kafka) met publish/subscribe i.p.v. point‑to‑point calls, wat back‑pressure en resiliency vergemakkelijkt. |
| OA-303 Graph business metrics uit applicatie | Naast de standaard metrieken die bv. Grafana kan geven van cpu, geheugen en bandbreedte gebruik heb je ook custom metrics gemaakt, die ook voor de business waarde hebben. En die frequent geupdate zijn, zodat business hierop ook kan sturen, en experimenten kan doen qua business logica in de markt en zien hoe deze uitpakken (bv. A/B testen). |
| BD-104 1e stap naar standaardisatie deploys | Meerdere teams gebruiken zelfde stappenplan voor deploy (bijvoorbeeld een geconsolideerde 'tech' keuze is SQL Server als database, en men switcht van .bak bestanden naar nieuwe BacPac) en/of gebruikt Azure Cloud voor alle producten. |
| BD-206 Gescripte config wijzigingen | De bij BD-203 genoemde config (bv. systeemvariablen) test je ook op een test omgeving VOORdat je op productie test door een script te maken die je kunt uitvoeren. Dit sluit aan bij het 12factor principe van one off Admin processes. Onder config wijzigingen kun je overigens naast omgevingsvariabelen ook andere config denken, zoals update van dependency bij security issue, maar bv, zelfs aanpassingen aan het database schema zien (SQL DDL scripts). In een ORM gebruik je hiervoor bv 'db migration scripts/code. |
| BD-401 Build bakery | Dit is een heel breed onderwerp, wat teruggaat naar de begintijd van Virtualisatie, met Amazon Machine images, maar wat feitelijk volwaasen is gemaakt door container registries en runtimes a la, waarbij je bv. een door veel applicatie hergebruikte base image hebt, met aparte config voor de specialisatie ervan (e.g. Dockerfile met CMD apk install tool-x). Vink dit punt NIET zomaar af als je Docker gebruikt, maar verdiep je in bron en argumenteer zelf waarom je hieraan voldoet. |
| BD-402 Zero touch continuous deployment | Geen handmatige inmenging meer nodig voor een deploy, een commit leidt automatisch tot nieuwe versie op productie, idealiter met gradual release maar dat valt hier niet bij, via de pipeline (mits linting, unit tests, automatische integratie tests etc. ). Merk op dat in projecten waar nog handmatige tests zijn dit niet altijd gewenst is, maar idealiter gebeurde dit plaats op test omgeving, en kun je via BODE principe (BD-203) risicoloos ermee naar productie via commit op main. |
| TV-201 Automatische component test (geisoleerd) | Geautomatiseerde integratie en/of UI test van een microservice, waarbij gebruikte dependent microservice gemockt zijn |
| IR-101 Meet het proces | InfoQ heeft bij het 'measure the process' stuk het voorbeeld van een aantal metrieken rondom het software ontwikkelproces zoals cycle-time of delivery time. Het proces meetbaar maken betekent dat je weet hoe lang een release duurt, dus het runnen van de pipeline. Of dat je weet hoeveel bugs er open staan op een component. En wat de gemiddelde fix tijd van een bug is. Of hoeveel bugfixes er in een release zitten. Het uberhaupt in kaart brengen is het begin van ook weten waar bottlenecks of probleemgebieden zijn in je software landschap. Waar zitten de moeilijke onderhoudbare 'big ball of mud' monolieten. Of welke modules leveren vaak bugs op. En voor de release van welke service moet je altijd een paar developers klaar hebben. Meet het proces gaat echter alleen over het inzichtelijk hebben van zulke informatie, en nog niet over het verbeteren op basis hiervan. |
| IR-201 Gedeeld informatie model | Dit punt is op twee manieren op te vatten. De eerste, zoals binnen InfoQ's artikel vooral bedoelt gaat het over het informatie model van het software ontwikkelingsproces zelf. Zoals je ook metrieken voor bepaalt onder IR-101. Dit informatiemodel gaat over releases, indienen van bepaalde requirements, deze formuleren als requirements en hier bijvoorbeeld unit tests of acceptatie tests voor opstellen. Ook het indelen van de software in modules of componenten (=typisch microservices), en dan de namen van deze microservices of modules. Dit is dus op meta niveau ten opzichte van het 'domeinproces' waarover de ontwikkelde applicatie gaat, en waarop ook een informatiemodel van toepassingen is. Dit gaat dan om entiteiten en hun eigenschappen zoals zichtbaar in het domeinmodel. Om aan te kunnen geven hoe het release proces verloopt, welke feature net is gereleased, of voor een komende release gepland is, of hier nog issues voor open staan, of om terug te zoeken op welke omgeving het staat, of wie dit daar gedeployed heeft, moet iedereen (of in ieder geval de juist mensen) dit terug kunnen halen uit bijvoorbeeld een code mangement systeem, een log van gedraaide pipelines, of overzicht van containers en hun versies in een container registry. Voor dit punt kun je ook denken aan het informatiemodel van de applicatie en van het domein en diens subdomeinen zelf. Denk hierbij aan DDD's ubiquitous language. Dit is een door iedereen gedeelde lijst van woorden, e.g. een 'alomvertegenwoordige taal' in een organisatie. Deze gebruiken dus zowel business mensen tijdens het werk, als developers in hun broncode (class names, foldernamen, variabele namen, methodenamen etc.). Dit houdt in dat de hele organisatie bedoelt hetzelfde met een bepaalde term. Of als één term meerdere dingen betekent in verschillende contexten, zoals bijvoorbeeld verschillende afdelingen van het bedrijf, dan zijn deze (bounded) contexts duidelijk en bekend, en is voor elke context een definitie van de term. In een microservice architectuur heeft idealiter elke microservice eigen opslag (autonomy over authority) en synchroniseer je geen informatie direct via de database (maar heb je validation layer (DDD)). TL;DR: De DDD term 'ubiquitous language' is van belang voor dit checkpoint. Zoals hierboven uitgelegd gaat het bij 'shared information model' vooral om het informatiemodel van het software‑ontwikkelproces. De term 'domein' kan verwarrend zijn; soms is ICT zelf het domein. Binnen dit ICT‑domein is 'semantic versioning' (semver) een belangrijk concept: het geeft betekenis aan versienummers. Je kunt semver toepassen op zowel je applicatie (features/bugfixes per versie) als op tools die je gebruikt. |
| IR-202 Traceerbaarheid ingebouwd in pipeline | Traceren of 'tracing' gaat over het achterhalen van fouten/bugs in software. In een DevOps omgeving denk je dan eerder aan fouten in productie (of staging), i.p.v. nog lokaal (development) waar je deze fouten kunt debuggen in je IDE. Het gaat hierbij ook vaker om integratie bugs. Denk aan automatische release notes/testplannen uit de pipeline en traceerbare koppelingen tussen requirements, builds, tests en releases. |
| IR-301 Graphing-as-a-service | Er is een aparte service die op aanvraag en redelijk gestandaardiseerd grafieken kan aanleveren. In plaats van dat elke applicatie dit intern zelf doet, en elk op eigen wijze. Real‑time dashboards met relevante grafieken per doelgroep. |
| IR-203 Rapportagehistorie is beschikbaar | Als monitoring/metrics eenmaal draaien, wordt historie automatisch opgeslagen zodat je trends kunt zien. Denk aan: aantal critical issues vorige maand vs. nu, request-aantallen per dag op een BFF, of CPU-load over de laatste 3 weken. Tools bewaren deze ruwe data in tijdreeks-/logbackends (bijv. Prometheus TSDB + retention, Loki/ELK met bewaartermijn), waardoor je trendgrafieken en vergelijkingen in de tijd kunt maken. Dit maakt retrospectives en continue verbetering gericht: je ziet het effect van wijzigingen in proces of code. |
| IR-303 Report trend analysis | Gelieerde aan IR-402, maar in plaats van Cross Silo kan in ieder geval binnen een Silo/service/organisatie onderdeel grafieken of gegevens worden opgevraagd, maar dan wel over een bepaalde tijd, om verloop te kunnen analyseren (trend). |
| IR-401 Dynamische grafieken en dashboards | Spreekt hopelijk voor zich? Realtime of i.i.g. 'near realtime' data uit productie op dashboard scherm ook bereikbaar voor business mensen. Bv. het aantal openstaande issues op schermen in team work garden, maar wellicht ook direct inzichtelijk maken als/dat server geheugen volloopt, of tonen van aantal mensen momenteel in check-out scherm van webwinkel (of vergelijkbare 'custom metric' in ander/eigen domein). |
| OA-401 Infrastructure as Code (IaC) | Deze term is te vergelijken met Configuration as Code (CaC OA-203), alleen in plaats van de software configuratie beschrijf je nu de hardware configuratie als code. Oftewel: op welke infrastructuur gaat je software precies draaien. Dus welke CPU, hoeveel geheugen, hoeveel harde schijfruimte, maar bv. ook of bandbreedte. Voor echt hardcore IAC hoort hier ook het type hardware nog bij, zoals heb je Intel processor nodig, of AMD of een Apple M1 o.id., is je harddisk een (snelle) SSD (solid state disk) of ouderwetse magenetische schijf. Typisch gezien doe je dit bij Cloud providers, die dit soort hardware ook kunnen leveren. De precieze opties die je hebt hangen dan ook af van de Cloud provider die je gebruikt. Verschillende cloud providers hebben ook verschillende naampjes voor de machines. Er zijn ook wel speciale IaC tools/talen om meer generiek een config in te schrijven, zoals Cloudformation voor AWS (Amazon Web Services) of Azure Resource Manager (ARM, niet te verwarren met de (RISC) processor met hetzelfde acronym). Deze geven dus een soort abstractielaag om niet alle details te hoeven kennen, en minder afhankelijk te zijn van wijzigingen in hardware die er zijn. En er is zelfs cloud agnostische Terraform (hoewel de machine namen in deze config taal vaak alsnog cloud specifiek zijn). Vergeet ook niet dat je voor IaC ook tools moet hebben die deze config moeten kunnen uitvoeren (anders is het slechts een 'spec', geen code). Dit punt zit dus erg aan de OPS kant, en kun je NIET zomaar afvinken, maar moet je je echt verdiepen in IAC. Als developer wil je je vaak je software juist enigszins onafhankelijk maken van onderliggende hardware details, maar uit handen laten nemen door in te stappen op een 'X As a Service model'. Als er speciale eisen zijn, zoals gebruik GPU's i.p.v. CPU's voor bv, grafische toepassingen, of machine learning kan dit echter niet altijd meer, of als je heel grootschalig gaat werken kun je je kosten besparen als je dit zelf doet. Een goede aanzet voor dit punt, om het 'half af te vinken' kan wel zijn dat je in Kubernetes horizontal podscaling instelt ën je containers draait met zogenaamde Quality of Service instellingen hebben, dus echt vermelden van hardware karakteristieken zoals minimale CPU snelheid en harddisk ruimte. |
CDMM Q&A
Q: Kunnen wij het punt CO-305 - Continuous improvement al behalen door retrospectives uit te voeren over ons individuele handelen en onze processen? A: Niet helemaal, je moet naast probleem analyse (retro), ook verbeterpunten concreet formuleren (denk Transfer uit STARRT methode) en ook doorvoeren in opvolgende sprints (of kunnen uitleggen waarom een voorgenomen improvement in de praktijk er toch niet van kwam) Q: Wat bedoelen jullie met het punt BD-207 - Standaard proces voor alle omgevingen? A: Dit gaat vooral over het deploy proces. Als antwoord een schets van een situatie waarin een team een verschillend proces per omgeving hanteert. Zonder standaardisatie verloopt het deploymentproces verschillend per omgeving:
- Op de developmentomgeving gebruiken teamleden handmatig commando’s om de app te deployen.
- Voor staging upload je bestanden via FTP.
- Production vereist speciale scripts die uniek zijn voor de live-omgeving.
Deze verschillen leiden tot fouten, zoals configuratiemissers, vergeten updates, of inconsistente versies tussen omgevingen.
Q: Voor BD-302 - Meerdere build machines: mag mijn teamgenoot die runnen op zijn VPS? A: Ja
Q: TV-302 - Performance test? Wat moeten wij performance testen? En hoe uitgebreid? A: Performance kritieke onderdelen. Early optimisation is the root of all evil. Zei eens iemand. Maar er kwam nog wat achteraan. En performance is ook een feature, die veel geld of andere waarde (minder verspilde tijd) kan opleveren in sommige domeinen. Dus zo uitgebreid als nodig is om probleem in kaart te krijgen, maar mits het past in jullie tijdsbesteding. Stem af met opdrachtgever. Je moet echter ook wat onderzoek doen in het project, je bent met een heel team. Dus je kunt best goede tools en/of aanpakken onderzoeken. Bv. een profiler in je IDE. Of een load test tool als K6 voor webapps.
Nog over faken data: fake it till you make it
In kader van het 'shift right' is het goed om al tijdens ontwikkelen vooruit te kijken naar relevante metrics die je kunt verzamelen en waarop de business kan handelen. Dit is wel eens beschreven als een soort 13e factor als uitbreiding op de 12factor app principles. Namelijk als 'Telemetry' (namelijk in het boek van Kevin Hoffman (2016))
I like to think of pushing applications to the cloud as launching a scientific instrument into space. [...] If your creation is thousands of miles away, and you can’t physically touch it or bang it with a hammer to coerce it into behaving, what kind of telemetry would you want?
Bronnen
- Hoffman, K. 1st edition, april 2016. Beyond the twelve factor app - Exploring the DNA of Highly Scalable, Resilient Cloud Applications. Oreilly, Pivotal. Geraadpleegd op 23-10-2023 op https://www.cdta.org/sites/default/files/awards/beyond_the_12-factor_app_pivotal.pdf
- Hofer S. & Schwentner H. domainstorytelling.com (2023) Domain Storytelling: Quick-Start Guide - Feeling lost? Workplace Solutions Geraadpleegd 23 oktober 2023 op https://domainstorytelling.org/quick-start-guide#feeling-lost
- Bird, J (2011) Rolling forward and other deployment myths. DZone. Geraadpleegd laatst op https://dzone.com/articles/rolling-forward-and-other
- Smith, Steve "ardalis" (9-11-2023). Deployment vs Release. X Geraadpleegd 13 nov 2023 op https://x.com/ardalis/status/1722728350437757320
- Brannon, J. Against democracy Boekbeschrijving geraadpleegd 23 oktober 2023 op https://www.bol.com/nl/nl/p/against-democracy/9200000075205551/
- Vorne Industries. (z.d.). Kaizen. Leanproduction.com. Geraadpleegd op 22-09-2025, van https://www.leanproduction.com/kaizen/
Weekopdrachten
Er zijn in totaal 5 wekelijkse opdrachten:
- GitOps - Werk in tweetallen
- Containerization - De Werkparen Wijzigen
- CD - Flexibele Paren
- RabbitMQ - Flexibele Paren
- Orchestration - Groep van 6 mensen
Werkwijze
Denk aan onderstaande punten bij het maken van de weekopdrachten:
- Vorm telkens duo's of grotere teams en wissel, afhankelijk van de weekopdracht
- Gezamenlijk backlog/issues, samen opstellen/verdelen
- Kleine frequente commits (en commit op de gemaakte issues)
- Lever in via assignen issue aan student die de peer review moet doen (+een git tag)
Hieronder verdere uitleg per punt.
1. Groepsvorming voor wekelijkse Opdrachten
Om het samenwerken te oefenen, heb je voor elke opdracht wisselende teamgrootte en -partners. Als developer heb je wellicht de neiging om alles in je eentje te doen, want dat scheelt een boel overhead. En een klasgenoot vragen/vinden kan best spannend zijn. DevOps gaat echter over samenwerken. Voor het managen hiervan heb je ook de tools maar geldt uiteindelijk:
'Individuals and interactions over processes and tools' - Agile manifesto
Week 1
- Vorming van Paren:
- Docent bepaalt de duo-indeling en wijst C# of Java toe.
- Taalvereiste:
- 50% van de paren werkt in Java.
- De andere 50% werkt in C#.
Week 2
- Decentrale Besluitvorming:
- Studenten mogen zelf nieuwe duo's vormen en taal kiezen.
- Als dit goed gaat, mogen ze dit CDMM-punt 'CO-206 Decentrale besluiting afvinken.
- Bij problemen (geen partner vinden, overblijvende studenten) bepaalt docent bij de volgende week opdracht de indeling weer.
 Figuur: Decentrale besluitvorming (afbeelding gegenereerd door ChatGPT)
Figuur: Decentrale besluitvorming (afbeelding gegenereerd door ChatGPT)
Decentrale besluitvorming komt neer op het principe dat er GEEN dictatuur is, of strikte hiërarchie, met 1 leider die alles beslist (=centrale besluitvorming), en ook GEEN democratie, waarin de meerderheid beslist (stemmen), maar dat voor een beslissing diegene deze beslissing neemt die hierover het meeste weet, of de beste argumenten heeft. Dit klinkt logisch, maar vereist veel onderling vertrouwen, kennis van elkaars vaardigheden en expertises (T-shaped professionals), en een veilige omgeving waarin iedereen zich kwetsbaar durft op te stellen en er geen 'blame' cultuur is.
Dit past bij het CDMM Advanced niveau waar teams de competentie en het vertrouwen hebben om verantwoordelijk te zijn voor wijzigingen tot in productie. Het gaat over het vinden van de meest expert in een bepaald onderwerp, wat ook hoort bij de 'T-shaped professional' (bron: InfoQ - Continuous Delivery Maturity Model).
Merk op dat voor eigen teamindeling over decentraal beslissen gaat op meta niveau of proces niveau, maar dat beslissingskennis ook vaak harde technische kennis is over ICT of het gebruik van DevOps tools, of — even harde — kennis over het domein; the 'inherent complexity' die vaak decentraal aanwezig is. Bijvoorbeeld: de Android developer die beslist over de juiste lifecycle methods voor een activity, de DevOps engineer die de optimale Kubernetes resource limits bepaalt, de database expert die kiest voor de juiste indexing strategy, of de security specialist die de authentication flow ontwerpt. Of domeinkennis: de monteur die weet dat een 'kleine beurt' bij PitStop eigenlijk altijd een oliefilter vervanging betekent, of de receptionist die begrijpt dat een 'APK keuring' niet hetzelfde is als een 'grote beurt' en dus andere tijdsinschattingen en prijzen heeft.
Zie ook DevOps concepten voor meer details over dit CDMM concept.
Week 3, 4
- Flexibele Paren:
- Paren kunnen opnieuw wisselen.
- Terugkeren naar het oorspronkelijke paar is toegestaan.
Week 6
- Groepen Vormen:
- Groepen van 6 mensen.
2. Gezamenlijke backlog
Binnen Agile en DevOps is een gezamenlijke backlog ook een best practice ("CO-101 Eén backlog per team"). Maak voor je opdracht in GitHub een planning bord aan met ook achterliggende issues aan in de repository en verdeel de taken onderling (assign) op een logische manier (iedereen moet in gelijke mate bijdragen).
Neem hiervoor samen kort opdracht door en kies korte maar logische issue titels. Gebruik issue nummer(s) ook in je commit messages, zodat je vanuit issues daarna ook door/terug kunt klikken naar gedane commits. Vergeet daarbij niet het gebruik van hekje #.
3. Aanhouden Git versiebeheer (best practice)
Tijdens deze course doen we versiebeheer met git. Je commit je uitwerkingen. Hanteer hierbij git (en devops) best practices, zoals:
- use small commits
- commit often
- write clear and short commit messages
- werk samen (beiden committen!)
- werk op zelfde branch of merge regelmatig
4. Peer review
Als je klaar bent:
Tag de versie met git als het af is met een 'major versie' 1.0.0 en push alles. Maak dan een issue aan in/bij je Git repo met titel Nakijken en assign deze aan de student die de peer review moet doen.
Het project moet uiterlijk donderdag af zijn, waarbij de docent in de les steekproef doet. Elke reviewer evalueert de codebase van een toegewezen peer met behulp van de CDMM Evaluatie Peer Feedback Template (aleen de relevante punten uit DevOps maturity model) en beoordeelt of het project voldoet aan een minimum niveau 6 per categorie, met een onderbouwing.
Je hebt dan vrijdag nog om met de feedback aan de gang te gaan. Maar daar is vaak ook al huiswerk voor de les van de maandag. De ingevulde feedback moet uiterlijk maandag als een pull request worden ingediend in de repository van de peer, waarbij de template wordt toegevoegd aan de onderkant van het README-bestand. De eigenaar van de code is verantwoordelijk voor het bekijken en accepteren van de pull request, wat dient als erkenning van de ontvangen feedback.
# Peer Feedback Template: CDMM Evaluatie
**Naam beoordelaar:**
**Naam student (peer):**
**Gecodebaseerd project:**
**Datum van beoordeling:**
---
## 🧑🤝🧑 Cultuur & Organisatie
- **Klopt gegeven self assessment cijfer?**: [ ] Ja | [ ] Nee, wij vinden 0|2|4|6..
- **Is het al voldoende (6)?**: [ ] Ja | [ ] Nee
- **Toelichting**:
*(Leg uit of de peer minimaal niveau `6` in deze categorie heeft bereikt en verwijs naar specifieke aspecten in de codebase of het project die dit ondersteunen of juist niet.)*
- **Ik kan de volgende punten niet beoordelen omdat...**
*(Noem de punten die je niet kunt beoordelen en leg uit waarom, bijvoorbeeld vanwege ontbrekende documentatie, onvoldoende toegang tot relevante informatie, of onduidelijke implementatie.)*
---
## ⛪ Ontwerp & Architectuur
- **Klopt gegeven self assessment cijfer?**: [ ] Ja | [ ] Nee, wij vinden 0|2|4|6..
- **Is het al voldoende (6)?**: [ ] Ja | [ ] Nee
- **Toelichting**:
*(Geef een onderbouwing op basis van de ontwerp- en architectuurelementen die je hebt waargenomen in het project.)*
- **Ik kan de volgende punten niet beoordelen omdat...**
*(Noem de punten die je niet kunt beoordelen en leg uit waarom.)*
---
## 🏗️ Build & Deploy
- **Klopt gegeven self assessment cijfer?**: [ ] Ja | [ ] Nee, wij vinden 0|2|4|6..
- **Is het al voldoende (6)?**: [ ] Ja | [ ] Nee
- **Toelichting**:
*(Bespreek de build- en deploymentpraktijken en of deze voldoen aan minimaal niveau `6`.)*
- **Ik kan de volgende punten niet beoordelen omdat...**
*(Noem de punten die je niet kunt beoordelen en leg uit waarom.)*
---
## 🧪 Test & Verificatie
- **Klopt gegeven self assessment cijfer?**: [ ] Ja | [ ] Nee, wij vinden 0|2|4|6..
- **Is het al voldoende (6)?**: [ ] Ja | [ ] Nee
- **Toelichting**:
*(Beoordeel de test- en verificatieprocessen en onderbouw je conclusie.)*
- **Ik kan de volgende punten niet beoordelen omdat...**
*(Noem de punten die je niet kunt beoordelen en leg uit waarom.)*
---
## 📈 Informatie & Rapporteren
- **Klopt gegeven self assessment cijfer?**: [ ] Ja | [ ] Nee, wij vinden 0|2|4|6..
- **Is het al voldoende (6)?**: [ ] Ja | [ ] Nee
- **Toelichting**:
*(Evalueer de informatie- en rapportagemechanismen en leg uit waarom je tot deze beslissing bent gekomen.)*
- **Ik kan de volgende punten niet beoordelen omdat...**
*(Noem de punten die je niet kunt beoordelen en leg uit waarom.)*
5. Inleveren
NB Aan het eind van van de course upload je een .zip met al je opdrachten naar iSAS voor het archief (namelijk voor evt. accreditatie checks bij AIM). Dit inleveren is een eis om totaalbeoordeling/-cijfer te krijgen (want na cijfer toekenning door docent gaat je inlevermogelijkheid automatisch dicht).
Wat moet ik waar uploaden in iSAS?
Hier het totaal overzicht van wat waar in te leveren in iSAS:
- TOETS-02 - Beroepsproduct DevOps <-- PitStop uitbreiding BP groepsrepo
- TOETS-03 - Wekelijkse Huiswerkopdrachten <-- Verzamelzip weekopdracht 1, 2, 3, 4 en 5
Week 1 - GitOps
GitOps Definitie
GitOps is reconciling a desired state in Git with a runtime environment
Everett Toews 10-2-2020, deloitte.com
Week 1 Opdracht
Je krijgt de 1e opdracht via GitHub Classrooms. Je kiest/vindt hierbij zelf een partner en bouwt samen een klein software project. Het is meer "Hello world" dan echte functionaliteit, omdat de focus NIET op code ligt, maar op DevOps technieken.
Het project bevat unit tests, en de tutorial laat dit je test first opzetten (TDD). Dit is de moderne standaard. Hierbij heeft je programma eigenlijk nog geen echt entrypoint. Want de tutorial geeft aan een classlib aan te maken in .NET. Laat dit voor nu zo, dit ga je volgende week refactoren/uitbreiden naar wel een entry point (main) en ook een .NET web api project, zoals de docent als het goed bespreekt (anders naar vragen!). En nog later kun je de webapplicatie continuous deployment of delivery toepassen.
Neem het project aan het begin samen door, verdeel taken en schrijf op het eind een self assessment op basis van CDMM en een reflectie zoals de werkwijze bij weekopdrachten vraagt.
Het is aan te raden enkele eigen unit tests toe te voegen, en evt. te experimenteren met 'parameterized tests'. In ieder geval geen code vol met unit testing anti patterns (zie video David Farley) i.v.m. met .
Plenair einde les
Lees het overzichtsartikel over gitops op gitops.tech. Schrijf interessant/onbekende termen op. Bekijk hierna ook naar lessen overzicht van deze minor.
- Wat betekent de term reconcilliation?
- Geef drie voorbeelden van toepassen van reconcilliation in een software project denk aan
- a) een feature release
- b) dependency management/update en
- c) infrastructure as code
- Wat is het verschil tussen declaratief en imperatief?
- (kun je koppelen aan term 'reconcilliation')
- Wat is het idee van pull-based vs push-based GitOps?
- Is 1 van de 2 beter?
- (Welke gebruikt InfoSupport?)
- Welke onderdelen moeten we in de komende weken nog bekijken?
- Welke onderdelen gaan we NIET behandelen (maar zijn wel kandidaat voor eigen onderzoek voor week 5)
- Wat is een run time environment? Geef 3 voorbeelden
- Hoe verloopt een applicatie wijziging binnen GitOps en wat is het verschil met andere (oudere) aanpakken?
Leerdoelen
- Je kent Git, kunt het gebruiken op command line en GUI en weet wat je hierin opslaat en wat niet
- Je kent de rol van branches in Git en erbuiten en enkele alternatieven voor feature branching die beter matchen met Continuous Integration
- Je kent twee Git workflows om in een team software producten te bouwen
- Je kunt een Git hook maken, en kent de mogelijkheden en beperkingen ervan
- Je kunt commits doen in (Git) versiebeheer en kent de git basics zoals 4 area's, branches, .gitignore en omgang met Git's 'gedistribueerde karakter'
- Je kunt markdown gebruiken en een UML diagram in tekst opstellen
- Je kunt de definitie van GitOps en kunt de term uitleggen en hebt een onderbouwd oordeel of het een buzzword is of meer dan dat
- Je kunt de termen reconcilliation en runtime environment uit de GitOps definitie uitleggen en van elk 3 voorbeelden geven
- Je kent het verschil tussen code en software en de relatie met 'source control'
- Je kent verschil tussen git en git platforms als GitHub of GitLab en kunt ermee werken
Lesoverzicht
- Les 1 - Linux 1/2
- Les 2 - Introductie Docker/Introductie GitOps
- Les 3 - Getting Git
- Les 4 - Git Workflows + Weekopdracht bespreken & peer feedback (CDMM, aanwezigheid, reflectie)
Oefentoets
Test je kennis met deze korte multiple choice oefentoets voor week 1.
Les 3 - Linux 1/2
Geen voorbereiding
Gastdocent: Rene Grijsbach
Lesintroductie
Om de presentatie te volgen, kun je de .pdf van de slides downloaden via de volgende link: NDG Linux Unhatched.pdf.
Lesnotities

Voor deze Linux les ga je aan de slag met de Cisco 'Linux unhatched' course. Deze is online beschikbaar op netacad.com, maar in 2024/2025 minor zal workshop docent een eigen variant 'on premise - private cloud' draaien.
The DevOps way is ook 'embracing the command line', zoals je bv. op de DevOps roadmap op roadmap.sh kunt zien (zie figuur 1). We volgen deze roadmap zeker NIET geheel in deze minor, maar wel paar hoofdpunten.

Deze roadmap geeft aan dat je als je een programmeertaal kent — zoals voor alle developers geldt — dat dan Operating System (OS) kennis en specifiek Linux kennis de volgende stap is. Dus ook kennis van het gebruik van de command line ('learn to live in the terminal') en bash scripting (wk 2). En daarna door met Git en versiebeheer (onderdeel van GitOps). Opvallend is dat 'creator of Linux' Linus Torvalds (Wikimedia, 2023) ook de auteur was van Git. Dus zijn naam moet je als DevOps professional zeker kennen!
{kind=link}
In deze les is er ook al introductie van de Linux opdracht die je in week 2 af moet hebben. Tevens demonstreert de docent hoe je een VPS kunt gebruiken/krijgen in de private cloud. Alsmede de VPN client ['Tunnelblick](https://tunnelblick.net/) die je moet installeren op je laptop/pc om vandaar bij deze omgeving te komen (i.v.m. security). Deze VPS gebruik je ook de weekopdracht 3 van de DevOps course.
Op deze omgeving is wel beperkte support, dus als hiermee problemen zijn, vallen we terug op VPS'en aan te vragen bij HAN/AIM ICT (martin.jacobs@han.nl) (documenteer en meldt wel de error).
Iets over de Linux kernel, verschillende distributies en de link met Docker
Figuur 1: DevOps roadmap (roadmap.sh, 2023; rode pijlen zelf toegevoegd)
Belangrijke achtergrondinformatie voor een Linux les is ook wel te weten dat 'Linux' eigenlijk niet bestaat. Bij Linux denken we vooral aan de Linux shell die je als eindgebruiker gebruikt, de command line. Maar feitelijk is de shell de 'user interface' van de Linux software zelf: het operating system. Dat 'operating system' is feitelijk een abstractie van de hardware die in je computer zit, e.g. CPU, geheugen, harddisk en netwerk. Deze vormen samen de 'infrastructuur' van je laptop/desktop computer (Linux draait ook op nog andere devices, ook PDA's, TomTom's en ook Android wat op veel mobiele telefoons draait is Linux-based).

Figuur 2: Enkele Linux distributies
Figuur 2 toont een boom met hierin enkele Linux distributies. Of eigenlijk is het een omgekeerde boom ;) (tree, een relevante/veelgebruikte datastructuur in de ICT). De basis van de boom is de Linux Kernel. Dit is de gedeelde functionaliteit die alle Linux distributies delen. Maar iemand die 'Linux draait' gebruikt altijd een specifieke distributie. Dit diagram gemaakt met behulp van ChatGPT, en geeft naast naam van een distributie . Dus garantie tot de deur, maar hier is de originele 'prompt' en bron.
De '2005' Alpine is in ieder geval wel gecheckt. Dit is opvallend genoeg een aantal jaar voor het ontstaan van Docker (geboorte bij dotCloud 2010, Docker launch in 2013). Deze Alpine distributie is vooral bekend uit de Docker wereld, maar 'predate' deze dus blijkbaar wel:
“The idea was that the system was installed in memory during boot from a read-only media and that you could remove the boot media once it was booted,” explained Natanael Copa, the creator of Alpine Linux, in an interview." - TheNewstack.io
Opdracht
- Maak een Cisco account, neem de stof door en oefen. Maak tot slot de oefenvragen. Bekijk de onderwerpen waar je evt. fouten had nog een keer beter. Maak vragen totdat je denkt dat je stof beheerst. Schrijf probleempunten op voor navragen bij de docent.
Opmerkingen
Gebruik hier de online command line die Cisco je biedt. Voor een wat 'echtere' ervaring en als je op Windows werkt is het ook handig om lokaal Linux te kunnen draaien (we gaan even uit van veelgebruikte Linux distributie Ubuntu (zelf weer afgeleid van Debian)).
Twee opties:
- Installeer Docker Desktop
- Start daarmee (bv. Ubuntu) Linux via
docker run -it ubuntu:latest(je kunt deze — na experimenteren — afsluiten met commandoexit)
- Start daarmee (bv. Ubuntu) Linux via
- Door het gebruik en installatie/activeren van WSL 2.
- Dit is een heel stappenplan, maar huidige Docker Desktop versies werken hier ook goed mee samen, dus wel aan te raden
Opmerking: In DevOps lessen van week 2 ga je verder werken met Docker.
Quiz
Test je kennis over Linux met deze multiple choice quiz.
Hieronder een deel van de README.md van de tool featmap op GitHub, die terug komt in één van de vragen.
Building from source and running with docker-compose
Clone the repository
git clone https://github.com/amborle/featmap.git
Navigate to the repository.
cd featmap
Let's copy the configuration files
cp config/.env .
cp config/conf.json .
Now let's build it.
docker-compose build
Startup the services, the app should now be available on the port you defined in you configuration files (default 5000).
docker-compose up -d
Leerdoelen
- Je kent de basis Linux command line commandos uit de Cisco unhatched cursus/vragenset
- Je weet wat de Linux kernel en Linux 'distro's' zijn en kunt er enkele noemen
- Je kent de naam van de originele ontwikkelaar van Linux en weet wat voor een 'git' hij is ;)
Les 2 - Docker 101
Gastdocent: Jaap Papavoine
Een nieuwe technologie toe-eigenen hoort bij je werk. Je hebt ondertussen in de opleiding veel technologieën leren kennen, meestal met begeleiding van lesmateriaal en een docent. Tijdens je afstuderen en in je werk hierna zal je ongetwijfeld veel nieuwe technologieën gaan gebruiken die we je niet geleerd hebben, en op dat moment is er geen materiaal of docent beschikbaar. Om hier alvast mee te oefenen maken we in de lessen over Docker zo veel mogelijk gebruik van online bronnen.
Voorbereiding
Reminder: De voorbereiding is niet optioneel. Zonder voorbereiding wordt het lastig om mee te doen met de les en dat is een verspilling van zowel je eigen tijd, tijd van je mede studenten en tijd van de docent. Niet aardig.
Installeer Docker Desktop - Zorg dat je het commando 'docker container run hello-world' kunt uitvoeren.
In het Docker desktop learning center (in de UI van Docker Desktop) zitten een aantal walkthroughs. Doorloop de volgende walkthroughs:
- What is a container?
- How do I run a container?
De rest mag je gerust ook maken als je geïnspireerd bent!
Lees alvast 'Part 1: Overview' van de Get started guide op https://docs.docker.com/get-started/. We gaan in de les verder met deze getting started guide, en je kunt al zover door werken als je kunt.
Lees het eerste hoofdstuk (van 'Minor Devops: Lets do...' tot 'Fasering, project etc..') van het DevOps course materiaal (nog eens?) door, maar ga specifiek op zoek naar raakvlakken met containers. Welke requirements / uitdagingen / concepten / technieken genoemd in de DevOps minor hebben iets te maken met software containers? Maak een lijstje van alle raakvlakken die je hebt gevonden en neem dit lijstje mee naar de les.
Tijdens het maken van de voorbereiding kom je waarschijnlijk dingen tegen die je niet precies begrijpt. Logisch, je bent tenslotte een nieuwe technologie aan het leren. Schrijf de vragen die je hebt en de concepten die je niet kent op!
Loop je vast tijdens het voorbereiden, schrijf dan de volgende dingen op:
- Bij welke stap loop je vast?
- Wat heb je geprobeerd?
- Hebben je collega's hetzelfde probleem?
- Waar denk je zelf dat het misgaat?
- Heeft stackoverflow een oplossing voor je probleem?
Misschien is er tijd om voor de les je probleem te bekijken met de docent en/of medestudenten.
Lesprogramma / Lesmateriaal
Bestudeer de theorie die zowel in de lesdia's als in de Docker Workshop wordt gepresenteerd. Lees voor de Docker Workshop de README-bestanden zorgvuldig door, voltooi de oefeningen en experimenteer verder op eigen houtje.
- Lesdia's: Docker_In_A_Nutshell.pdf
- Docker Workshop
DevOps Concepten
Voor uitgebreide uitleg over Docker concepten, zie de Docker Workshop.

Figuur 1: DevOps credo - "Treat servers like cattle, not like pets"
Quiz
Test je kennis met deze korte multiple choice quiz.
Les 2 - Getting Git

Bron: https://xkcd.com/1597/
Voorbereiding
Reminder: De voorbereiding is niet optioneel. Zonder voorbereiding wordt het lastig om mee te doen met de les en dat is een verspilling van zowel je eigen tijd, tijd van je mede studenten en tijd van de docent. Niet aardig.
- Lees de opdrachtbeschrijving van deze week.
- Accepteer 1e weekopdracht via de GitHub Classroom link die docent je geeft.
- Zorg dat je de laatste (LTS) versie van Git lokaal geinstalleerd hebt.
- Review Git
- Uitgangspunt is al enige ervaring met Git uit eerdere projecten, zowel theorie als prakijk. Als Git nieuw is, of heel lang geleden kun je deze korte 15 minuten git intro op YouTube van een zekere Colt Steele kijken.
- Maak de online oefeningen van module 1 (introduction sequence) van Learn git branching
- Lees dit artikel van Priyam Singh (2020) over de 'four area's'

- Haal uit de officiele 'git reset' documentatie het verschil tussen hard, soft en mixed git reset.
- Beantwoord de volgende vragen (hier komen wij in de les op terug)
- Schrijf uit je hoofd op wat de 'four area's' van Git zijn.
- Hoe past de
remoterepository bij deze four area's? - Hoe commit je het verwijderen van een file?
- Hoe commit je het veranderen van een bestandsnaam?
- Kun je een Git commit message later nog aanpassen via de command line? (Zo ja, hoe? Als niet, waarom niet?)
- Wanneer heb je langere 'commit trail'? Bij gebruik van
mergeof vanrebase? - Wat is de standaard 'mode' van git reset (mixed)?
- Wat zou een toepassing kunnen zijn van
git reset soft?

Bron: www.theserverside.com
Lesprogramma

Figuur 1: GitOps in a nutshell (Bron: vocal.media)
- GitOps Betekenis
- Reconciliation
- Wekelijkse Opdracht
- Discussie over het vormen van groepen
- Introductie tot cursus rubric CDMM — Nodig voor Wekelijkse Opdracht reflectie
- Introductie deze week Opdracht
PAUZE — 15 min.
- Doornemen huiswerk vragen
- Maak de online oefeningen van module 2 en 3 van Learn git branching (4 en 5 optioneel)
- Ramping up
- Moving work around

- Bespreken "advanced" termen
- De staging area (en hoe
git resetnou precies werkt) - Het netjes maken van commit messages en hergroeperen van commits
- De stash
- Cherry picking
- remotes
- Changes rebasen i.p.v. mergen
- De staging area (en hoe

Vooruitblik
Volgende DevOps les over Git workflows, alternatieven voor git branches en GitOps. Bekijk het huiswerk ook!

Leerdoelen
- Je kunt uitleggen wat GitOps is, de rol die Git hierin speelt en de betekenis van woorden 'runtime', 'reconcilliation' en 'desired state' hierbij
- Je kent de basis Git commando's, als
add,commit,push,pull,stashen concepten als Git's four area's - Je kent ook enkele geavanceerdere Git commando's en werkwijzen zoals
git reset,git cherry-pick, rebasing en het manipuleren van de historie metamendenrevert - Je kunt uitleggen hoe Git branching 'goedkoop' heeft gemaakt
Quiz
Test je kennis over T-shaped professionals met deze multiple choice quiz:
Bronnen
- Singh, P. (January 17, 2020) Git - The Four Areas devsecopsgirl.in Geraadpleegd november 2024 op https://www.devsecopsgirl.in/devsecops/Git%20-%20four%20areas
- Git (z.d.) git-reset Documentation. git-scm.com. Geraadpleegd december 2024 op https://git-scm.com/docs/git-reset
- McKenzie, C. (23-8-2024) Git reset hard vs. soft: What's the difference? theserverside.com Geraadpleegd december 2024 op https://www.theserverside.com/blog/Coffee-Talk-Java-News-Stories-and-Opinions/Git-reset-hard-vs-soft-Whats-the-difference
Les 3 - Git workflows
Voorbereiding
Reminder: De voorbereiding is niet optioneel. Zonder voorbereiding wordt het lastig om mee te doen met de les en dat is een verspilling van zowel je eigen tijd, tijd van je mede studenten en tijd van de docent. Niet aardig.
Neem de 2 artikelen en diagrammen door:
- Over GitHub flow
- Over git flow.
- Vragen over verschillen en eigen keuze:
- 3.1: Beschrijf eerst beide methoden in eigen woorden. Geef daarna een lijstje met verschillen tussen beiden.
- 3.2: Welk van deze methode ken jij al (een beetje)?
- 3.3: Voor welk van de twee zou je kiezen?
- 3.4: Welke van de twee methoden 1. Git flow of 2. GitHub flow zou jij kiezen in project A respectevelijk B:
- Project A: Een command line tool die door medewerker van een 'WebShop' gebruikt wordt om een JSON bestellijst van die dag om te zetten naar 2 aparte lijsten voor order picken door medewerkers in hun 2 magazijnen 'Vloerbedekking en Laminaat' en 'Gordijnen en vitrages'
- Project B: Een online video website met Agile ontwikkelmethode, waarin product owner onderkent dat deze de wensen van eindgebruikers niet geheel kent, en jullie experimenteren om nieuwe functionaliteit door eindgebruikers thuis te laten Beta testen?
Lesprogramma
- Doornemen lesvragen.
- Vraag: Waar heb jij 'branch by abstraction toegepast' in weekopdracht 1? (komen we verderop op terug)
- Samen doornemen van highlights uit video van David Farley over Continuous Integration vs Feature Branch Workflow dik kwartier (als genoeg tijd dan integraal samen kijken)
- Schrijf tijdens het kijken highlights op en minstens 2 vragen.
- Opdelen in duo's. Beantwoord elkaars vragen. Bespreek erna plenair (met docent) zaken waar je ook samen niet uitkwam.
- Kijken 'werkwijze bij weekopdrachten'
- Doornemen gemaakte weekopdrachten via enkele steekproefen, onderlinge feedback
- Bespreken vragen/knelpunten/onduidelijkheden
- Doornemen reflecties/self assessments
- Bespreken CO-303 uit het CDMM - Deploy losgekoppeld van release
- Kijken naar "OA-202 - Branch by abstraction" en andere alternatieven voor Git branches (zie kopje hieronder)
- Toepassen Branch by abstraction op code om PrimeService/Priemtester werkend te krijgen voor alle getallen
- Als eerder klaar en opdracht 1 al veel af, doornemen en uitdelen opdracht week 2
- Vooruitblik volgende week en huiswerk les 2-1
Alternatieven voor Git branches
Introductie term Branch by abstraction en andere alternatieven voor feature branching die beter bij Continuous Integration passen zoals feature toggles, of een dark release. Git heeft branching 'goedkoop' gemaakt t.o.v. andere versiebeheersystemen, maar branchen moet je zo kortdurend en minimaal mogelijk doen binnen DevOps. Geen 'long lived branches'.
Figuur 1: De branch uit branch by abstraction is GEEN 'Git branch', maar een conceptuele branch (bron: Fowler, 2014)
Er is ook zoiets als een 'Dark release' zoals Dave Farley het noemt (op 11:50 min in het filmpje). Martin Fowler defininieert deze term overigens net anders definieren en noemt wat Farley een 'Dark Launch' zelf meer een Keystone Interface (2020). Hij en anderen gebruiken 'Dark Release' als een synoniem voor een 'Canary Release' :S (split.io, z.d.). Een Canary release is een release die wel voo gebruikers beschikbaar is, maar voor slechts een deel daarvan, bijvoorbeeld Beta testers. Daar kijken we in week 4 verder naar, want bv. de Ingress uit KuberneteS maakt Canary releases makkelijker. Maar in dit vak hanteren we de terminologie van

Figuur 2: Keystone interface dankt zijn naam aan het concept 'keystone' een sluitsteen die een boog afmaakt.
Feature toggles – eenvoudig Java voorbeeld (properties)
Eigenschap in application.properties:
feature.checkout.newFlow=true
feature.recommendations.mode=AB_TEST # voorbeeld: niet alleen boolean, maar enum-achtige waarde
Lezen in Java (Spring):
@Component
public class FeatureFlags {
@Value("${feature.checkout.newFlow:false}")
private boolean newCheckoutFlow;
@Value("${feature.recommendations.mode:NORMAL}")
private String recommendationsMode;
public boolean isNewCheckoutFlow() { return newCheckoutFlow; }
public String getRecommendationsMode() { return recommendationsMode; }
}
Gebruik:
if (featureFlags.isNewCheckoutFlow()) {
// activeer nieuwe pad
} else {
// bestaand pad
}
Dark launch / dark release / branch by abstraction / feature toggles
- Dark launch/dark release: functionaliteit is gedeployed maar (nog) niet zichtbaar voor gebruikers; achter een toggle of verborgen pad. Goed voor veilig testen in productie.
- Branch by abstraction: introduceer een abstractie (interface/facade). Implementeer nieuw gedrag erachter en switch; daarna oude implementatie opruimen. Vermijdt lange Git feature branches.
- Feature toggles: schakel paden aan/uit of kies varianten (boolean, enum, percentage). Goed voor gecontroleerde activatie en experimenten.
Voordelen:
- Kortere integratiecycli (sluit aan bij CI/CD), gecontroleerde activaties, experimenteren A/B.
Nadelen/valkuilen:
- Combinatorische explosie bij veel toggles (testmatrix explodeert), toggletech‐debt (vergeten op te ruimen), vraag “welke configuratie test je?”. Beperk aantal tegelijk actieve toggles, documenteer eigenaarschap en opruimdatum.
Leerdoelen
- Je weet dat veelvuldig en - vooral - langdurig gebruik van meerdere Git branches NIET past bij een aanpak volgens Continuous Integration en waarom
- Je kunt drie alternatieven voor Git branches noemen en elke hiervan uitleggen
- Je weet waarom je (Git) branching toepast en op welke manier dit wel acceptabel is
- Je weet manieren 'to decouple release from deploy' (conform CDMM 'gevorderd' niveau)
- Je weet wat 'trunk based development' is (Gemmail, 2018)
Quiz
Test je kennis over met deze multiple choice quiz:
Bronnen
Dit zijn in deze les aangehaalde gebruikte bronnen.
- GitHub flow* Geraadpleegd september 2024 op https://guides.github.com/introduction/flow/
- Farley, D. ()
- Hendriks, V. (5-1-2010) update on 5-3-2020 A successful Git branching model. Geraadpleegd september 2024 op https://nvie.com/posts/a-successful-git-branching-model/
- Fowler, M. (7-1-2014). Branch by abstraction. Geraadpleegd 7 december 2023 op https://martinfowler.com/bliki/BranchByAbstraction.html
- Fowler, M. (29 April 2020). Keystone Interface. Geraadpleegd 7 december 2023 op https://martinfowler.com/bliki/KeystoneInterface.html
- Gemmail, R. (Apr 22, 2018) Trunk Based Development as a Cornerstone for Continuous Delivery Geraadpleegd op 5 september 2024 op https://www.infoq.com/news/2018/04/trunk-based-development/
- split.io (z.d.) Dark Launch Geraadpleegd op 5 september 2024 op https://www.split.io/glossary/dark-launch/
Week 2 - Containerization
Lesoverzicht
- Linux Bash (VPN/VPS)
- InfoSupport 1/4
- Docker 102
- InfoSupport 2/4
- ADR en ORM + Linux bash opdracht bespreken
Containerization Definition
Containerization is packaging software with the OS and other dependencies required to run the code to create a container that runs consistently on any infrastructure. IBM
Docker kwam in 2013 en maakte enkele krachtige maar obscure features uit Linux simpeler om te gebruiken. Met hun containers geven ze operations mensen de 'best of both worlds' van
- a) virtuele machines (isolatie en beheer via software) en
- b) de performance van OS processen direct op hardware ('metal).
Ze geven developers de mogelijkheid hun applicatie te containerizen met het OS en ook de hele tussenliggende stack van software (middleware zoals applicatie servers, webservers, message busen, en database servers en data caches e.d.). Zo werd het verschil tussen development omgeving en productie kleiner zodat je het 'works on my machine' probleem kan aanpakken.

Figuur 1: Docker - Oplossing voor het 'works on my machine' probleem?
Week 2 Opdrachten
Opdracht 1: Linux Bash Script
In Les 3 maak je een Linux bash script volgens de user stories in de opdracht repo. Zet het script in een eigen private repo op GitHub en maak een issue aan voor de docent om na te kijken.
Opdracht 2: Docker Containerization
De Docker opdracht staat op (private) GitHub AIM organization. Je doet een laatste Git opdracht/puzzel en containerized daarna je vorige week gemaakte applicatie in een Docker container. Deze test je lokaal en zet dan zelf docker op externe VPS en runt hierop de container. Werk weer samen in een (nieuw) duo via git en GitHub en let naast opdracht ook weer op algemene werkwijze zoals taakverdeling vooraf en eindigen met (gezamenlijke) self assessment in je README met betrekken relevante CDMM checkpunten en een reflectie zoals de [werkwijze bij weekopdrachten]vraagt.
In deze opdracht komt ook refactoring terug, en heb je nog een kans 'branch by abstraction' toe te passen/te identificeren. Het voorbeeld met vertaling van pipeline diagram van vorige opdracht is voor sommige zo klein/triviaal dat ze het daar nog missen.
Wellicht helpt (code) op onderstaande foto nog bij 1e stappen opdracht:

Toelichting: Wellicht heb je een docent wel eens horen zeggen dat als je kunt programmeren het daarna niet uitmaakt of je nou een webapplicatie, of desktop applicatie of console applicatie of mobiele app of webservice maakt. Dat is wat kort door de bocht; maar zit wel kern van waarheid in. In .NET kun je al zulke applicaties maken, en je gaat de simpele code uit je classlib nu beschikbaar stellen voor zowel web project als een console project.
Hiervoor moet je naast op code niveau met import ... statements (dit is using in .NET) nu ook op project niveau instellen voor de projecten in je solution. .NET heeft module systeem (net als Java vanaf v 9). Dus kijk even terug naar dotnet cli commando's die je bij de 1e opdracht wellicht domweg hebt nagespeeld.
Leerdoelen deze week
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- Je kent de 'Docker architectuur' (met concepten als images, containers, de docker engine en buildkit)
- Je kunt lokaal een container runnen
- Je kunt een eigen container maken
- Je kent de term ephemeral en het nut, en de 'oplossing' voor data persistentie in containers
- Je snapt het nut van een ORM en welke drie zaken je moet veranderen bij gewenste wijziging data schema
- Je snapt hoe Docker containers en images 'immutable' zijn en kunt termen als 'union file system' en 'copy on write' uitleggen
- Je begrijpt het begrip multi-stage container
- Je kunt een container optimaliseren en kent het concept van container layers
- Je kunt een container registry gebruiken en snapt het begrip
- Je kunt docker compose gebruiken en kent de relatie tussen Docker en docker compose
- Je kunt Docker installeren op een Linux VPS en deze gebruiken via een Docker context
Oefentoets
Test je kennis met deze korte multiple choice oefentoets voor week 2.
Les 1 - Linux 2/2: Bash script
Gastdocent: Rene Grijsbach
Lesintroductie
Voor deze nieuwe les kun je de .pdf van de presentatie en uitwerkingen van de lesopdrachten hier: Presentatie SSH & BASH (inclusief voorbeeld uitwerkingen)
Lesnotities

Zorg dat je de Cisco 'Linux Unhatched' course van vorige week af hebt en alle testvragen voldoende kunt beantwoorden.
Week Opdracht
- Schrijf een Linux bash script volgens de user stories (=spec) in deze opdracht repo op github
- Zet het bash script in een eigen prive repo op GitHub
- Maak een issue aan in GitHub voor de docent om hem na te kijken en assign dit issue aan de docent
- Je mag je eigen bronnen gebruiken om te leren scripten. Er zijn bijvoorbeeld de 3 volgende opties:
- een PluralSight course over Bash scripting binnen PluralSight's free library
- een module over bash scripting binnen de gratis Cisco course 'NDG Linux Essentials'
- of een YouTube video hierover

Figuur 1: Only legends will get this? :P Bron: TwisterByte23@Reddit, 2023

"I'm not sure what the matt-daemon project does yet, but I'm pretty excited about the name." - Justin Searls (2012)
Leerdoelen
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- Je kunt een Bash-script schrijven dat commando's uitvoert binnen een Linux-shell, inclusief variabelen, argumenten en output.
- Je kunt uitleggen wat de shebang-regel betekent en waarom die bovenaan een script staat.
- Je kunt aangeven hoe je een Bash-script uitvoerbaar maakt en het daarna uitvoert via de CLI.
- Je herkent en kunt toepassen hoe positionele parameters zoals $1, $2 en $0 werken in een Bash-script.
- Je kunt eenvoudige controlelogica implementeren zoals if-statements die controleren op het bestaan van bestanden.
- Je kunt Bash-loops zoals for-loops gebruiken om herhaalde acties uit te voeren
Quiz
Test je kennis met deze korte multiple choice quiz.
Les 4 - Microservices & DDD

InfoSupport: Microservices & DDD - Strategic Patterns
Er is geen verplichte voorbereiding voor de workshop in les 1.
Lesprogramma / Lesmateriaal
- Lesmateriaal wordt via Teams gedeeld - nieuwe versies van presentaties en oefeningen
- Microservices theorie en oefeningen
- Domain Driven Design inleiding en strategic patterns
Leerdoelen
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- Je kent de betekenis van de volgende termen in relatie tot Microservices: Cohesion/Coupling, Polyglot Microservices, Scalability
- Je kent de betekenis van de volgende Microservices-principes:
- Culture of automation
- Modelled around business domain (DDD)
- Highly observable
- Isolate failure (Design for Failure)
- Decentralize all things (freedom for the devops Teams)
Quiz
Test je kennis met deze korte multiple choice quiz.
Les 2 - Docker 102
Gastdocent: Jaap Papavoine
Deze les bouwt voort op de basis Docker kennis uit Docker 101. We gaan dieper in op Docker Volumes, networking en meer geavanceerde concepten.
Voorbereiding
Zorg dat je de stof uit Docker 101 goed beheerst voordat je aan deze les begint. Herhaal indien nodig de basis concepten uit de vorige les.
Lesprogramma / Lesmateriaal
De docent gaat verder in het materiaal met focus op:
- Docker Volumes: Persistent data management
- Docker Networking: Container communicatie
- Docker Compose: Multi-container applicaties
- Best practices: Security en optimalisatie
Bestudeer de theorie die zowel in de lesdia's als in de Docker Workshop wordt gepresenteerd:
- Lesdia's: Docker_In_A_Nutshell.pdf
- Docker Workshop
Focus van deze les
Deze les gaat verder waar Docker 101 stopt. De docent behandelt de meer geavanceerde onderwerpen zoals Volumes, networking en best practices. Zorg dat je goed voorbereid bent door de basis concepten uit de eerste les te beheersen.
Quiz
Test je kennis met deze korte multiple choice quiz.
Les 5 - Microservices & DDD
InfoSupport: Microservices & DDD - Strategic Patterns (vervolg)
Deze les bouwt voort op de vorige sessie. Zorg dat je de basis concepten uit de vorige sessie beheerst.
Lesprogramma / Lesmateriaal
- Lesmateriaal wordt via Teams gedeeld - nieuwe versies van oefeningen
- Oefening Domain Driven Design
Leerdoelen
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- Je kent de betekenis van de volgende termen in relatie tot Microservices: Cohesion/Coupling, Polyglot Microservices, Scalability
- Je kent de betekenis van de volgende Microservices-principes: Culture of automation, Modelled around business domain (DDD), Highly observable, Isolate failure (Design for Failure), Decentralize all things (freedom for the devops Teams)
Quiz
Test je kennis met deze korte multiple choice quiz.
Les 2 - ADR en ORM (EF core)
In deze les twee drieletterige afkortingen ADR en ORM, die niet per se heel veel met elkaar te maken hebben, maar wel allebei over documentatie/single source of truth gaan, en beide in je repository terecht komen (ORM Code first als code die het data model vastlegt, ADR als markdown bestanden die bij elkaar je software architectuur beschrijven). Beide horen wel bij DevOps en dragen dan ook bij CDMM Checkpoints; zie hiervoor de week opdracht.
"CDMM Beginner level Design & Architecture: At this level the importance of applying version control to database changes will also reveal itself." https://www.infoq.com/articles/Continuous-Delivery-Maturity-Model/
1. ORM - Object Relation Mapper
In de workshop zijn kort 'volumes' behandeld in Docker, die nodig zijn voor persistent opslag. Althans als je data langer moet bestaan dat de container, wat op productie het geval is, als je een database gebruikt.
Neem de Docker documentatie `Volumes' (negeer de oude constructie 'mounts' e.d. dit is alleen voor oudere containers die dit gebruikten).
Lees het artikel DevOps for databases van Christian Melendez (z.d.). Als oefening kun je de Contoso voorbeeld code downloaden, de dotnet ef tool installeren zoals het artikel aangeeft en de besproken oefening meedoen.
“Database refactorings […] involve three different changes that have to be done together
- Changing the database schema
- Migrating the data in the database
- Changing the database access code”
Quote 1: (Fowler, 2016)
Van de 3 wijzigingen uit quote 1 mist in simpele applicaties vaak het echte migreren van bestaande data. Dit vereist ook vaak het nadenken over hoe deze data te migreren en het handmatig schrijven/uitbreiden van de migratie code (de Up() en Down() methode in EF core.
1.1 Voorbeeld casus ORM: Data model van hypothetische CDMM applicatie
Het CDMM die wekelijks terugkomt, en je als student kan/moet gebruiken om je DevOps maturity te bepalen heeft ook een datamodel die wellicht nuttig is om expliciet te maken. In een les tekende ik dit grove data model (UML ERM diagram):

Figuur 1: ORM oefening. Het in een les besproken mogelijke klassendiagram voor de database in weekopdracht.
UML is prima om als 'schets' te gebruiken. Start on a whiteboard. Maar voor naslag is het wel nuttig een wat netter diagram te maken. Bijvoorbeeld met PlantuML of Mermaid zoals je al deed in weekopdracht 1: Documentation as code.
1.2 Upgraden naar diagrams as code
In bovenstaand diagram missen nog de categorie en het niveau van een 'CDMM checkpoint'. Oftewel hoe we het checkpoint in de tabel plaatsen qua kolom respectevelijk rij waar deze komt. In OO speak zijn dit CDMMCheckpointNiveau en CDMMCheckpointCategorie. Als we bovenstaande schets uitwerken tot een ERM diagram krijg je figuur 3. Dit ERD diagram geeft het gewenste datamodel van een CDMM Checkpoint.
[CDMMNiveau] Id Beschrijving Student 1--* CDMMSelfAssessment CDMMSelfAssessment 1--* CDMMEvaluation CDMMEvaluation 1--1 CDMMCheckpoint CDMMCheckpoint 1--* CDMMCategorie CDMMCheckpoint 1--* CDMMNiveau
[Student] *Naam +"Student nummer"
[CDMMSelfAssessment] Datum Student CDMMCheckpoint
[CDMMEvaluation] CDMMCheckpoint IsChecked Argumentatie
[CDMMCheckpoint] CDMMCategorie CDMMNiveau Code Titel Beschrijving
Figuur 2: ORM oefening. Het in de les besproken mogelijke klassendiagram voor de database in weekopdracht.
Op deze manier is het mogelijk voor een student om zelf een self assessment te doen door het CDMM in te vullen voor een bepaalde beroepsproduct en -project.
1.3 CDMM Applicatie -> User stories
Je zou zelfs een applicatie kunnen maken om CDMM beoordelingen te doen, waar dit nu nog een exercitie op papier is, of in markdown, om bij elke wekelijkse DevOps opdracht dit in te vullen, inclusief argumentatie voor het tonen van begrip cq. het verdiepen in CDMM.
Voor zo'n applicatie zijn hier enkele mogelijke user stories vanuit 'docent' en 'student' oogpunt.
- Als docent wil ik dat studenten een self assessment aan de hand van het Continuous Delivery Maturity Model (CDMM) kunnen maken en deze beargumenteren, zodat zij kunnen zien waar zij staan qua DevOps volwassenheid, en zich in DevOps best practices moeten verdiepen. - MUST
- Als student wil ik makkelijk een CDMM beoordeling kunnen invullen en hierbij achtergrond informatie krijgen over de verschillende CDMM checkpoints zodat ik informatie over bijbehorende punten kan krijgen, minder snel verkeerd interpreteer, en ook niet helemaal op de website te moeten opzoeken - SHOULD
- Als student wil ik makkelijk een ingevuld CDMM assessment kunnen exporteren, zodat ik deze — zowel als PDF en als markdown tekst — kan inleveren als bewijslast voor school en als markdown/documentation as code op kan nemen in mijn huiswerkopdrachten of beroepsproduct (DevOps BP) - COULD
- Als student wil ik iteratief een assessment invullen op verschillende momenten in een project en de ook zo kunnen terugzien, zodat ik vooruitgang zie en kan demonstreren in mijn project. - WANNAHAVE/WONTHAVE
Dit is een goede video om in de les samen te kijken ter relativering/van ORM's:
- Gorman, Christin (2011) (Vimeo). Zie bronnen.
Bekijk de Vimeo‑video (Gorman, 2011).
Ook 'Continuous Delivery' frontman Dave Farley haalt de video van Gorman aan in zijn boek Modern Software Engineering (tip!). Martin Fowler's artikel 'ORM hate' is een meer genuanceerde kijk op deze kwestie (Fowler, z.d.). Dat je geen SQL kennis zou hoeven te te hebben bij gebruik ORM is een drogreden, vanwege de ca. 10% gevallen die overblijft (en idd soms slechte performance). Hoewel de hoeveelheid SQL achtige annotaties in Gorman's wel wat hooggekozen is. Maar voor de resterende 10% moet je namelijk inzicht hebben in performance gevolgen. Voor SQL Server bv. van impact van bepaalde join volgorde en handmatige optimalisaties via keys toevoegen of verwijderen met hierachter technische concepten als 'table scan' vs 'index scan', etc. (Anvesh, 2023). En daarbij vergeleken is SQL syntax a walk in the park. Maar het 'single point of truth' of 'single point of definition' dat een goed ORM framework met ook 'migrations' mogelijkheden je kan geven. Al kom je als student niet snel in aanraking met een situatie waarbij je productie data hebt, die ook gemigreerd moet naast DB schema en applicatiecode, zoals Fowler in zijn artikel/blog 'Evolutionary database design' de big 3 aangeeft (Fowler, 2016).
1.4 Database First - overzicht en EF Core scaffolding
Bij Database First bestaat het gegevensmodel al als fysieke database: tabellen, kolommen, keys en relaties. Het database‑schema is de single source of truth. Vanuit deze bestaande database voer je code generatie uit (reverse engineering) om entiteitsklassen en een DbContext te maken. In EF Core doe je dit met scaffolding; migraties kun je daarna gebruiken voor vervolgwijzigingen, maar het initiële model komt uit de database, niet uit de code. Omdat het schema leidend is en al vastligt, speelt Convention over configuration hier minder een rol dan bij Code First (Wikipedia, z.d.)).
Scaffold (voorbeeld SQL Server):
dotnet tool install --global dotnet-ef
dotnet ef dbcontext scaffold "Server=localhost,1433;Database=cdmm;User Id=sa;Password=Your_password123;TrustServerCertificate=True" \
Microsoft.EntityFrameworkCore.SqlServer \
--output-dir Models \
--context CdmmContext \
--force
1.5 Model First - conceptueel
Bij Model First begin je met een conceptueel domeinmodel. Je tekent met een visuele editor een ER diagram van entiteiten en relaties en behandelt dat ER‑model als single source of truth. Vanuit het model laat je code generatie uitvoeren (entiteiten, DbContext) en genereer je het databaseschema. In moderne .NET projecten vloeit Model First vaak samen met Code First: je werkt primair in code, maar hanteert dezelfde gedachte van één bron waaruit alles volgt. EF maakt hierbij veel gebruik van Convention over configuration, waardoor je “in de pit of success” (zie Coding Horror) valt met standaardconventies en alleen expliciet configureert als de conventies niet voldoen. Migration‑bestanden gebruik je om de doorvoering van modelwijzigingen gecontroleerd en versieerbaar te maken.
1.6 EF Core Code First - minimale voorbeeldsetup
Voorbeeld van een kleine Code First‐setup met DbContext, DbSet<> en mapping.
// Domeinmodel
public sealed class Checkpoint
{
public int Id { get; set; }
public string Code { get; set; } = string.Empty; // bijv. "BD-203"
public string Titel { get; set; } = string.Empty;
}
// DbContext met DbSets en eenvoudige configuratie
public sealed class CdmmContext : DbContext
{
public DbSet<Checkpoint> Checkpoints => Set<Checkpoint>();
public CdmmContext(DbContextOptions<CdmmContext> options) : base(options) { }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
var cp = modelBuilder.Entity<Checkpoint>();
cp.ToTable("Checkpoint");
cp.HasKey(x => x.Id);
cp.Property(x => x.Code).HasMaxLength(16).IsRequired();
cp.Property(x => x.Titel).HasMaxLength(200).IsRequired();
cp.HasIndex(x => x.Code).IsUnique();
}
}
Registratie in .NET (bijvoorbeeld in Program.cs):
builder.Services.AddDbContext<CdmmContext>(opt =>
opt.UseSqlServer(builder.Configuration.GetConnectionString("CdmmDb")));
Connection string in appsettings.Development.json:
{
"ConnectionStrings": {
"CdmmDb": "Server=localhost,1433;Database=cdmm;User Id=sa;Password=Your_password123;TrustServerCertificate=True"
}
}
1.7 EF Core migraties - Up() en Down()
Een EF migratie klasse (gegenereerd met dotnet ef migrations add Init), versimpeld om het idee te tonen:
public partial class Init : Migration
{
protected override void Up(MigrationBuilder migrationBuilder)
{
migrationBuilder.CreateTable(
name: "Checkpoint",
columns: table => new
{
Id = table.Column<int>(nullable: false)
.Annotation("SqlServer:Identity", "1, 1"),
Code = table.Column<string>(maxLength: 16, nullable: false),
Titel = table.Column<string>(maxLength: 200, nullable: false)
},
constraints: table => { table.PrimaryKey("PK_Checkpoint", x => x.Id); });
migrationBuilder.CreateIndex(
name: "IX_Checkpoint_Code",
table: "Checkpoint",
column: "Code",
unique: true);
}
protected override void Down(MigrationBuilder migrationBuilder)
{
migrationBuilder.DropTable(name: "Checkpoint");
}
}
Apply migraties locally/in CI:
dotnet ef database update
1.8 Flyway - voorbeeldbestand en run
Flyway werkt met versioned SQL‐scripts. Voorbeeld bestandsnamen en inhoud:
sql/
V1__init_checkpoint.sql
V2__add_unique_index_on_code.sql
V1__init_checkpoint.sql:
CREATE TABLE checkpoint (
id INT PRIMARY KEY IDENTITY(1,1),
code VARCHAR(16) NOT NULL,
titel VARCHAR(200) NOT NULL
);
V2__add_unique_index_on_code.sql:
CREATE UNIQUE INDEX ux_checkpoint_code ON checkpoint(code);
Runnen (voorbeeld):
flyway -url="jdbc:sqlserver://localhost:1433;databaseName=cdmm" \
-user=sa -password=Your_password123 \
-locations=filesystem:sql migrate
1.7 Database First - overzicht en EF Core scaffolding
Bij Database First bestaat de database al (handmatig of via DBA gemaakt) en genereer je daaruit je ORM‐model en DbContext.
Stapjes in EF Core:
- Installeer de tooling lokaal (eenmalig):
dotnet tool install --global dotnet-ef
- Scaffold het model uit een bestaande database (voorbeeld SQL Server):
dotnet ef dbcontext scaffold "Server=localhost,1433;Database=cdmm;User Id=sa;Password=Your_password123;TrustServerCertificate=True" \
Microsoft.EntityFrameworkCore.SqlServer \
--output-dir Models \
--context CdmmContext \
--force
Daarna kun je verder met migraties (nieuwe wijzigingen) toevoegen zoals bij Code First. Het initiële model is echter uit de database afgeleid.
1.8 Model First - conceptueel
Bij Model First ontwerp je eerst het domeinmodel en leid je daaruit database en eventueel code af. Vaak gebruik je een visuele editor om een ER diagram te tekenen. Vanuit dat model kan vervolgens code generatie plaatsvinden (entiteiten, DbContext) en/of het genereren van SQL‐schema’s. Het model geldt dan als single source of truth: wijzigingen maak je in het model en deze worden doorgezet naar database en code.
Bij Code First is de bron juist de code. Je definieert C# klassen en mapping, en legt wijzigingen vast via een migration (EF Core migraties met Up()/Down()). EF hanteert hierbij vaak het principe van convention over configuration (Wiki) met verstandige defaults val je in de “pit of success” en hoef je minder expliciet te configureren; expliciete configuratie gebruik je alleen als de
conventies niet voldoen.
Samengevat in termen die je in antwoorden kunt gebruiken:
- Visuele editor: gebruikelijk bij Model First om het domein te modelleren.
- ER diagram: het diagram van entiteiten en relaties dat als startpunt dient bij Model First.
- Single source of truth: bij Model First is dit het model; bij Code First is dit de code.
- Code generatie: uit het model (Model First) of implicit door EF uit de code (Code First) naar DB‐schema.
- Migration: vooral gekoppeld aan Code First; incrementeel toepassen van schemawijzigingen.
- Convention over configuration: EF/ORM‐conventies verminderen configuratiewerk, met expliciete mapping waar nodig.
Architecture Decision Records
In moderne software development projecten wordt vaak te weinig gedocumenteerd. Nieuwe developers kunnen nergens overzicht krijgen over een project. Ook bestaande developers in een project vergeten soms waarom bepaalde keuzes zijn gemaakt en als er hier vragen over komen blijft het antwoord dan bij 'het is nou eenmaal zo'.
Een lichtgewicht manier om software architectuur te beschrijven zijn Architecture Decision records.
"Software architecture is those decisions which are both important and hard to change. This means it includes things like the choice of programming language, something architects sometimes gloss over or dismiss. ... Said another way, software architecture is those decisions which, if made poorly, will make a project either succeed or fail, in a needlessly expensive way." - https://kylecordes.com/2015/fowler-software-architecture
In plaats van eenmalig de hele software architectuur op te stellen sluiten ADR's aan bij de Agile aanpak, met het idee van een ADR is ook om telkens als er een beslissing is genomen, of voorstel is gedaan een ADR aan te maken. Dit zo ergens op schrift (e.g. in een repo) vastleggen is ook een manier om telkens terugkomende discussies te voorkomen volgense deze Reddit post.
ADR's zijn dus ook 'text records' die direct bij de code zitten; in versiebeheer. Typisch in de vorm van markdown .md bestand. De naam van het bestand geeft kort de beslissing weer, of het gebied waar deze zich bevind. Verder geef je de ADR's vaak ook een datum mee, en ook een status, van 'Proposed' tot 'Accepted' (of 'Rejected') en later mogelijk zelfs nog 'Deprecated'. Bekijk wat voorbeelden in de PriemChecker repo.
"ADRs' greatest strength is their low barrier to entry. Since anyone on the team can write an ADR, everyone who wants can fill the role of software architect." — Michael Keeling (2022)
ADR Templates
Hoe je deze keuzes vastlegt (documenteert) is weer een keuze op zich. Maar sowieso is het idee 'lichtgewicht' en direct bij de code in een tekst format, typisch markdown. Want de doelgroep is toch: mede developers/architects, kortom ICT'ers (en niet domein/business stakeholders, daar zijn andere documenten voor). Hierbij is het handig een template te gebruiken. Om de keuze stress op dit niveau wat te beperken, en zo te kunnen focussen op concretere en relevantere keuzes in techniek en domein modelleren beperken we in deze minor de opties hiervoor tot twee:
-
Y-statements - Wellicht wel de beste optie is een heel korte en krachtige variant van ADR's genaamd
y-statements(DocSoc, 2020). Dit is feitelijk een enkele zin, maar hierin zit ook al een stuk 'alternatives'. -
Nygard template - Of je gebruikt het template van Nygard, één van de grondleggers, volgens een artikel van Michael Keeling (2022). Omdat een 'decision' (=beslissing) ook opties impliceert (anders kies je nergens tussen) nemen we hierin ook alternatieven op. In het template van Nygard zit geen apart kopje, maar zouden alternatieven dan onder kopje 'Decisions' moeten. Of je plaatst ze al direct in de Context (zoals Nygard zelf deed in het artikel waarin hij ADR's introduceerde (Nygard, 2011)). Maar in het kader van het 'single responsibility' principe voeg je ten opzichte van Nygard's template een extra kopje toe:
Alternatieven. In het kader van ['The pyramid principle'] (Minto, 2002) plaats je deze sectie ACHTER de 'Decision'.
Binnen DevOps mag je echter afwijken van rigide standaarden, als er een goede reden is. DevOps ligt in het verlengde van Agile. Binnen Agile is een van de principes dat het gaat om "Individuals and interactions over processes and tools" (Agile Manifesto, Fowler et al., 2001). Ook het credo embrace change geeft ruimte voor zelf vormgeven van standaarden. In eerste instantie gaat 'embrace change' echter over het niet te moeilijk doen over wijzigingen in de software specificaties tijdens het ontwikkelen, als bijvoorbeeld de markt of regelgeving is aangepast.
Er bestaan ook tools om ADR records aan te maken. Maar de meerwaarde hiervan tn opzichte van alles handmatig doen is beperkt. De tool kan slechts een template neerzetten, de echte waarde (en tijdsbesteding) zit in het goed invullen van het template, en ook per keer nadenken welke van de kopjes relevant is en hoe in te vullen. Het is wel belangrijk dat de ADR's eenduidig zijn, en bv, allemaal een 'Status' hebben (proposed of al accepted, of in middels al weer deprecated). Maar je moet altijd voorkomen dat je als een robot templates invult, die vervolgens niemand wil lezen, omdat het toch niet zoveel zegt. Voorkom dat ADR's tot afvinkwerk verworden; zonder inhoudelijke afwegingen leveren ze geen waarde op.
Dit is een heel stuk korter dan de volledige ADR in Nygard (Henderson, 2023) met kopjes:
- Status: What is the status, such as proposed, accepted, rejected, deprecated, superseded, etc.?
- Context: What is the issue that we're seeing that is motivating this decision or change?
- Decision: What is the change that we're proposing and/or doing?
- Consequences: What becomes easier or more difficult to do because of this change?
Zie voor een voorbeeld voor de PriemChecker casus de docs/ADR folder in de PriemChecker repo voorbeeld van standaard straks in het project.
ADR vorbeeld casus: Web applicatie server
In de weekopdracht van deze week moet je de vorige week gemaakte applicatie uitbreiden naar een WEB API en ook hosten met een webapplicatieserver. Een veelgebruikte webapplicatieserver is nginx (spreek uit: 'Engine X'). Hiervoor maak je ook kennis met ADR's: Architecture Decision Records.
"What are alternatives to nginx when you want a webapplication server for a .NET application that you also want to containerize?"

Leerdoelen
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- Je kunt toelichten wat een ADR is, en waarom het documenteren van architectuurbeslissingen belangrijk is voor traceerbaarheid en langlopende projecten/lang draaiende software.
- Je kunt uitleggen wat een ORM is en hoe het het programmeren tegen relationele databases vereenvoudigt.
- Je kent het verschil tussen Code First, Model First en Database First aanpakken van ORMs als Entity Framework of Hibernate.
- Je kunt beschrijven wat de rol is van de Up() en Down() methodes bij Entity Framework
- Je begrijpt hoe migratietools zoals Entity Framework en Flyway bijdragen aan een DevOps-werkwijze door schemawijzigingen versieerbaar en reproduceerbaar te maken.
- Je kunt uitleggen wat Martin Fowler bedoelt met een evolutionary databases
Quiz
Test je kennis met deze korte multiple choice quiz.
Bronnen
- Anvesh, B. (2023, 1 augustus). Table scan vs index scan vs index seek. Medium. Geraadpleegd op 18 april 2024, van https://medium.com/silenttech/table-scan-vs-index-scan-vs-index-seek-f5cbb4e93478
- Fowler, M. (z.d.). ORM hate. MartinFowler.com. Geraadpleegd op 21 februari 2022, van https://martinfowler.com/bliki/OrmHate.html
- Fowler, M. (2016). Evolutionary database design. MartinFowler.com. Geraadpleegd op 21 februari 2022, van https://martinfowler.com/articles/evodb.html
- Gorman, C. (2011). Hibernate should be to programmers what cake mixes are to bakers: beneath their dignity. Vimeo. Geraadpleegd op 4 september 2025, van https://vimeo.com/28885655
- Melendez, C. (z.d.). DevOps for databases. Stackify. Geraadpleegd op 4 september 2025, van https://stackify.com/devops-for-databases/
- Nygard, M. (2011, 15 november). Documenting architecture decisions. Cognitect Blog. Geraadpleegd op 15 september 2025, van https://cognitect.com/blog/2011/11/15/documenting-architecture-decisions
- Wikipedia. (z.d.). Convention over configuration. Geraadpleegd op 15 september 2025, van https://en.wikipedia.org/wiki/Convention_over_configuration
- Atwood, J. (2007). Falling Into The Pit of Success. Coding Horror. Geraadpleegd op 15 september 2025, van https://blog.codinghorror.com/falling-into-the-pit-of-success/
Week 3 - Continuous Delivery
Lesoverzicht
- Micro-frontends + Deadline week opdracht 2
- C4 & Continuous Documentation + Oefentoets
- Deeltoets 1 + Weekopdracht bespreken & peer feedback
Deze week is het thema Continuous Delivery. We gaan even terug naar het begin: de business waarde en cultuur achter DevOps. Want Continuous Delivery maak je mogelijk door een 'DevOps aanpak' te hanteren.
"Continuous Delivery is the ability to get changes of all types—including new features, configuration changes, bug fixes and experiments—into production, or into the hands of users, safely and quickly in a sustainable way."" Jez Humble, continuousdelivery.com
Lees deze week de reader DevOps H10: 'Code Management' (NB: vragen in theorietoets!)
Week 3 Opdracht
Deze week gaan we de in vorige opdrachten opgezette applicatie geautomatiseerd builden, testen en opleveren door het opzetten van een pipeline zoals je al in de 1e opdracht al tekenden.

Minimaal build je een container, maar optioneel kun je deze ook live zetten en evt. nog extra lint stappen toevoegen. Blijf ook op security letten. Tevens beantwoord je een theorievraag rondom 12factor app methodology. De docent licht dit kort toe tijdens een les, maar dit is verder zelfstudie.
Nuttige bronnen:

- GitLab: Mastering continuous software development
- Installeren Jenkins lokaal in Docker container
- GitHub Actions
- Mr 'Continuous Delivery' Jez Humble over 'WaterScrumFall en hoe DevOps in verlengde van Agile ligt
- Martin Fowler: ObservedRequirement
- 12factor app principles for SAAS applications ('web applications')
- Wikipedia: Software rot of Software erosion zoals Heroku het noemde en 12factor introduceerde
Oefentoets
Test je kennis met deze korte multiple choice oefentoets voor week 3.
Workshop Micro Frontends
Voorbereiding
-
Lees uit het artikel Micro-Frontends op martinfowler.com (Jackson, 2019) de hoofdstukken:
- Benefits
- The Example
- Integration Approaches
-
Verzin 2 toetsvragen over het onderwerp van Micro-Frontends
- Zet je 2 vragen in de thread hierover op het MS Teams Team van je klas/de minor
- (Als deze er nog niet is, vraag je docent dan, of start deze thread zelf)
- Formuleer bij voorkeur een multiple choice vraag met 4 antwoord opties waarvan 1 goed is (en 2 anderen plausibel zin)
- Verzin een unieke vraag (e.g. hoe sneller je er een post, hoe makkelijker)
- De beste vragen kunnen daadwerkelijk in de toets komen
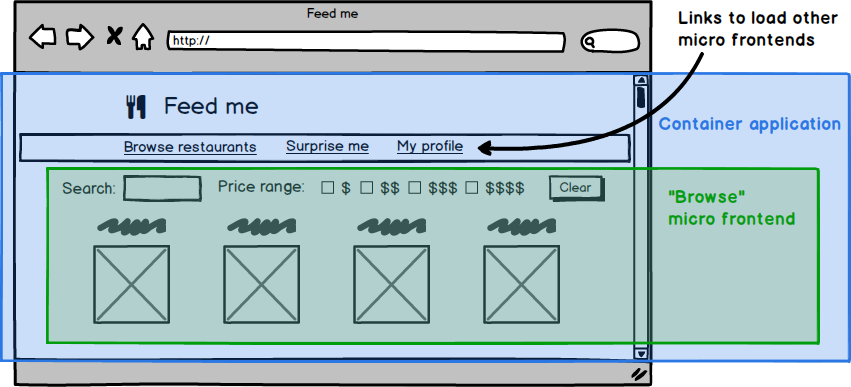
Figuur 1: De microfront-end architectuur volgt vaak component structuur op het scherm/ontwerp (Jackson, 2019)
Lesprogramma
- Bespreken toetsvragen
- Mentimeter
- In teams uit elkaar
- Build your own MF met create-mf-app
- Plenair samenkomen: benefits & integration approaches

Figuur: Microservices everywhere (bron: Aditya, 2022))
In teams uit elkaar
-
5 teams. Elk team krijgt één 'integration approach' om te gebruiken en een 'benefit' toegewezen om kort uit te leggen.
- Onderzoek hoe deze integration approach in zijn werk gaat.
- Onderzoek voor- en nadelen.
- Maak of vindt een kleine demo van approach
- Vat de toegewezen 'mf benefit' samen
- Presenteer je resultaten aan de rest van de klas
- Einddiscussie: Zou je MF's gebruiken in project, of niet. Wat is het alternatief? Als MF moet; welke integration approach zou jij het eerst kiezen voor front-end in het project?
Integratie methoden:
- Server-side template composition
- Build-time integration
- iframes
- JavaScript
- Web Components
Tip: Bij de integratie‑methode met iframes: bekijk als voorbeeld ook de ingebedde CDMM‑tabel met tooltips in de cheat sheet op deze website.
Voordelen:

- Incremental upgrades
- Simple, decoupled codebases
- Independent deployment
- Autonomous teams
- De 5e: Bonus, niet echt voordeel, maar leg de 'Two Pizza rule of Amazon uit' + hoe dit pizza plaatje aansluit bij onderwerp microfront-ends?

Create-mf-app
Ga nu in tweetallen aan de hand van het artikel van logrocket (Patel, 2024) zelf aan de slag met het maken van een MF-app.
- Maak een simpele applicatie waarin 2 micro-frontends met elkaar moeten communiceren of in ieder geval van de resultaten van een actie gebruik moeten maken. Bijvoorbeeld:
- Zoekbalk, Artikellijst
- Boodschappenmand, Productenoverzicht
- Spreek met je teamgenoot af hoe je tussen de 2 micro-frontends gaat communiceren. Denk na over opties als:
- pub-sub
- externe service
- browser internals
- store/state-manager die beiden applicaties toegang tot hebben (e.g. redux, mobx, vuex, rxjs)
Quiz
Test je kennis over micro front-ends met deze multiple choice quiz:
Leerdoelen
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- Je kunt gegeven een opdracht aangeven of een microfrontend een goede keuze is.
- Je kent het concept module federation, en kent twee andere manieren om micro-frontends met elkaar te integreren
- Je weet wat een micro-frontend is wat enkele voordelen ('benefits') hiervan zijn en kent de relatie met microservices.
Bronnen
- Aditya, P. (21-11-2022) Theory of Micro Frontends LinkedIn. Geraadpleegd 27 mei 2024 op https://www.linkedin.com/pulse/theory-micro-frontends-pavan-aditya-m-s/
- Jackson, C. (19 juni 2019) Micro Frontends martinfowler.com. Geraadpleegd 27 mei 2024 op https://martinfowler.com/articles/micro-frontends.html
- Patel, H. (18-3-2024) Build a micro-frontend application with React logrocket.com. Geraadpleegd 27 mei 2024 op https://blog.logrocket.com/build-micro-frontend-application-react/
C4 & Continuous Documentation
Deze les gaat over een van de 'Continuous Everything' zaken, namelijk Continuous Documentation. We kijken naar het C4 model van Simon Brown: Documentation for developers by developers! Daarna wat highlights van werk van HAN docent-onderzoeker Theo Theunissen rondom documentation in Continuous Software Development. Daarna naar Architecture Decision Records.
Maar eerst doen we een korte recap en aanvulling op InfoSupport's workshop over Domain Driven Design.
1. DDD + Microservices recap
Korte terugblik workshops over DDD respectievelijk microservices.
Samen bespreken DDD's strategic vs. tactical patterns, en korte recap van de 3 hoofd strategic patterns: Na de bespreking snap je deze termen hopelijk en kun je dit uitleggen. Anders geeft de website infiniot deze korte definitie, en moet je een bron vinden die het uitgebreider/beter voor je uitlegt:
- Ubiquitous Language – Een taal gestructureerd rond het domeinmodel en gebruikt door alle teamleden om alle activiteiten van het team met de software te verbinden.
- Bounded Context – Een beschrijving van de grens waarbinnen een bepaald model wordt gedefinieerd.
- Context mapping - Hoef je in deze cursus hoef je deze niet te kennen.
Deze laatste hangt wel vrij direct samenahngt met de andere twee, zoals een student al aangaf. En in de PitStop casus uit eindopdracht course fase zit een mooi voorbeeld van een Context Map waar je mee te maken krijgt.

Figuur 1: Ubiquitous betekenis (bron: Google translate)
Wellicht ken je al 'onion' of 'Ports and Adapters' architectuur. Hierbinnen zitten ook DDD tactical patterns als 'Repository' en 'Services' (met onderscheid tussen Application Services (technische glue) en Domain Services (business logica).

Figuur 2: DDD Tactical patterns: Onion architecture with 'lower level' DDD pattern (bron: Jordan Jordanov, J., Petrov P, 2023)
We zoomen in op de andere DDD tactical patterns:

Figuur 3: DDD Tactical patterns: Aggregate met Aggregate root en Entity vs Value object (bron: .NET Microservices Architecture for Containerized .NET Applications Figure 7-9. p. 203
Dit zijn meer 'implementatie in OO' gerichte patterns: Entity, Value Object en Aggregate. Een Aggregate geeft een idee van de minimale 'grootte' van een microservices definieren/beschrijven, Zoals je bv. leest in een online artikel van Microsoft Learn of Dave Taubler op Medium (edit 2024: helaas inmiddels achter paywal/abonnement):
"As a general principle, a microservice should be no smaller than an aggregate, and no larger than a bounded context. First, we’ll review the tactical patterns.” - Microsoft Learn (z.d.)
"... we [..] designed our microservices around Aggregates" - Dave Taubler (2020)
2. Continuous Documentation
Relevante vragen:
- Wat houdt 'Continuous Documentation' in?
- Wat is de relatie met 'Continuous Delivery' (en andere uit 'Continuous Everything'?)
- Kun je een praktijk voorbeeld van Continuous Documentation geven?
- Welke manieren van documenteren van Software ken je? (deliverables, methodes)
- Open vraag: Welke documentatie gebruik je binnen 'Ops werk'?
De 3 fasen van software documentatie volgens Theunissen (2021) (klik via 'Publicaties' onder https://theotheunissen.nl.
Lesopdracht: Maak een opsomming van veel vormen van documentatie die je als ICT'er in je opleiding/werkervaring bent tegengekomen. Verdeel deze daarna onder over de 3 fases;
- Upfront: Acquiring knowledge
- Development: Building knowledge
- Delivery: Transferring knowledge
Zijn er ook types die in meerdere fases horen?
3. Het C4 model
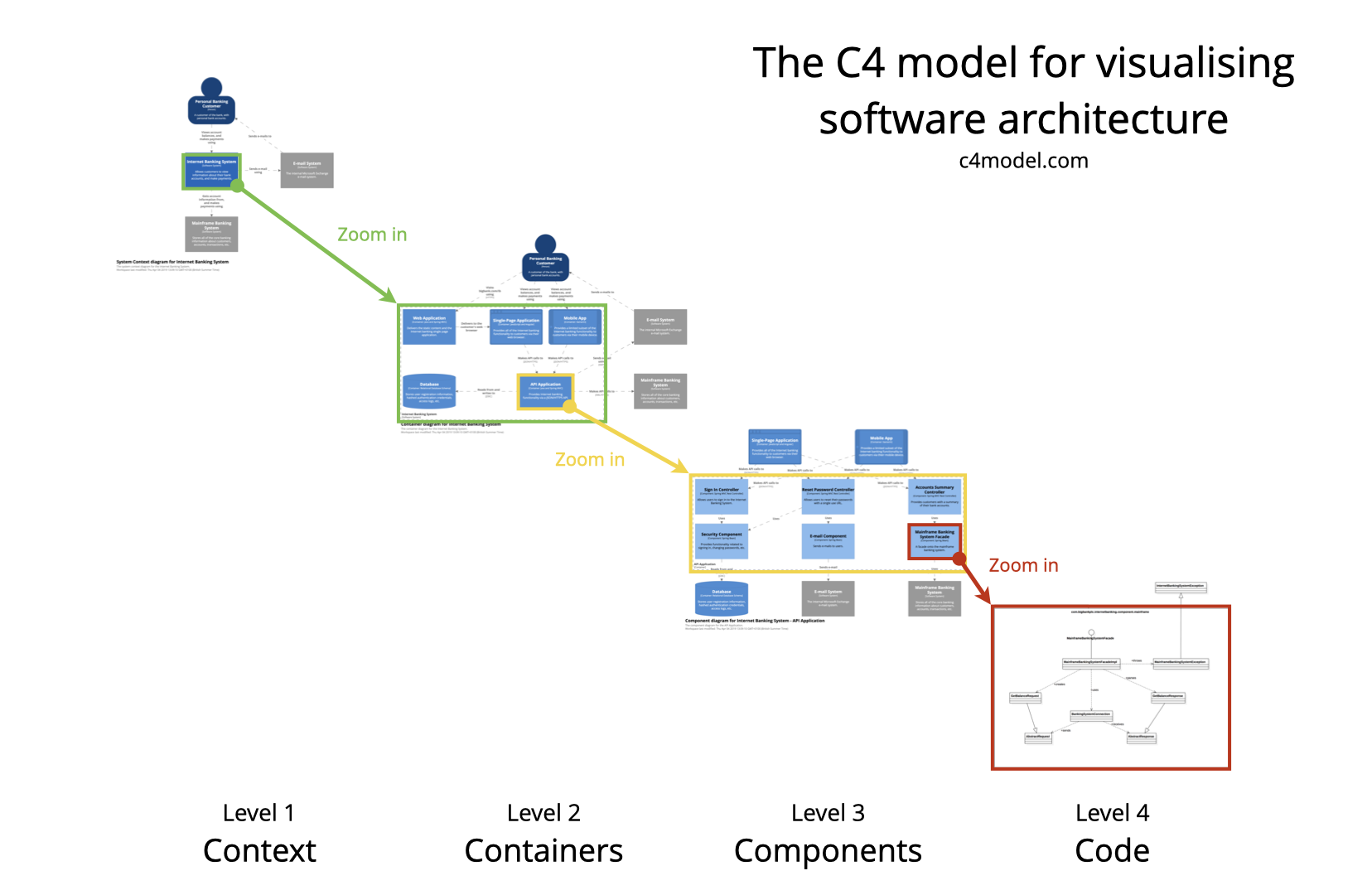
Figuur 1: © Simon Brown, c4model.com


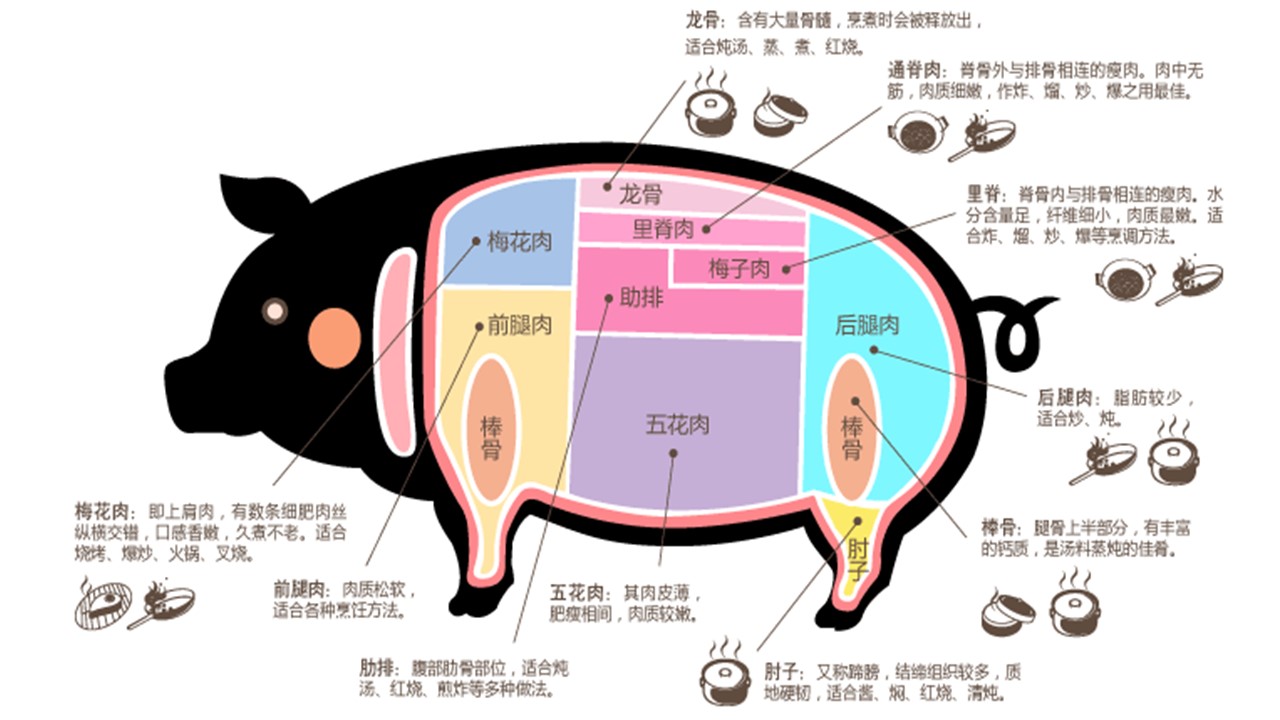
4. ADR's
In een eerdere les behandelden we al ADR's. Lees daar de uitleg, voorbeelden en bronnen terug.
"In the context of storing large prime candidates in our SQL database using Entity Framework Core, facing the need to accurately store numbers larger than the built-in SQL data types can handle, we decided for using a Value Converter to convert BigInteger to a string format for storage, and against using decimal or bigint storage formats, to achieve compatibility with extremely large numbers while maintaining database flexibility, accepting that this introduces performance overhead from conversion and adds complexity in the application logic."
Hieronder nog iets over de folderstructuur in dit project.
Folder structuur en toepassen Pyramid principle in documentatie
Qua folder structuur zet je de ADR's in folder /docs/adr en zet in zowel docs/ als docs/adr ook een README.md als 'landingspagina. De README.md onder adr geeft deze inleiding/leeswijzer en linkt naar alle ADR’s. Dit is ook de DoD (Definition of Done) voor ADR’s, namelijk het Nygard template format dat jullie hanteren (Henderson, z.d.) of Y-statements (Olzzio, 2023) hierboven genoemd.
Ook kun je verbanden leggen tussen verschillende ADR's. Als je bv. in het begin van je project kiest voor dataopslag met SQL Server, en dit vastlegt in een ADR, en gaande het project, bv. vanwege geheugengebruik issues van SQL switcht naar meer light weight database als PostgreSQL kun je deze aan elkaar koppelen. Of juist naar MongoDB vanwege partitioning eisen, of wat dan ook. Ook heb je keuze om hierbij twee technologie specifieke ADR's te maken (e.g. ADR-SqlServer.md en ADR-PostgreSQL.md) of een enkele ADR, met een meer functionele/semantische naam Data-Persistence.md die je aanpast. In de paragraaf hieronder een voorbeeld van een te gebruiken tekst. Zoals hier aangeven gebruik het 'standaard format van Nygard, maar vul deze aan met 'Alternatives'. Of - als je het graag zo kort mogelijk houdt - kijk eens naar 'y-statements' van Olzzio (2023).
Quiz
Test je kennis over continuous documentation en C4 met deze korte multiple choice quiz.
Leerdoelen
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- Je kunt uitleggen wat Continuous Documentation is en hoe het zich verhoudt tot Continuous Delivery.
- Je kent praktijkvoorbeelden van Continuous Documentation en kunt verschillende manieren van documenteren van software beschrijven.
- Je kunt het C4 model uitleggen en beschrijven hoe het helpt bij het documenteren van softwarearchitectuur binnen DevOps teams.
- Je kent twee manieren van architectuur beslissingen vastleggen met ADR's die je in het DevOps project gaat gebruiken
- Je kent de belangrijkste strategic DDD patterns zoals Ubiquitous Language, Bounded Context, en Context Mapping, en kunt het onderscheid uitleggen tussen strategic en tactical patterns.
- Je kunt voorbeelden geven van tactical DDD patterns zoals Entity, Value Object, en Aggregate, en weet dat aggregates een indicatie geven van minimale grootte van microservices.
Bronnen
Hier (nogmaals) de bronnen gebruikt op deze pagina in APA format.
- Brown, S. (z.d.). C4 model. Geraadpleegd op 23 september 2024 op https://c4model.com/
- Doc Soc (7-5-2020) Y-Statements - A light template for architectural decision capturing. Medium.com. Geraadpleegd september 2024 op https://medium.com/olzzio/y-statements-10eb07b5a177
- Google. (z.d.). Ubiquitous language betekenis via Google Translate. Geraadpleegd op 23 september 2024 op https://translate.google.com/?hl=nl&sl=en&tl=nl&text=ubiquitous&op=translate
- Jordanov, J., & Petrov, P. (2023). Domain Driven Design Approaches in Cloud Native Service Architecture. Geraadpleegd op 23 september 2024 op https://www.researchgate.net/publication/375982003_Domain_Driven_Design_Approaches_in_Cloud_Native_Service_Architecture/
- Keeling, M, (20 June 2022). Love Unrequited: The Story of Architecture, Agile, and How Architecture Decision Records Brought Them Together IEEE. Geraadpleegd dec 2023 op https://ieeexplore.ieee.org/document/9801811
- Microsoft. (z.d.). Implementing Value Objects with DDD. Geraadpleegd op 23 september 2024 op https://learn.microsoft.com/en-us/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/implement-value-objects
- Theunissen, T. (2021). Csimq: Continuous Software Development Documentation Artifacts. Geraadpleegd op 23 september 2024 op https://theotheunissen.nl/wp-content/uploads/2022/09/csimq.pdf
- Parker Henderson, J. Decision record template by Michael Nygard. Github.com geraadpleegd september 2024 op https://github.com/joelparkerhenderson/architecture-decision-record/blob/main/locales/en/templates/decision-record-template-by-michael-nygard/index.md
- Using tactical DDD to design microservices Microsoft Learn. Geraadpleegd september 2024 op https://learn.microsoft.com/en-us/azure/architecture/microservices/model/tactical-ddd
- de la Torre, C (2023) .NET Microservices Architecture for Containerized .NET Applications v7.0. Microsoft Coorporation. Geraadpleegd september 2023 op https://github.com/dotnet-architecture/eBooks/blob/main/current/microservices/NET-Microservices-Architecture-for-Containerized-NET-Applications.pdf
- Minto, B. (2002) The pyramid principle : logic in writing and thinking 3rd edition, Financial Times Prentice Hall
Continuous Delivery vs DevOps
Huiswerk
- Bekijk het interview met Gene Kim over 'zijn' 3 ways of DevOps
- Bekijk het animatiefilmpje van Rackspace over 'What is DevOps'
- Beantwoord voor jezelf onderstaande vragen over deze bronnen (zet deze in een markdown bestand `<les-cd-antwoorden-mijn-naam.md> in je weekopdracht)
- Lees deze week de reader DevOps H10: 'Code Management' ((Sommerville, 2018) students only acces in GitHub; NB: vragen in theorietoets!)
1 Vragen bij Reader DevOps
- Wat zijn de 3
hoofdpuntenbelangrijkste principes* van DevOps uit Sommerville's hoofdstuk over `DevOps and Code Management'? (p. 307) - Hoe verhouden deze 3 punten zich tot de punten uit de twee filmpjes over DevOps van Gene Kim en RackSpace? Schrijf wat je opvalt, wat verschilt en overeenkomt.
2. Vragen bij interview Gene Kim
Beantwoord de volgende vragen:
- Wat bedoelt Kim precies met zijn 'peeing puppy' analogie? Schrijf een korte paragraaf hierover.
- Hoe moeten jullie straks tijdens het tweeweekse project dat de DevOps course afsluit om gaan met deze 'peeing puppy'? (E.g. wanneer moet deze 'zindelijk' zijn?)
- Kun je beter beschrijvende namen vinden verzinnen voor de three ways dan Kim's cryptische 'First way', 'Second way' en 'Third way'? Geef deze! #namingThings
3. Vragen bij animatie filmpje DevOps
Beantwoord onderstaande vragen bij het filmpje. Dit is een check of je gekeken hebt, maar ook voor activering van je voorkennis en duidelijk krijgen verschil in voorkennis en mening tussen jou en collega studenten.
NB: Het is niet erg als je voorkennis niet hebt, beantwoord wel sowieso de vragen die het filmpje zelf geeft en de mening vragen. Je hoeft niet te gaan googlen o.i.d voor de overige, tenzij een vraag dit expliciet vermeldt.
- Welke 2 typische deploy omgevingen ('environments') worden genoemd in het filmpje? Welke hoort bij Anna en welke bij Dave?
- Ken jij nog meer omgevingen dan deze twee? Hoe noem je deze als ICT'er? Welke hiervan zal of moet elke ICT organisatie in ieder geval hebben?
- Vergelijk deze extra 'tussenliggende' omgevingen met de 2 van vraag 1. Stel dat de software een typische 3-tier webapplicatie is, e.g. website met wat business logica en een database voor persistentie. Welk van deze onderdelen verschilt van de andere? Hoe. En waarom? Geeft dit nog security risico's.
- Welke 3 problemen veroorzaakt de delay die Dave ervaart? Geef voor elk probleem aan of dit een probleem is voor Dave, Anna en/of het hele bedrijf.
- Wat levert Dave eigenlijk precies op aan Anna? Is dit code of software? Wat is eigenlijk het verschil hier tussen?
- Uit welke 2 componenten bestaat DevOps volgens het filmpje? (Niet 'Dev' en 'Ops'; kijk het filmpje!)
- Welke van deze twee denk je dat belangrijker is? Waarmee moet je beginnen? Welke van de twee is het makkelijkst te adopteren?
- Welk van deze twee besteden we de meeste tijd aan in de minor denk je? (En welke zouden we het meeste tijd aan moeten besteden vind je?)
- Welke 3e item/onderdeel blijft impliciet? Kun je nog een 3e onderdeel verzinnen bij DevOps?
- Met welke 3 soorten taken zorgt DevOps voor betere samenwerking en productiviteit?
- Een van deze 3 taken (taaksoorten) heeft met workflows te maken. Wat bedoelt de verteller met workflows?
- Iets verderop geeft het filmpje nog een lijstje van 3. Nu zijn het alle 3 'automatiseer' taken. Welk item is hier verschillend met het vorige lijstje van 3?
- Stel je houdt met DevOps bijvoorbeeld een grote e-shop in de lucht (zoals je zelf zult doen in het beroepsproduct aan het eind van deze course). Dan kun je de zogenoemde 'conversie ratio' bepalen (conversion rate). Leg uit wat dit is, zoek eventueel op.
- Wat heeft 'conversie' ratio met je antwoord op vraag 12 te maken?
- Welk soort code schrijf je in de DevOps role meer dan in een Dev rol?
Les overzicht
- Bespreken stelling
- Behandelen huiswerkvragen
- Bespreken problemen bij weekopdracht 3
- Pauze
- 12Factor app principles (of 15 factor..): Duo ~~presentaties`` pitches (belangrijk voor de toets)
- Video 'The Difference Between DevOps and Continuous Delivery' (13 min) kijken en nabespreken (Farley, 2021)
- Checken leerdoelen
Als er onvoldoende tijd is voor video dan thuis zelf kijken en nu korte samenvatting door docent).
Les inhoud
Stelling:
"Requirements are the things that you should discover before starting to build your product." - Bron...?

12factor app principles
Opsplitsen in duo's en verdelen 12Factor principles.
Elk duo leest beide leden de introductie op de 12factor.net website. Het beantwoorden van onderstaande vragen onderling bespreken helpt je bij het geven van een presentie.

- Waarvoor zijn de 12factor principles? Gebruik in je antwoord de term 'software erosion' en leg uit wat dit is
- Wat is het verschil tussen SaaS, PaaS en IaaS, en welke is relevant voor 12factor principle en waarom?
- Geef een voorbeeld op waarin het principe van toepassing was uit je eigen ervaring als ontwikkelaar of operations werkzaamheden, of verzin er eentje, evt. met hulp van google of ChatGPT.
Zelfstudie:
- Bekijk: 12 principles in 12 minutes (Travis Media). Studenten bereiden op basis van 12factor.net en evt. hiervan en de 12factor.net-teksten een korte duo-presentatie per factor voor.
Quiz
Test je kennis met deze multiple choice oefenquiz.
Leerdoelen Continuous Delivery
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- Je kunt iets vertellen over 'Continuous Delivery' en de relatie met DevOps
- Je kent het belang van DevOps cultuur en mindset
- Je kent de 'three ways' van DevOps
- Je kent het Agile manifesto en enkele principes ervan en kunt uitleggen hoe DevOps in het verlengde daarvan ligt
- Je kunt verschillende stadia en vormen noemen hoe DevOps in een bedrijf is doorgevoerd
- Je kent de centrale rol van de CI/CD pipeline binnen DevOps en de aansluiting op versiebeheer
- Je snapt het principe van refactoren en de term technical debt
- Je kunt een (scripted) pipeline inrichten in GitHub Actions (of evt, andere gewenste doel pipeline technologie zoals Jenkins 2, Jenkins X of Gitlab.com)
- Je kent de 12factor app methodology en kunt toetsen of je software conform een bepaalde factor is
Bronnen
- Farley, D., Continuous Delivery (24-3-2021) The Difference Between DevOps and Continuous Delivery youtube.com Geraadpleegd november 2024 op https://www.youtube.com/watch?v=-sErBqZgKGs
- Fowler, M. (16-9-2008) Observed Requirement martinfowler.com Geraadpleegd november 2024 op https://martinfowler.com/bliki/ObservedRequirement.html
- Kim, G. Hiller, P (6-6-2020) DevOps Gene Kim Defines the 3 Ways of The Phoenix Project Jack Caine op youtube.com, geraadpleegd oktober 2024
- Rackspace Technology (12-12-2013) What is DevOps? - In Simple English YouTube.com, Geraadpleegd oktober 2024 op https://www.youtube.com/watch?v=_I94-tJlovg
- Sommerville, I. (2018) Engineering Software Products H10 Code management
- Wiggins, A. (2017) The Twelve-Factor App. 12factor.net. Geraadpleegd november 2024 op https://12factor.net
- Travis Media (21-1-2024). 12 principles in 12 minutes [Video]. YouTube. Geraadpleegd op https://www.youtube.com/watch?v=FryJt0Tbt9Q&t=2s
Toetsen 1 & nabespreking
In deze les krijg je de eerste 2 toetsen. Hierna volgt een klassikale nabespreking. Individuele toetsinzage is op een later moment. Ook kijken we vooruit naar weekopdracht 3 en vind je vast een partner voor de opdracht (andere dan opdracht 2, terugwisselen mag, of nog keer afwisseling :).
- 9:00 Lokaal open, intro en regels
- 9:30 TheorieToets Dev
- 10:00 Pauze
- 10:15 Theorietoets DevOps
- 10:45 Pauze & Docent nakijken
- 11:30 Ruimte voor vragen en centrale nabespreking
- ..... Verdeling weekopdracht 3, vragen opdracht 2
Oefendeeltoetsen 1
Hier linkjes naar de oefentoetsen om beter beeld te krijgen van de echte toets op deze dag.
- Oefendeeltoets Dev 1
- Linux vragen uit gedane Cisco course van week 1 en 2 (zelfstudie)
- Oefendeeltoets DevOps 1
- Stof uit DevOps lessen week 1 en week 2:
- Algemene vragen DevOps: Culture, t-shaped professional, CDMM, Microservices architecture
- GitOps: Git commands & Git workflows, CI vs feature branch
- Containerization: Docker, containers, images, volumes, ORM/Evolutionary Database Design
- Stof uit DevOps lessen week 1 en week 2:
Nabespreking/vooruitblik week 3
- Reminder InfoSupport etentje 25 sept (aanmelden Slack!)
- Toets bespreken
- Maken duo's voor de week opdracht 3
- Verdeling 'platform' voor opdracht Continuous Delivery over duo's (GitHub Action/GitLab CI)
- Verdelen onderdeel 'stellingen 12factor' theorie-/deelopdracht (evt. bespreken in les)
Week 4 - Orchestration
Lesoverzicht
TODO, lesindeling in 2025 licht gewijzigd, voorheen was het als volgt:
- RabbitMQ
- InfoSupport 3/4
- InfoSupport 4/4
- Weekopdracht bespreken & peer feedback (CDMM, aanwezigheid, reflectie)
NB: De Kubernetes 101 les en praktische deel hierachter is in 2024 naar week 5 verplaatst.
"The portability and reproducibility of a containerized process [...] lets us move and scale containerized applications across clouds and datacenters.
We need tooling [...] to help automate maintenance, replacement and rollout of updates of the containers during their lifecycle!"
Docker docs - september 2021
Week 4 Opdracht
De week 4 opdracht in 2024/2025 is de opdracht rondom RabbitMQ. Toepassen van Kubernetes theorie in praktijk zit in week opdracht 5, samen met monitoring/prometheus.

![]()
Verder wordt de weekopdracht opengezet, moet iedereen weer een duo partner hebben (en bij oneven aantal één drietal).
Over de gevormde teams verdelen we de 3 te gebruiken techniek om van de in vorige opdracht gebruikte Docker compose naar Kubernetes te gaan:
Leerdoelen
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
-
DevOps-3 Je kunt werken met containers, gangbare software architecuren vertalen naar een container architectuur en de principes van container orchestration toepassen (Containerization)
-
DevOps-2-3 Kan applicatie onderdelen 'containerizen' en onderling laten communiceren
-
DevOps 2-4 Kent de rol van netwerken bij containers, en principes van een load balancer, firewall en proxy en relavante protocollen/standaarden
-
MDO-DevOps-3 - Containerization/Orchestration "Je kunt werken met containers, gangbare software architecuren vertalen naar een container architectuur en de principes van container orchestration toepassen (containerization)"
-
En de DDD en microservices leerdoelen n.a.v. Workshop InfoSupport. "Kent de basisprincipes van Domain Driven Design en kan deze toepassen en toetsen in DevOps code, configuratie en documentatie"
Oefentoets
Test je kennis met deze korte multiple choice oefentoets voor week 4.
Workshop RabbitMQ + BDD
De RabbitMQ workshop wordt aangeboden via GitHub Classrooms. Je krijgt automatisch toegang tot de workshop repository wanneer de assignment wordt geopend.
Les 1: RabbitMQ Fundamentals
Wat is RabbitMQ?
RabbitMQ is een open-source message broker die het Advanced Message Queuing Protocol (AMQP) implementeert. Het fungeert als een tussenpersoon voor berichten tussen verschillende services in een gedistribueerd systeem.
Waarom Message Queuing?
In traditionele monolithische applicaties communiceren componenten direct met elkaar via functie-aanroepen. In microservices architecturen is dit anders:
- Loose coupling: Services hoeven niet direct van elkaar af te weten
- Asynchrone verwerking: Services kunnen onafhankelijk van elkaar werken
- Betrouwbaarheid: Berichten worden opgeslagen en kunnen opnieuw worden verwerkt
- Schaalbaarheid: Services kunnen onafhankelijk worden geschaald
AMQP Componenten
RabbitMQ gebruikt het AMQP-protocol met de volgende kerncomponenten:
- Producer: Service die berichten verstuurt
- Exchange: Router die berichten ontvangt en doorstuurt naar queues
- Queue: Buffer waar berichten worden opgeslagen
- Consumer: Service die berichten verwerkt
- Binding: Regel die bepaalt welke berichten naar welke queue gaan
Exchange Types
RabbitMQ ondersteunt verschillende soorten exchanges:
- Direct Exchange: Routeert op basis van exacte routing key match
- Topic Exchange: Routeert op basis van wildcard patterns
- Fanout Exchange: Stuurt berichten naar alle gebonden queues
- Headers Exchange: Routeert op basis van message headers
Real-world Analogie
RabbitMQ werkt als een postkantoor:
- Producer = Afzender die een brief post
- Exchange = Postkantoor dat brieven sorteert
- Queue = Postvak waar brieven wachten
- Consumer = Ontvanger die brieven ophaalt
- Routing Key = Postcode die bepaalt waar de brief heen gaat
Vervolg: BDD en Cross‑Service Testing
Deze workshop heeft twee delen. In week 5 volgt een verdiepende les door Rody over BDD en cross‑service testing. Alle BDD‑theorie, voorbeelden en opdrachten staan in:
Quiz
Test je '101 kennis' over RabbitMQ met deze korte multiple choice quiz:
Leerdoelen
RabbitMQ Leerdoelen
- Je kunt uitleggen wat een message broker is en de rol beschrijven van RabbitMQ in verbeteren van 'loose coupling' van systemen.
- Je kunt het verschil beschrijven tussen verschillende messaging patterns, zoals work queues, publish-subscribe, routing en topics en gegeven een situatie/toepassing aangeven welke het geschiktst is.
- Je kunt de componenten van het AMQP-protocol beschrijven, zoals exchanges, queues, bindings en routing keys, en uitleggen hoe ze samenwerken in RabbitMQ.
- Je kunt uitleggen hoe RabbitMQ berichten routeert op basis van binding keys en routing keys.
- Je kunt van de verschillende types exchanges in RabbitMQ in ieder geval fanout uitleggen en bijbehorende use-cases benoemen.
- Je kunt een real-world analogie geven voor de werking van RabbitMQ, bijvoorbeeld door het te vergelijken met het sorteer- en bezorgproces van een pakketbezorgdienst.
BDD Leerdoelen
- Je kunt uitleggen wat BDD is en hoe het verschilt van traditionele test-driven development
- Je kunt Gherkin syntax gebruiken om user stories te beschrijven
- Je kunt BDD scenarios schrijven in Given-When-Then format
- Je begrijpt hoe BDD bijdraagt aan betere communicatie tussen stakeholders
- Je kent de relatie van BDD met TDD, DDD en Agile/DevOps
- Je kent de BDD three amigo's, en de 3 stappen van het iteratieve BDD proces
- Je kunt de verhouding uitleggen tussen BDD test scenario's, test cases en suites met user stories en acceptatiecriteria uit Scrum
- Je kent de test pyramide, het belang van de verschillende soorten testen hierin en de link met BDD
- Je begrijpt waarom de traditionele test pyramid niet meer geschikt is voor microservices architecturen
- Je kunt BDD gebruiken om cross-service communicatie via message queues te testen
Bronnen
Workshop Event Driven Architectures (EDA)
TODO: Pagina teksten herzien n.a.v. evt. nieuwe content/oefeningen in 2025.

Lesvoorbereiding
 Als je stap 3 van het bestand “Exercises in Domain Driven Design” niet hebt voltooid, doe dan het volgende:
Als je stap 3 van het bestand “Exercises in Domain Driven Design” niet hebt voltooid, doe dan het volgende:
- Voltooi het domeinmodel voor de bounded contexts die essentieel zijn voor de gameplay.
- Zet de klassen van het domeinmodel om in code met je voorkeursprogrammeertaal. Focus op het maken van klassen en hun attributen, niet op het implementeren van spelregels.
Lesprogramma / Lesmateriaal
- Lesmateriaal wordt via Teams gedeeld - nieuwe versies van presentaties
- Web Scale Architecture
- Chess Game DDD - Zie Git Repo
Leerdoelen
- Je kunt vier EDA‑stijlen (Event Notification, ECST, Event Sourcing, CQRS) uitleggen en vergelijken, inclusief voor‑ en nadelen.
- Je kunt het CAP‑theorem uitleggen en de trade‑offs tussen Consistency, Availability en Partition Tolerance onderbouwen.
- Je kunt Design for Failure toelichten (bulkheads) en het circuit‑breaker‑patroon toepassen.
Quiz
Test je kennis met deze korte multiple choice quiz.
Kubernetes 101
Deze les kijken we naar de 'Kubernetes architectuur', en alle componenten van Kubernetes. Formeel Kubernetes 'resources' genoemd, zoals Cluster, Node etc. De les begint echter met een recap van de vorige les en uitstapje over semantic versioning. En hieronder eerst het voorbereidende huiswerk.
Huiswerk
Doe het volgende huiswerk. Dit zijn 2 stukken documentatie over 'orchestration' van Docker en 2 korte opdrachten die hierop doorgaan:
- Lees de Docker: Orchestration, get started... documentatie en zet lokaal Kubernetes aan in Docker Desktop volgens de instructie (je hoeft NIET Docker Stack aan te zetten, dat is deprecated)
- Bekijk de 1e 12 minuten van deze presentatie van Edwin van Wijk (medewerker InfoSupport).
- Als je liever leest dan video's kijkt neem de onderdelen van de 'overview' van de Kubernetes docs op kubernetes.io door,
- Vanaf 2:11 begint het stuk over Kubernetes, na een intro over Docker, maar vanaf het begin kijken is wellicht wel zo relaxed
- Zorg dat je ieder geval de concepten Pods, Deployments en Services duidelijk hebt. Als de video hiervoor te kort/high level is; lees dan de kubernetes docs, of er is ook deze wat uitgebreidere versie om ook intro te krijgen in Pitstop en vergelijking K8S en Docker compose (vanaf ca. 6:00 tot ergens 30 a 40 minuten. Je kunt sowieso stoppen als Edwin Service Mesh gaat behandelen (dat zou mooi onderzoeksonderwerp zijn voor week erna, als je dit interessant vindt).
- De Kube proxy zorgt dat een pod via network bereikt kan worden en Kubernetes higher level concepten als een
NodePortkan realiseren.
A. Neem Figuur 1 voor jezelf op papier over, en breidt deze tekening met met concepten Cluster, Nodes en Pods uit met de overige Kubernetes resource types. Voeg hierin ook de ReplicaSet toe en lees hiervoor de volgende bron over ReplicaSets op website bmc.com.
- Merk op dat in deze overview de *Kubelet* voorkomt i.p.v. een pod. Een Kubelet is te zien als 'de Ops kant' van een Pod. Een Kubelet is een daemon programma dat draait op een server en van de server een K8S node maakt. Meestal gaat deze deel uitmaken van de *data plane* zodat de K8S *control plane* node(s) hier een Pod kan gaan draaien. Vanuit de 'Dev' kant heb je liever de pod als abstractie, dan kun je dit 'extra [niveau van indirectie](https://en.wikipedia.org/wiki/Fundamental_theorem_of_software_engineering)' negeren. Maar zeker een mogelijk onderzoek in week 6 om onder de moterkap te kijken naar schalingsmogelijkheden van pods of de Ops side van Nodes:
- Horizontal Pod Autoscaling *HPA)
- Hoe de kubelet een PodSpec te sturen.
- Hoe een Kubelet meer dan één pod beheren, zogenaamde 'side car pods'

Figuur 1: Diagram van een Kubernetes cluster.
B. Kijk naar Figuur 2 en klik er zo nodig op voor een grotere versie.
- Maak een schema/lijstje met opdeling van de Kubernetes commands's in de 'imperatieve' en 'declaratieve' commando's.
- En doe kort onderzoek naar de achtergrond hiernaar. Stel bv. ChatGPT een vraag hierover, en valideer wat je terug krijgt kort door te googlen naar andere bronnen.
- Bijvoorbeeld een relevante stackoverflow post.

Figuur 2: Kubernetes: imperatieve vs declaratieve commando's in Kubernetes
Kubernetes Architecture
Figuur 3 geeft weer een beeld van de K8S resources in de K8S architectuur.

Figuur 3: Kubernetes Resources
Dit zijn er best veel, dus staan we er even bij stil. Gelukkig waren de lessen over Docker (van vorige week) wel een springplank voor veel concepten. Probeer voor je zelf alle objecten op te halen en op te schrijven. Highlight hieronder de tekst om antwoord zichtbaar te maken.
- Cluster?
- Node
- Service
- Deployment
- ReplicaSet
- Pod
- Container?
- Bonus 1: Data plane vs control plane
- Bonus 2: K8S Client, K8S API?, ...
- Bonus 3: Taints vs tolerations
...
Figuur 3: (Een deel van) ChatGPT 4's poging tot een overzicht als Mermaid klassediagram.
Quiz
Test je '101 kennis' over Kubernetes met deze korte multiple choice quiz:
Leerdoelen
- Je kunt uitleggen wat Kubernetes is en dat je het gebruikt voor containerorchestratie.
- Je kent het onderscheid in Kubernetes tussen control plane en data plane.
- Je kunt het verschil uitleggen tussen de node types binnen Kubernetes (master en worker nodes) en hun rol binnen de cluster.
- Je kent Kubernetes resources zoals Pods, ReplicaSets en Deployments en kunt beschrijven hoe deze met elkaar verbonden zijn en welke functie ze vervullen.
- Je herkent de voordelen van declaratieve versus imperatieve Kubernetes commando's en kunt uitleggen hoe je deze toepast in verschillende scenario's.
Workshop Mission Critical Systemen & Afronding
Lesvoorbereiding
Deze les is een opraap les die optioneel ingaat op Mission Critical systemen, of anders afrondt/herhaalt van eerdere onderwerpen als deze langer duurden in de eerste 3 lessen. Dit is vrije invulling door de gastdocent.
Lesprogramma / Lesmateriaal
Mission Critical Systemen
Mission Critical systemen sluit deels ook aan bij bij de eisen voor het eindproduct uit de course fase:
- Security aspecten: scan op container en/of dependency niveau
- Update van dependencies en uitrollen ervan zonder regressiefouten of voor gebruikers merkbare glitches of functionele veranderingen
- Automatische schaling: bij meer of minder (gesimuleerde) gebruikers
- Fouttolerantie, Design for Failure en/of High Availability
- Uitvallende hardware of services erop heeft geen merkbare gevolgen (evt. Chaos engineering toepassen)
8 fallacies of distributed computing
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- Topology doesn't change
- There is one administrator
- Transport cost is zero
- The network is homogeneous
Afronding & Herhaling
- Terugblik op DDD, Microservices en Event Driven Architecture
- Praktische vragen en problemen uit eerdere lessen
- Voorbereiding op toepassing in eindproject
Leerdoelen
- Je begrijpt de kritieke aspecten van mission‑critical systemen.
- Je kunt security, schaling en fouttolerantie toepassen (incl. bulkheads/circuit breakers).
- Je kunt de 8 fallacies benoemen en toepassen (topologie en heterogeniteit).
- Je bent voorbereid om deze concepten toe te passen in het eindproject.
Quiz (under construction)
Semantic Versioning

Figuur 1: Semantic versioning (bron: Surjit Bains, CC BY-SA 4)
"Kubernetes versions are expressed as x.y.z, where x is the major version, y is the minor version, and z is the patch version, following Semantic Versioning terminology. - kubernetes.io
Opdrachten/zelfstudie
- Lees over Semantic Versioning op semver.org zodat je het begrijpt
- Welke onderdelen je wel of niet leest, mag je zelf bepalen, maar zorg dat je bij plaatje in Figuur 1 een verhaal kan vertellen over wanneer je welke van de 3 delen van een semver versie moet ophogen
- En beantwoord ook waarom de term 'semantisch' in de naam semver zit
- Denk eens na op welke zaken in een DevOps project je allemaal versies kunt geven.
Tijdens het project is semver ook een goede keuze. Je hebt echter de vrijheid om een eigen versienummer systeem te gebruiken. Zolang je dit documenteert/ernaar verwijst. Én er ook een goed idee achterzit. Dus bijvoorbeeld niet een 'anti naming pattern' zoals WendtVer die voor kenners wel vermakelijk is om te lezen.
"Let WendtVer provide you with a “fun” way to release and upgrade packages without having to think, saving you time and thinking."
Je mag er zelf over nadenken of alleen een git commit hash gebruiken als versienummer een goed idee is... :).
Als je een toepassing wilt kijken van semver die in een groot project ook erg handig is kun je eens kijken naar `conventional commits':
"[Conventional commits] dovetails with SemVer, by describing the features, fixes, and breaking changes made in commit messages." - https://www.conventionalcommits.org/en/v1.0.0/
Quiz
Leerdoelen
- Je kunt uitleggen wat semantic versioning inhoudt en waarom het nuttig is in softwareontwikkeling.
- Je kunt het verschil uitleggen tussen de drie onderdelen van semantic versioning en aangeven welk onderdeel je verhoogt in specifieke situaties.
- Je kunt uitleggen hoe je semantic versioning toepast om compatibiliteit te waarborgen tussen verschillende versies van een project.
Week 5 - SlackOps (monitoring)
Lesoverzicht
- BDD
- Alliander Workshop: K8s & GitOps
- Kubernetes 102
- Prometheus
- Semantic Versioning + Weekopdracht bespreken & peer feedback (CDMM, aanwezigheid, reflectie)
Zelfstudie: Chaos Engineering (zie Prometheus en Chaos Engineering)
BDD
Behavior Driven Development theorie en praktijk.
Alliander Workshop: K8S & GitOps
Alliander gastles.
Prometheus/PromQL en Chaos engineering/Load testing
Kijk verder naar les over Prometheus en chaos engineering.
Week 5 Opdracht
De weekopdracht voor week 5 wordt behandeld tijdens de les over Semantic Versioning. Deze les omvat ook peer feedback en bespreking van de opdracht.
Zie Weekopdrachten werkwijze voor uitgebreide informatie over de werkwijze, groepsvorming, peer review en inleverprocedures.
Leerdoelen
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- MDO-DevOps-5 - Slackops "Je kunt goede logging en monitoring realiseren in verschillende omgevingen en zorgen voor applicatiespecifieke rapportages"
- Ops-2-1 Je kent de principes van chaos engineering en de toegevoegde waarde hiervan
Oefentoets
Test je kennis met deze korte multiple choice oefentoets voor week 5.
BDD - Behaviour Driven Development
Huiswerk/opdracht
a. Bestudeer de theorie over Behaviour Driven Development zodat je theorie achter de BDD leerdoelen van deze week haalt. De keuze is afhankelijk van of je Java of .NET hebt gekozen in je weekopdracht:
- Bestudeer het materiaal van de 'Cucumber' (Java)
- Of
SpecFlow (.NET)ReqNRoll (.NET) frameworks.
Onderstaand de opzet uit 2024, de docent past dit waarschijnlijk aan, en dan krijg je sheets; of volgt hier nieuwe info.
b. Opdrachten (maak tot en met opdracht 4, de rest in de les):
- Pak uit de Opdracht voor de DevWorkshop de
EuroCard service, maak hier (eigen keuze) een Java of .NET project voor aan, voeg BDD dependencies en tools toe (zie PluralSight) en voeg volgens BDD stijl Cucumber of Specflow tests toe en realiseer zo test-first de methoden. - Installeer hiervoor IntelliJ als je deze nog niet hebt/had (jaar gratis Ultimate editie voor HAN/AIM studenten) of Microsoft Visual Studio
- Schrijf Gherkin code (
given,when,then) voor 4 testgevallen credit cards nummers:1,2,1023en208724 - Schrijf glue code ('Step definitions')
- Refactor de 4 tests naar één enkele Gherkin 'datatable'
- Schrijf evt. ook dezelfde tests in TDD stijl (JUnit/XUnit).
- Moet er nog een validatie en aparte melding bij voor credit card nummers met ongeldig format? (eigenlijk zouden ze zo moeten zijn:
6703 4444 4444 4449(bron) en zou je ook een 'issuer check` kunnen doen). - Waarom wel, of waarom niet? En zo ja, hoe documenteer je dit? (want het staat niet in huidige spec)
Lesprogramma / Lesmateriaal
- Doornemen leerdoelen high level
- Behandelen theorie
- Beantwoorden vragen n.a.v. huiswerk en lesvragen
- Zelf verder aan de slag met BDD (optioneel in 2024)
Les inhoud / BDD Theorie
Hier wat korte theorie over BDD uit verschillende bronnen, namelijk over de relatie met TDD en DDD uit de Wikipedia definitie, iets over de Three Amigo's (wie) en het 3-staps proces +1 (hoe). Tot slot iets over verschillende namen BDD, ATDD en SBE en quotes van Martin Fowler en Dave Farley.
BDD definitie en relatie met andere *DD's
We beginnen met de definitie van BDD op Wikipedia (2023):
"In software engineering, behavior-driven development (BDD) is a software development process that goes well with Agile software development process that encourages collaboration among developers, quality assurance experts, and customer representatives in a software project. It encourages teams to use conversation and concrete examples to formalize a shared understanding of how the application should behave.
[...] Behavior-driven development combines:
- the general techniques and principles of TDD
- with ideas from domain-driven design (DDD)
- and object-oriented analysis and design
to provide software development and management teams with shared tools and a shared process to collaborate on software development."
BDD's relatie met andere *DD's: Ook test driven en testen 'inherente complexiteit'
Een belangrijk basisbegrip is 'self testing code'. Het is altijd goed het origine artikel van Martin Fowler hierover te lezen. Zijn onderstaande plaatje vat dit kort samen met beeld van code 'met een knop' die zichzelf kan testen. Maar dit kan een onervaren ICT'er onterecht het beeld geven dat je code kunt maken die op een of andere magische wijze zichzelf test (met een tool ofzo). En dat is natuurlijk niet het geval.
")
Een iets uitgebreidere samenvatting van 'self testing code' is dat je deze 'knop' realiseert door in een code naast de applicatiecode ook test code op te nemen. Deze test code roept de applicatiecode aan, en controleert dat deze de verwachte output krijgt. Hierbij is ook het doel dat er een hoge 'code coverage' haalt, typisch een line coverage van 80% in onze opleiding. Maar de afspraak hierover verschilt per bedrijf, en is ook afhankelijk van de complexiteit van de codebase (die - bij DDD aanpak - als het goed is vooral afhangt van de complexiteit van het onderliggende domein...). De vereiste code coverage hangt ook af of de codebase een monoliet is, of een microservices architectuur (MSA) heeft. Bij die laatste krijgen integratie testen meer belang en unit tests wat minder, en is code coverage minder van belang (want bij integratie tests is het geautomatiseerd bepalen van code coverage onmogelijk, of in ieder geval ingewikkelder/nog niet standaard).
Hoe dan ook, de interne werking is dus:
Figuur 2: Intern onderscheid tussen test code (grote O 1) en (vangt de 'inherente' complexiteit conform DDD)
Net als TDD gaat BDD een stap verder dan enkel 'self testing code', want BDD is ook 'test driven'. Door eerst de test code te schrijven, denk je meteen vanuit 'client' kant aan welke interface je methode moet hebben, hoe je deze aanroept, en wat deze teruggeeft. Deze 'HOE roep ik het aan?' zit meer aan de WAT kant: "WAT is de interface", omdat de echte 'hoe' kant is: 'Hoe implementeer ik de code zodat deze daadwerkelijk het verwachte resultaat' teruggeeft. TDD grondlegger Kent Beck (van het Agile Manifesto) noemt dit in zijn article 'Canon-TDD' (2022) de 'Interface/Implementation Split':
"The first misunderstanding is that folks seem to lump all design together. There are two flavors:
- How a particular piece of behavior is invoked.
- How the system implements that behavior."
BDD -> Geen unit maar integratie tests!
BDD richt zich primair op integratie- en end-to-end tests die het gewenste gedrag valideren over componentgrenzen heen. Unit-tests zijn nuttig, maar niet het doel van BDD.
The Three Amigo's
Figuur 1: The three amigo's en het BDD proces met 3 stappen+1(van Pluralsight)
"The 'Three Amigos' is a meeting that takes user stories and turns them into clean, thorough Gherkin scenarios. It involves three voices (at least):
- The product owner
- The tester
- The developer
https://johnfergusonsmart.com/wp-content/uploads/2017/11/iStock-147318638-1024x683.jpg
Figuur 2: The three amigo's, niet per se 3, niet per se Spaans, maar wel per se >=3, divers en onderling vriendschappelijke omgang :)
BDD: 'Executable specifications' en synonieme acro's voor BDD
Gherkin is the most commonly used plain-text language for writing executable specifications in Given-When-Then-And-But steps. These scenarios are commonly saved as .feature files.
Feature: Users should be able to book appointments.
Scenario: A user wants to book an appointment.
Given a user has booked an appointment
When the booking status is timed out
Then the appointment will be not confirmed
Bron: 'What are executable specifications?' - Cucumber.io blog, 7-2-2019
... "BDD aims to express requirements unambiguously, not simply create tests. The result may be viewed as an expression of requirements or a test, but the result is the same. Acceptance tests record the decisions made in the conversation between the team and the Product Owner so that the team understands the intended behavior.
There are three alternative labels to this detailing process:
- Behavior Driven Design (BDD)
- Acceptance Test–Driven Development (ATDD)
- Specification by Example (SBE)
Bron & ©: Scaled Agile, Inc.
Lesvragen
Behandelen opgekomen studentenvragen n.a.v. huiswerk of behandelde theorie. Als er geen vragen zijn, dan staan we even stil bij deze vragen:
- Kun je in algemeen zowel TDD als BDD doen in een project, of moet je kiezen?
- Welke CDMM checkpunten zijn relevant voor BDD?
- Voor Java is er Cucumber, voor .NET is erSpecFlow of ReqNRoll, maar welke taal gebruik je wel in beide voor BDD?
- Wat is een test suite? Heeft een applicatie een testsuite?
- Het Gherkin voorbeeld op de pagina toont één feature met één scenario. Is dit typisch, of horen bij één feature vaak meer scenario's, of bij één scenario meerdere features?
Quiz
Check je kennis over BDD met onderstaande korte multiple choice toets.
Leerdoelen
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- Je kent de relatie van BDD met TDD, DDD en Agile/DevOps
- met o.a. relevante begrippen als Ubiquitous Language, test-first, red-green-refactor, AAA pattern, given-when-then en collaborative development
- Je kent de BDD three amigo's, en de 3 stappen van het iteratieve BDD proces
- Je kent 2 andere namen van BDD, en kunt deze uitleggen
- Je kent de term 'self testing code' en het onderscheid tussen
.featurefiles, glue code en applicatie code en de talen/standaarden die hier achterin zitten - Je kunt de verhouding uitleggen tussen BDD test scenario's, test cases en suites met user stories en acceptatiecriteria uit Scrum
- Je kent de test pyramide, het belang van de verschillende soorten testen hierin en de link met BDD
- Je kunt op basis van een tutorial een project met werkende en relevante BDD tests opstellen m.b.v. Cucumber of Specflow (ReqNRoll)
Bronnen
- Beck, K. (1-12-2023) Canon TDD - Software Design: Tidy First? Substack.com. Geraadpleegd september 2024 op https://tidyfirst.substack.com/p/canon-tdd
- Fowler, M. (1 mei 2014) Self Testing Code martinfowler.com Geraadpleegd september 2024 op https://martinfowler.com/bliki/SelfTestingCode.html
- Cucumber.io (z.d.) What are executable specifications? Geraadpleegd september 2024 op https://cucumber.io/blog/hiptest/what-are-executable-specifications/
- Scaled Agile (z.d.) Behavior-Driven Development (BDD) Geraadpleegd september 2024 op https://scaledagileframework.com/behavior-driven-development
Kubernetes 102
NB In 2024 behandelen we in deze les ook nog niet eerder behandelde onderwerpen uit de Kubernetes-101 les
Deze les geeft Kubernetes verdieping en dient om aan de slag te kunnen met je eigen Kubernetes Rancher cluster onder aimsites.nl en hierop een kleine microservice applicatie te kunnen runnen (PitStop).
Huiswerk/voorbereiding
Dit is het huiswerk voorafgaand aan de les:
- Neem als recap van de vorige les het artikel Kubernetes 101 door
- En ook de blog post 'Kubernetes Ingress vs Load Balancer'
- Neem high level de 3opties door voor migratie uit Docker compose in artikel van Milind Chavan (2021)
- Lees de documentatie over Kompose op de Kubernetes docs.
- Beantwoord onderstaande 8 huiswerkvragen. Zoek o.b.v. dingen die hierin onduidelijk zijn zelf relevante stukken uit de volgende bronnen (eigen keuze/leerwegonafhankelijk)
- de Kubernetes documentatie (kubernetes.io) over meer gedetailleerde werking van Deployments, Replicasets, Ingress en Services.
- Of meldt je aan voor de gratis (fremium) Linux Foundation course over Kubernetes en neem hoofdstuk '8. Kubernetes building blocks en '10 Services' door.
Huiswerkvragen
- Noem 3 opties om te upgraden vanaf docker compose naar Kubernetes
- Noem een voordeel van elk van deze 3 opties
- Kun je op productie ook Docker en Docker compose gebruiken? Noem minstens 1 reden waarom je dit zou willen, en 2 waarom niet.
- Wat betekent "Pods are used as the unit of replication in Kubernetes."
- Wat betekent 'round robin'? Google het zo nodig (staat niet in de bronnen) leg het uit
- Wat is DNS en hoe gebruikt Kubernetes dit?
- Op welke (wel/andere) behandelde 'resource' lijkt een Kubernetes
DaemonSet? - Zelfde vraag voor de (verouderde) K8S resource
ReplicationController: a. met welke resource(s) hangt deze samen? b. waarom is deReplicationControllergedeprecate? vind in bron, of vraag bijvoorbeeld aan ChatGPT en evalueer diens antwoord en zorg dat je het zelf snapt/kan reproduceren
Les
Kubernetes (K8S) is een te groot onderwerp om geheel in één week te kunnen behandelen. Hier zou je ook een hele minor mee kunnen vullen.
De bedoeling is dat je basis K8s Architectuur en K8S componenten en concepten kent en hier mee om kunt gaan. Zodat je m.b.v. kubectl en extra benodigde vaardigheden tijdens opdracht en project relatief snel kunt uitzoeken met behulp van deze 'kapstok van kennis' die je al hebt.
In deze les kijken we naar:
- Terugblik Kubernetes architectuur (vragen vorige lessen)
- Het YML format en de relatie met JSON
- K8S advanced onderwerpen 'Ingress'
- K8S advanced onderwerp 'etcd' (en de relatie met High Availability clusters)
- Optioneel: het begrip 'Quality of Service' in algemeen, en specifiek in K8S in verband met mogelijk onderzoek.
- Workshop ArgoICT over Kubernetes (en K8S 'workloads')
1. Lesopdracht/-uitstapje: JSON vs YAML
Bekijk de website https://www.json2yaml.com/ en experimenteer hiermee. Zorg dat je duidelijk krijgt de link tussen JSON en YAML.
2. Lesvragen .yml
-
Is YAML ook JSON?
-
Hoe ziet een JSON array eruit bij omzetten naar YAML?
-
Hoe ziet een JSON object eruit? Wat is het verschil en overeenkomst met een array?
-
Maak een YAML bestand met een lijst van namen van jezelf en 3 studenten die om je heen zitten. Zet erna in het bestand ook de informatie over jezelf qua:
- 'lievelingskleur'
- 'favoriete film'
- 'hobby'
-
Vraag ook een van de 3 klasgenoten deze 3 'properties' en vul in
-
Ken je nog meer talen/formats die onderling zo'n zogenoemde 'superset' zijn van een andere taal/format? Schrijf op welke. Wat is het voordeel?
3. Nog 2 K8S onderwerpen: Ingress en etcd
Interessant én relevant stuk theorie is de werking van etcd, het gedistribueerde opslagsysteem waar K8S de eigen config opslaat. En wat ook een beeld geeft van kwesties rondom 'database sharding' en ook 'clustering' en 'voting. Bekijk deze korte intro:
We bekijken samen de video Kubernetes Ingress in 5 mins - Sai Vennam, IBM (5:40 minuten)
- What is etcd? - Whitney Lee, IBM (6 minuten)
Lesvragen Ingress en etcd
- Wat hebben K8S Ingress en etcd met elkaar te maken? (if any)
- Wat is het verschil tussen een Ingress en een Service?
- Bedenk zelf een toetsvraag over Ingress en zet in Teams
- Wat is een HA cluster in K8S?
- Wat heeft het aantal met het Raft voting systeem te maken?
- Wat is een 'etcd. member' en zit deze in control plane of data plane?
Optioneel: Quality of service in K8S
Een opstapje naar 'advanced Kubernetes' is wel het concept 'Quality of Service' (QoS) en implementatie en werking hiervan in Kubernetes.
Dit zou een mooi onderzoek zijn voor wie deze meer 'Ops side of things' wil verkennen.
Workshop "K8S op Rancher - Kubernetes een beetje praktisch" - Argo ICT

Het bedrijf Argo ICT uit Arnhem, met oud HAN student Murat Castermans geeft een hands-on uitleg bij het gebruik van een Rancher cluster voor de laatste opdrachten in de course fase.
Argo ICT moet je niet te verwarren met de vaak in het blok 2 gebruikt project te gebruiken tool Argo CD :). Argo ICT regelt de complexere ICT benodigheden voor HAN ICT en AIM, maar hebben ook andere klanten.
Samenvatting presentatie
Hier de link naar de presentatie (Google Slides)
Enkele quotes/samenvatting
Kubernetes is 'meer dan alleen maar schaalbaar' "Je hebt iemand die continue over je schouders meekijkt".
- Aantal issues tackled K8S zelf, heeft bv. probes voor detecteren van memory leaks, zodat je 's nachts niet wakker wordt gebeld.
- Je hoeft geen rekening houden met allerlei zaken aan de achterkant, zoals het configureren van Nginx, of OS specifieke zaken.
- Je hebt minder last van vendor lock-in. Zolang het maar 'Certified Kubernetes' is.
Soorten workloads in K8S
Quote uit de Kubernetes docs over 'workloads'
"A workload is an application running on Kubernetes. [...] Kubernetes provides several built-in workload resources:
(Uit de sheets van Murat):
Deployment- Alles stateless, maakt niet uit welke node en of er storage is, makkelijk schalen, bv. een JavaScript front-end in een Nginx containerStatefulSet- Wel storage, geisoleerd van andere storage, bv. voor database serverDaemonset- K8S zorgt dat deze 'service' elke Node zorgt , bijvoorbeeld voor logging services (zoals FlentD)
Verdere highlights
K8S kent 3 soorten probes: Startup, Readiness (traffic) en Liveness (kill)
Gebruik voor testen op je eigen K8S cluster op aimsites een port forward, i.p.v. een NodePort setting (zoals je op localhost wel doet).
RWO = 'Read Write Once', wordt niet getoetst, wel interessant voor onderzoek evt. (access modes van K8S PersistentVolumeClaim)
Quiz
Test je kennis met deze korte multiple choice quiz.
Leerdoelen
Check met onderstaande leerdoelen of je de behandelde stof begrepen hebt en toetsvragen kunt beantwoorden.
- Je kunt uitleggen wat de rol van Pods is als replicatie-eenheid in Kubernetes.
- Je begrijpt hoe Kubernetes Ingress werkt en hoe het verschilt van een Service.
- Je kunt uitleggen hoe een HA cluster werkt in Kubernetes en waarom minstens drie master nodes vereist zijn voor etcd consensus.
- Je kent de voordelen van migreren van Docker Compose naar Kubernetes en weet hoe tools zoals Kompose en Skaffold hierbij helpen.
- Je kunt de functie van een
DaemonSetin Kubernetes uitleggen - Je kent het voorbeeld van de
ReplicationControlleruit de K8S die is gedeprecate en vervangen doorReplicaSetals voorbeeld van verbeteringen en verandering in Kubernetes historie - Je kunt het verschil tussen JSON en YAML uitleggen aan de hand van hun relatie en voorbeelden en kan uitleggen waarom men
.ymlvaker voor K8S config gebruikt
Workshop Alliander - DevOps bij Alliander: ArgoCD & GHA & Pax

Het bedrijf Alliander uit (o.a.) Arnhem komt in onze minor een workshop geven over 'DevOps bij Alliander'!
Huiswerk
De informatie uit deze workshop overlapt deels met de Kubernetes 101 les. Maak het huiswerk/de voorbereiding daarvan.
Alliander: netwerkbeheer
Dit zijn de slides van de presentatie van Alliander:
Alliander doet netbeheer, maar is effectief ook een ICT-bedrijf met 100-en ICT'ers in dienst. Slimme ICT is een belangrijk onderdeel van hun bedrijfsvoering en absoluut noodzakelijk in het kader van de energietransitie, wat in de huidige maatschappij erg belangrijk is.

Alliander: ICT
Kortgezegd gebruikt Alliander ook het onderdeel GitOps uit DevOps en hierbij van tools als Kubernetes, GitHub Actions en ArgoCD.
- ArgoCD is een tool voor GitOps volgens een 'pull based model' (voor Continuous Deployment)
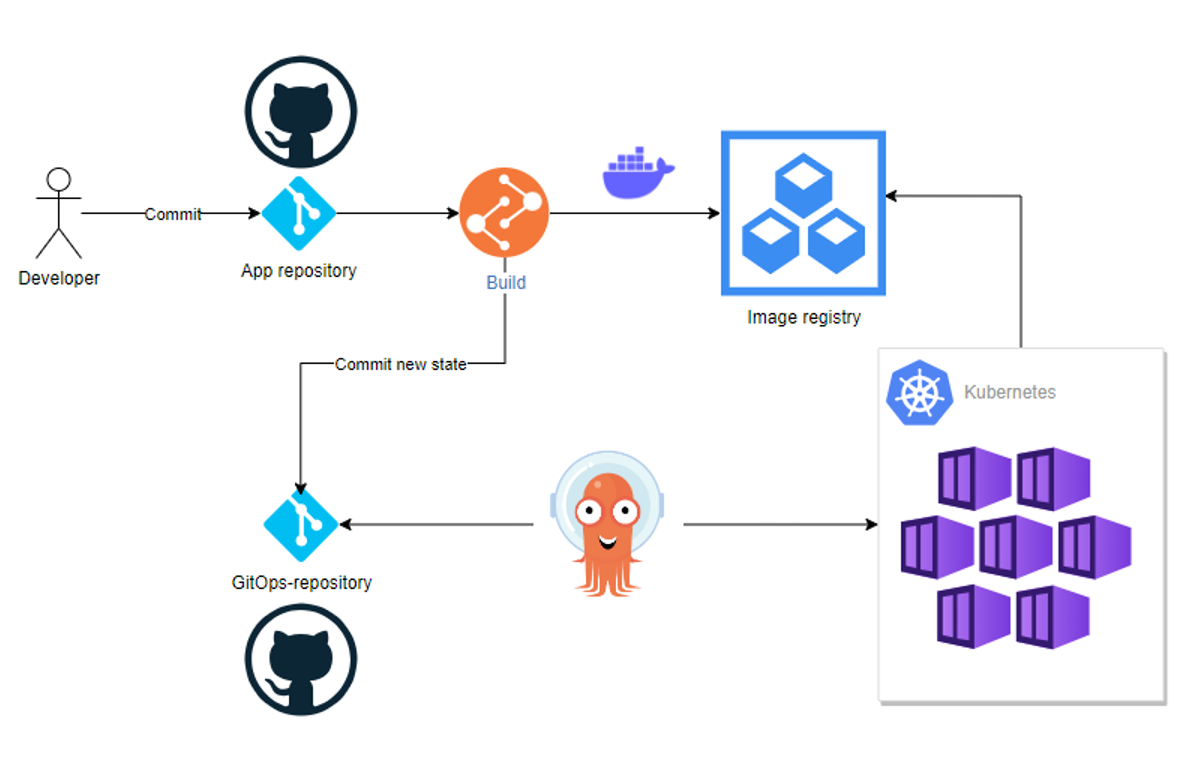
Figuur 1: GitOps


Quiz
Test je kennis na deze workshop van Alliander met deze korte multuple choice quiz.
Leerdoelen
Het doel van de workshop is dat je een goed beeld hebt van hoe Alliander bij hun praktijk DevOps in de praktijk invult. Dus welke standaard tools en best practices Alliander gebruikt.
- Je kunt uitleggen hoe Kubernetes en Helm worden gebruikt voor het beheren en deployen van applicaties binnen Alliander.
- Je kunt beschrijven wat GitOps inhoudt en uitleggen hoe het wordt gebruikt om infrastructuur te beheren met Git als single source of truth.
- Je kunt de werking van een GitOps Operator zoals ArgoCD uitleggen en begrijpen hoe deze wordt gebruikt voor continuous delivery.
- Je begrijpt hoe het CI/CD proces bij Alliander is ingericht met GitHub Actions en ArgoCD en kunt het belang hiervan toelichten.
- Je kunt uitleggen hoe AWS Elastic Container Registry (ECR) wordt gebruikt om container images op te slaan en beheren zoals voor software updates of container retentie.
Prometheus & Chaos engineering
NB Deze les vervalt in 2025. Chaos engineering komt in week 6 terug als onderzoeks thema in de spike/onderzoek sprint van het 3-weekse eindproject.
Prometheus of andere monitoring/observability onderzoek je ook verder in week 6 samen met security onderwerp en advanced Kubernetes onderwerp/techniek uit het CNCF landschap.
Vandaag 2 aparte onderwerpen: monitoring en statistieken via Prometheus en Grafana. En een 'build for failure' attitude via Chaos engineering in K8S met de tool Chaos mesh.
Huiswerk/voorbereiding Chaos Engineering
- Zorg dat je begrijpt wat Chaos Engineering is én hoe je dit bereikt (Chaos Monkey, bv. link met 'design for failure' uit Event Driven workshop)
- Lees over Chaos Mesh
- Als het goed is ken je al het concept 'shift left', neem deze blog door over het concept 'shift right'
- Optioneel: Doe de 3 stappen van de Quickstart van open source Load test tool K6
- Krijg zelf overzicht van de Prometheus architectuur (zie figuur 1) door de website van Prometheus zelf door te nemen: prometheus.io.
Chaos Mesh

Figuur 1: Chaos Mesh

Figuur 2: Shift left vs shift right
Huiswerkvragen
- Schrijf voor jezelf op wat 'shift left' betekent. Beantwoord in ieder geval:
- waarom term 'left'?
- wat shift je?
- betrek ook het plaatje van software development continuum (of DevOps infinity loop)
- Zelfde voor 'shift right': Wat betekent shift right?
- Betekent 'shift right' dat je test in productie?
- Wat heeft shift right' met SlackOps te maken?
- Kun je een load test ook op een test omgeving doen? Wat is er dan nodig?
Uitstapje: The founder

Figuur 3: 'Founder trailer'
Lesvraag: Wat heeft deze video met DevOps te maken? Link ook aan het concept 'shift right'.
Chaos Engineering in PitStop

Figuur 3: Video: Stukje Chaos engineering in PitStop; demo van Edwin van Wijk
-
Welke tools gebruikt Edwin van Wijk om Chaos Engineering principe toe te passen? (NH: het YouTube filmpje start bij stuk over 'Chaos Engineering' op 41 en een halve minuut.
-
Welk onderzoeksmethode hoort bij een load test? (if any)
- In welke onderzoeksruimte zit deze methode?
- Wat is het verschil tussen een load test en een performance test? (if any)
- Vindt een alternatieve tool voor K6, schrijf kort verschil in features tussen de twee (nadeel en voordeel t.o.v. elkaar)
Prometheus
Week opdracht 5 bevat het maken van custom metrics in je applicatie en het verzamelen (scrapen) hiervan met Prometheus.

Figuur 5: Prometheus architectuur (bron: prometheus.io)
In deze laatste onderwijsweek testen we meer je eigen attitude.
Attitude
- je bent nieuwsgierig, en vindt zelf geschikte bronnen (je hebt deze minor zelf gekozen, en gaat volgende week ook onderzoek doen)
- je werkt zelfstandig (je gaat na de minor afstuderen)
- kunt samenwerken ('DevOps is cooperation').
- je bent pragmatisch (je pakt een nuttige rol in de groepsopdracht, bepaalt een einddoel en houdt deze in de gaten)
Vanuit deze attitude zorg je dat een aantal dingen kent (kennis op doet) en kunt (vaardigheden aanleren en oefenen).
Kennen:
- de Prometheus architectuur
- Belangrijke termen: metrics, metrics server, promql, visualizer, service discovery, time series en scraping.
- Ook weet je hoe samenwerking Prometheus is met Grafana of andere broodnodige visualisatie tools als de ELK stack (omdat Prometheus NIET zelf visualisatie doet; zie figuur 2.)
De basis Prometheus architectuur staat geillustreerd en uitgelegd op de prometheus.io Overview sectie (z.d.). De uitgebreide architectuur beschrijf Radesh (2021) in deze blog website devopsschool.com.
Kunnen:
In de weekopdracht moet je
- enkele algemene metrics tonen
- maar ook applicatiespecifieke metrics.

Figuur 2: Prometheus uitgebreide architectuur (inclusief visualisatie tool als Grafana; bron: DevOpsSchool.com)
Bronnen
-
Prometheus.io (z.d.) Overview — What is Prometheus? ... Architecture Geraadpleegd oktober 2025 op https://prometheus.io/docs/introduction/overview/#architecture
-
Kumar, R. 22-1-2021) What is Prometheus and How it works? ... Geraadpleegd op 3-11-2023 op https://www.devopsschool.com/blog/what-is-prometheus-and-how-it-works/
-
Kumar, P. (22-5-2021) Chaos Engineering in Kubernetes using Chaos Mesh Geraadpleegd op https://medium.com/nerd-for-tech/chaos-engineering-in-kubernetes-using-chaos-mesh-431c1587ef0a
DevOps Beroepsproduct

Afsluiter van de course fase is een opdracht om in teamverband een DevOps BeroepsProduct (BP) te realiseren, te deployen en in de lucht te houden en monitoren.
Het is goed om je al een keer op deze eindopdracht en beoordelingscriteria te orienteren aan het begin van de course, zodat je hier gericht naar toe kunt werken. Tijdens de course fase refereert de docent waarschijnlijk ook regelmatig aan de eindopdracht, ivm het CDMM beoordelingsmodel. En in de laatste weekopdracht(en) neem je hierop ook al een voorschotje.

Figuur: Ontdek het DevOps 'Secret Ingredient' tijdens de course eindopdracht!
NB Tijdens de course eindopdracht leer je — eindelijk — de secret ingredient van DevOps kennen! (zie figuur; spoiler warning: filmpje NIET aanklikken!)
De DevOps minor is voltijd. Jullie worden geacht om 40 uur per week aan beroepsproduct te ontwikkelen. Dus op maandag bespreken we bovenstaand overzicht en eventuele uitwijkingen hierop. Communcatie verloopt ook via het aangemaakt Slack kanaal en/of Teams (Slack in 2024)/.
Lestijden DevOps-project
Vraag student
"Ik ben een beetje verward door het rooster van ISAS i.c.m het rooster op minordevops.nl. Wat zijn nu precies de lestijden voor het DevOps project volgende week? Ik wil ook netjes verlof boeken met m'n werk."
Reminder: KiesOpmaat geeft/gaf ook aan:
Rooster Er wordt vanuit gegaan dat studenten van maandag t/m vrijdag beschikbaar zijn, dus bijbaantjes of andere vakken van maandag t/m vrijdag (9.00-17.45 uur) volgen is geen optie.
Er is in de laatste drie weken geen centrale stof meer, en ook geen theorietoetsen. We gaan de geleerde theorie toepassen, en waar nodig nog aanvullen of gaten dichten. Je werkt zelfstandig met je team werken aan de eind opdracht. Hiermee oefenen we ook de vorm vam het eindproject in blok 2. Op de lesmomenten is de docent in het geroosterde lokaal, tenzij anders afgestemd. Begin van de week zijn sprint planning en eind van de week reviews. In week 2 kan begin van de week nog een retrospective met je docent zijn, of je doet dit als team zelfstandig (continuous improvement).
In week 9 is (naast theorie toets herkansing) mogelijk ook nog een bedrijfsbezoek en/of een workshop bij InfoSupport workshop. Details volgen in de lessen.
Week 6: Spike/Onderzoek Sprint
Zie de Spike Guide voor uitleg over de onderzoeksweek, de te onderzoeken thema's en de presentatie op donderdag. Je maakt ook alvast een User Story map van je functionaliteit en ook je spikes en non-functionals hierin.
Week 7: Implementatie & Development
In week 7 ga je de bevindingen uit je spike-onderzoek implementeren in je MSA DevOps applicatie. Je werkt aan:
- Basis functionaliteit van je product increment (selectie user storie)
- Toepassen van onderzochte technologieën in je applicatie
- Architectuur aanpassingen volgens je spike-bevindingen
- Documentatie via C4 diagrammen en ADR's en invullen individuele verantwoording
Aan het einde van week 7 moet je applicatie werkend zijn op een productie-omgeving.
Week 8: Product Increment & Presentatie
Week 8 staat in het teken van het afronden van je product increment en de voorbereiding van de eindpresentatie:
- Product increment realiseren met de 6 vereiste eisen (uitrol, architectuur, monitoring, security, schaling, fouttolerantie)
- Staging omgeving opzetten naast productie
- Testing en validatie van alle functionaliteit
- Voorbereiding eindpresentatie en demo
- Documentatie afronden (README, ADR's, C4 diagrammen, individuele verantwoording)
Op donderdag van week 8 presenteer je je beroepsproduct aan de klas en docenten.
Op maandag in week 9 presenteer je je product aan de product owner (sprint review 2 = overall demo). Verder is er ook een aparte sessie individuele verantwoording.
Aanpassing 2025
NB In 2025 krijg je geen GEEN externe K8s omgeving vanuit de HAN. In het project in blok 2 is er wel een externe omgeving (Azure DevOps/MCPS; waar je in week 9 een workshop over krijgt). Maar in deze Course opdracht mag je het houden bij runnen op localhost. Onderstaand optionele uitleg dat het wel mag, maar focus vooral op functionaliteit maken en andere techniek onderzoeken.
Hoe dan staging en productie?
Zorg wel dat je je product integreert met alle teamleden, dus dat je bij de review de demo kunt geven op elke willekeurige laptop van een teamlid. Met name voor demo'en van geimplementeerde 'techs' kan dit een uitdaging zijn.
Zorg voor de staging omgeving wel voor dat je dit kunt aangeven in je pipeline.
Run je staging en productie als twee namespaces in je (lokale) Kubernetes cluster.
📚 Handleiding: Zie Kubernetes Multi-Environment Setup voor een complete uitleg hoe je staging en productie namespaces opzet met eenvoudige localhost URL's.
Opdrachtbeschrijving beroepsproduct DevOps
Afsluiter van de course fase is een opdracht om een DevOps beroepsproduct te maken als team met — uiteraard — gelijkwaardige bijdrage van elk teamlid. Hieronder de opdracht voor het team en elk groepslid.
A. Team:
- Deploy een applicatie (systeem) die bestaat uit meerdere containers (microservices) naar minstens één live omgeving
- Pas de onderzochte DevOps technologieën uit Spike onderzoeken toe in de applicatie en/of deployment
- Voer hierop een product increment door met toepassing van de in thema weken opgedane kennis en vaardigheden
B. Elk groepslid:
- Voer een technisch Spike onderzoek uit naar een DevOps-technologie naar keuze
- Werk effectief samen in een team met goede onderlinge communicatie
- Vind een eigen rol en specialisatie
- Lever een bijdrage volgens een Agile aanpak
Alle punten die hierboven beschreven zijn, zijn knock-outcriteria.
Dit betekent een gedeelde verantwoordelijkheid en verantwoordelijkheidsgevoel. Dit beroepsproduct is zo een voorbereiding op de grote opdracht van tijdens de project fase van de minor. Daarom werk je aan een product met een moderne microservices architectuur (complexe architectuur, zie bv. Figuur 1).
Figuur 1: Voorbeeld van een microservice architectuur — waar komt jouw uitbreiding?
Al met al moet je best veel dingen voor elkaar krijgen in drie weken. Verdeel het werk over alle teamleden en zoek naar 'twee vliegen in een klap slaan'. Kijk wat je met het toepassen van je technologieen al hebt afgedekt. Hou tot slot de gemaakte functionaliteit en architecturele aanpassing klein zoals in toelichting hieronder ook vermeldt.
Enkele opmerkingen van student na afloop van dit BP project staan onderaan. Wellicht goed om door te nemen voor een meer 'studenten perspectief'. En ook om niet aan dezelfde steen/stenen te stoten...
De knockouts zorgen voor een bepaalde minimale hoeveelheid werk die je als team moet verzetten, oftewel kwantiteit. Wellicht kun je dit i.p.v. kwanteit overigens nog beter varieteit noemen. Want in plaats van je tijd alleen steken in bv. veel functionaliteit, kun je na 1e functionaliteit beter focussen ook security analyse te doen en pipeline in te richten. Deze variateit/kwantiteit is nodig om dus een 6 te halen. Op HBO niveau geldt echter NIET 'het werkt, dus het is goed genoeg'. Eerst maak je een werkende situatie, maar daarna review en refactor je verder tot het ook onderhoudbaar, uitbreidbaar etc is. Kortom, zorg voor kwaliteit.
Voor het bepalen van de kwaliteit van het product en gebruikte proces (en dus voor een cijfer hoger dan een 6) gebruik je de CDMM beoordelingscriteria zoals elders beschreven. Naast het afvinken leg je ook uit waarom je aan de punten voldoet. E.g. toon aan dat je bewust bewkaam bent als team.
A1. Applicatie live zetten (en houden)
Dit betekent dat je
- a. De applicatie werkend krijgt op een productie omgeving (week 1 van ontwikkeling).
- b. Maar ook een (externe) staging omgeving (cq. test, QA, etc.) (week 2 van ontwikkeling)
Omdat je maar één K8s cluster hebt kun je hiervoor een Kubernetes namespace gebruiken (Lewis 2015). Bonus is als je de staging omgeving tijdelijk maakt, door deze test omgeving weer snel te kunnen stoppen en afbreken. Zodat er bv. minder load balancer kosten zijn.
A2. Toepassen technologieën
- a. Je past de onderzochte DevOps technologieën in het product.
- b. Documenteert het gebruik in README, ADR's.
- c. En/of automatiseert in shell scripts zodat ook iemand die technologie niet kent met het product kan werken.
Als technologieen alternatieven zijn, doe je PoC's en past evt. beide toe, of je kiest o.b.v. bronnen en documenteert keuze met Architecture Decision Records. Evt. clashes, problemen met technologie had je waar mogelijk voorzien tijdens onderzoek, maar documenteer je anders kort met verwijzing naar evt. openstaande issue van gebruikte technologie en/of vind work-around.
Architectuur Documentatie
Je software architectuur documenteer je in dit project typisch via C4 diagrammen en ADR's. Maar vergeet bij de C4 diagrammen de begeleidende toelichting niet. En bij de ADR's ook een inleiding.
Kijk voor opties voor ADR's nog eens terug in de les over Continuous Documentation.
Er zijn geen uitgebreide verslagen nodig.
A3. Product Increment
In het product increment (figuur 2) besteed je als team — naast realisatie van nieuwe functionaliteit — ook aandacht aan het opstellen van non-functionele eisen en het hieraan voldoen via de aangeleerde DevOps aanpak. In het product increment realiseer je de volgende zes eisen:
-
a. Makkelijke uitrol van je product increment, via 'niet standaard'
Deployment- bijvoorbeeld Canary, Blue Green
Deploymentof gebruik van een externe tool als Helm of Ansible
- bijvoorbeeld Canary, Blue Green
- b. Aanpassing van architectuur van de applicatie, inclusief documentatie!
-
c. Monitoring van hardware gebruik
- om problemen te voorkomen en efficiency en kostenbesparing mogelijk te maken en evt. custom metric en rapportages
-
d. Security aspecten, bv scan op container en/of dependency niveau
- update van dependencies en uitrollen ervan zonder regressiefouten of voor gebruikers merkbare glitches of functionele veranderingen
- e. Automatische schaling, bv. bij meer of minder (gesimuleerde) gebruikers
-
f. Fouttolerantie, design for failure en/of High Availability
- uitvallende hardware of services erop heeft geen merkbare gevolgen (evt. Chaos engineering toepassen)
Figuur 2: Output van een Sprint is een Product increment (Bron: kiwop.com, 2020)
Toelichting/tips bij de opdracht
Het is zaak de functionele uitbreiding relatief simpel te houden. Het kan ook een prototype functionaliteit zijn, die nog verder uitgewerkt moet, mits de roadmap wel duidelijk is en evt. bugs op een 'known issues' lijst staan en workaround hebben. De uitbreiding moet dus wel enigszins realistisch zijn, en ook deels zichtbaar via UI of webservices. Ook heb je uiteraard tests geschreven voor het geautomatiseerd testen van je product increment.
De toepassing van de onderzochte technologie moet efficient zijn en pragmatisch. Ofwel: de technologie moet je helpen bij bovenstaande doelen en niet loshangen en alleen tijd gekost hebben. Denk aan het gebruik van een geautomatiseerd monitoring dashboard, toepassen van een service mesh met built in security features, of gebruik een ops tool/technieken als IaC.
Bewaar al te grote ambitie qua functionaliteit voor het project in blok 2. De kern van de opdracht is het tonen van een DevOps aanpak. Dus het is niet onoverkomelijk ook als in je functionaliteit mogelijk nog wat UI gebreken zitten, of integratiebugs. Hiermee kun je bv. ook demo'en dat dat je een rollback kunt doen...
Denk bij een architecturwijziging aan:
- één of meer nieuwe microservices toevoegen. Deze communiceren onderling of met bestaande microservices.
- Het opsplitsen van bestaande microservice in twee onderdelen met eigen verantwoordelijkheid.
- Het aanpassen van .NET microservice naar (API compatible) Java, NodeJS of microservice met een andere programmeertaal (Polyglot 'X').
- Onder Polyglot X hoort overigens naast een andere programmeertaal ook het gebruik van een andere stack, bv. Java TomEE vs Java Spring, of een aanpassing in een andere laag, bv. persistentie dus switchen van MSSQL naar MySql, PostgreSQL, een NoSQL oplossing zoals ElasticSearch of caching technologie rondom database en/of applicatie zoals Redis of RabbitMQ of Service Bus persistent of een in memory database.
- Het doorvoeren van meer Event Driven architectuur zoals aanpassen naar CQRS patroon.
- Het uitbreiden of uitsplitsen van front-end laag naar aparte microservice, een self hosted CDN aanpak of cookieless subdomain of zelfs micro frontend achtige aanpak.
- Of nog iets anders... :)
Er is bij deze opdracht GEEN externe opdrachtgever en tevens gebruik je hierbij een bestaande applicatie, zodat je zelf weinig functionaliteit/features hoeft te verzinnen. Start met een applicatie die al in containers kan draaien, zodat je deze niet van scratch hoeft op te bouwen.

In dit opzicht lijkt het op een zogenaamd brown field project, in de zin dat je NIET vanaf scratch begint, maar je moet verdiepen in een bestaande software architectuur en een deel van de details van de code en configuratie. Het gekozen project is echter wel een green field qua gebruikte technologieën en aanpak. Dus het bevat unit tests en heeft in principe een microservices architectuur. Aangeraden project is InfoSupport's Pitstop. Een alternatief is Microsoft's 'e-shop on containers' project.
Je uitbreiding moet wel uniek zijn binnen je klas. De technologieen die je hierin toepast zijn ook uniek, maar dat is bij onderzoeksopdracht als het goed is al geregeld.
Voorbeelden van functionele uitbreidingen
Kijk bij de les/workshop User Story mapping voor enkele casussen (casi?) voor een functionele uitbreiding van PitStop (met elk ook weer subonderdelen). Met een plaatje erbij van Dall-e voor een sfeer impressie. Geef wel je eigen draai aan een functionaliteit. Of verzin zelf een functionaliteit (en je eigen plaatje met Dall-e).
Studentenfeedback na afloop van de BP opdracht
Hier wat feedback/reflectie van studenten na afloop van het project, om een beeld te krijgen vanuit hun perspectief.
"De opdracht was aardig abstract en vaag in het begin. Na het stellen van vragen aan de docent was er meer duidelijkheid en tijdens de werkdagen kwamen we er zelf ook meer achter wat we moesten doen. Er was weinig tijd om alles goed te doen en hierdoor hebben we concessies moeten maken op bepaalde vlakken. Verder is werken aan een (redelijke) grote applicatie die jezelf niet hebt geschreven lastig en tijdrovend maar wel leerzaam voor later in het bedrijfsleven." - Student X
"Ik ben zeer tevreden met de voortgang van dit project. In het begin was het nog een beetje puzzelen wat precies de verwachtingen & eisen waren. Zodra dit bekend was bij ons waren wij al snel uit over wat we willen doen met dit project. Namelijk het toevoegen van mechanics. Al snel had ieder zijn specialiteit gevonden, in mijn geval was dat de front-end. ..." - Student Y
"In het begin was de opdracht heel onduidelijk. Ik begreep toen ook niet wat er nou precies moest gebeuren. Wat later kwam ik erachter dat wij gewoon heel vrij waren, zolang wij maar bepaalde doelen haalden. Op zich was dit wel een keer een fijne manier van werken, maar vind het persoonlijk prettiger werken wanneer er meer duidelijkheid is. Ook was de Pitstop applicatie aardig groot voor deze twee weken. Wij zijn in het begin heel veel tijd verloren aan het uitzoeken hoe Pitstop in elkaar zit." - Student Z
4. Werkwijze beoordeling individuele bijdrage
Voor je individuele bijdrage in het project krijg je ook een beoordeling.
⚠️ BELANGRIJK: Het Markdown template voor individuele bijdrage moet je NU al gebruiken tijdens de course fase (beroepsproduct), niet alleen tijdens het eindproject in blok 2!
Zie het Markdown template individuele bijdrage voor het complete template.
Bronnen
- Lewis, I. (28 Augustus 2015) Using Kubernetes Namespaces to Manage Environments, geraadpleegd 21-10-2021 op https://kubernetes.io/blog/2015/08/using-kubernetes-namespaces-to-manage/
- Long, D. Hongxin (31 juli 2023) Creating Quality Online Content in the Era of AI Geraadpleegd 5-10-2023 op https://www.deanlong.io/blog/creating-helpful-reliable-people-first-ai-content
- Kiwop (12 April 2020). Agile methodologies in web development kiwop.com. Geraadpleegd 19-12-2024 op https://www.kiwop.com/en/blog/agile-methodologies-in-web-development
Spike Guide: Onderzoek Sprint Week 6
In de eerste week van het 3-weeks eindproject (week 6) doen alle teams een spike/onderzoek sprint waarin ze één van de volgende 4 thema's onderzoeken. Deze handleiding legt uit wat je onderzoekt en hoe je dat systematisch aanpakt.
Onderzoeksthema's (per groep van 4-5 studenten)
-
Chaos Engineering & Resilience Testing
- Onderzoek chaos engineering principes en tools
- Test resilience van je MSA applicatie
- Implementeer chaos testing in je pipeline
-
Monitoring & Observability
- Onderzoek monitoring tools en best practices
- Implementeer logging, metrics en tracing
- Zet monitoring op voor je MSA applicatie
-
Security in DevOps (DevSecOps)
- Onderzoek security scanning en best practices
- Implementeer security checks in je pipeline
- Zorg voor secure deployment van je applicatie
-
Kubernetes & Container Orchestration
- Onderzoek advanced Kubernetes features
- Implementeer proper container orchestration
- Optimaliseer je deployment strategie
Elk team presenteert hun bevindingen aan het einde van week 6 en integreert de geleerde kennis in hun MSA DevOps applicatie voor de resterende 2 weken.
Donderdag week 6
Op donderdag vindt de presentatie en review van de spikes plaats. Hier wordt ook de aanwezigheid en actieve deelname van studenten afgevinkt.
Handleiding voor het Uitvoeren van een Technische Spike
Een technische spike is een korte, gerichte inspanning om een nieuwe technologie of aanpak te verkennen en te valideren. Voor je DevOps-project gebruik je een spike om een nieuwe DevOps-technologie te onderzoeken en een prototype te maken, terwijl je je bevindingen direct documenteert in de gerelateerde taak op het projectbord.
1. Definieer het Doel
Begin met een duidelijk doel dat het doel van de spike definieert.
-
Belangrijke vragen om te Beantwoorden:
- Welk probleem los je op?
- Wat moet je weten over de technologie?
-
Voorbeeld Doel: "Onderzoek en maak een prototype van Kubernetes voor containerorkestratie. Specifiek:
- Zet een Kubernetes-cluster op met behulp van Minikube. Zorg ervoor dat het cluster operationeel is en meerdere pods kan beheren.
- Implementeer een voorbeeldapplicatie, zoals een Nginx-webserver, die reageert op HTTP-verzoeken. Configureer load balancing en schaal de applicatie horizontaal naar minimaal 3 pods.
- Integreer monitoring met behulp van Prometheus voor metrics en Grafana voor het visualiseren van CPU-gebruik, geheugengebruik en netwerkverkeer."
2. Plan de spike
Stel grenzen en een tijdsbestek vast voor de spike. Houd het kort en gefocust (4-6 of 8 uur).
-
Resultaten:
- Een werkend prototype dat de technologie demonstreert.
- Gedocumenteerde bevindingen en aanbevelingen in de gerelateerde taak op het projectbord.
-
Scope:
Definieer wat binnen de scope en buiten de scope van het prototype valt.
3. Voer Onderzoek uit en maak een Prototype
Onderzoek de technologie en maak een eenvoudig prototype om het gebruik ervan te demonstreren.
a. Verzamel Informatie
- Bekijk officiële documentatie, blogs en tutorials.
b. Bouw een Prototype
- Zet een kleine, geïsoleerde omgeving op.
- Ontwikkel een minimale werkende oplossing om belangrijke functies te testen.
- Voorbeeld: "Implementeer een eenvoudige applicatie met Kubernetes en test schaalbaarheid."
c. Documenteer Bevindingen
- Noteer observaties, uitdagingen en resultaten direct in de taak op het projectbord.
4. Analyseer en vat samen
Consolideer je bevindingen na het maken van het prototype.
-
Vat Belangrijke Punten Samen:
- Voordelen en nadelen van de technologie.
- Geschiktheid voor je project.
-
Geef Aanbevelingen:
- Moet het team de technologie adopteren? Waarom wel of niet?
- Geef indien nodig de volgende stappen aan.
5. Presenteer je Bevindingen
Zorg ervoor dat je bevindingen en prototype duidelijk zijn gedocumenteerd in de gerelateerde taak op het projectbord.
-
Voeg toe:
- Doel van de spike.
- Belangrijkste bevindingen en inzichten.
- Screenshots of codefragmenten van je prototype.
- Eindaanbeveling.
Concreet te documenteren en op te leveren
Geen blog en geen verhalend verslag nodig; je vertelt het verhaal mondeling tijdens de presentatie. Documenteer beknopt en toetsbaar.
- Issue op het team‑projectbord (GitHub Projects of vergelijkbaar)
- Titel: "Spike:
voor <PitStop‑uitbreiding>" - Koppel commits/PRs aan dit issue
- Titel: "Spike:
- Repo‑structuur in jullie PitStop teamrepo
- Map:
/docs/tech-onderzoek-<studentnaam> - Minimale prototype‑artefacten: code en/of configuratie (hello world is oké)
README.mdin deze map met minimaal de volgende kopjes:## Welk probleem los ik op?## Wat moet je weten over de technologie?## Observaties## Uitdagingen## Resultaten## Bronnen(bullets met titel en volledige URL; waar relevant auteur/organisatie)
- Map:
- Werkwijze
- Trunk‑based: commit rechtstreeks op
mainmag voor deze spike - Gebruik de hoofdvraag en drie deelvragen als leidraad; beantwoord ze kort in de README
- Trunk‑based: commit rechtstreeks op
- Acceptatie tijdens presentatie
- Korte demo van het prototype
- Heldere, onderbouwde antwoorden op de deelvragen
- Overzichtelijke bronnenlijst
Voorbeeld screenshots aanpak in GitHub (stappen)
Om het idee van een 'onderzoeksteam' ook handen en voeten te geven, en voor te bereiden op de 2 weken implementatie in de weken na deze onderzoeksweek is het handig nu per persoon een folder /docs/tech-onderzoek-studentnaam op te nemen voor je prototype. Daarin komt je code en/of configuratie.
Aangezien 'documentation as code' een DevOps best practice is (mits publiek developers) kun je markdown gebruiken. Aangezien je bij een Spike onderzoek je onderzoek als issue op de backlog/planbord zet, en je bij DevOps een shared backlog moet hebben, en in GitHub je issues en een projectboard bij je repo kan aanmaken kun je onderstaande stappen zetten. In GitHub issues kun je ook markdown gebruiken.
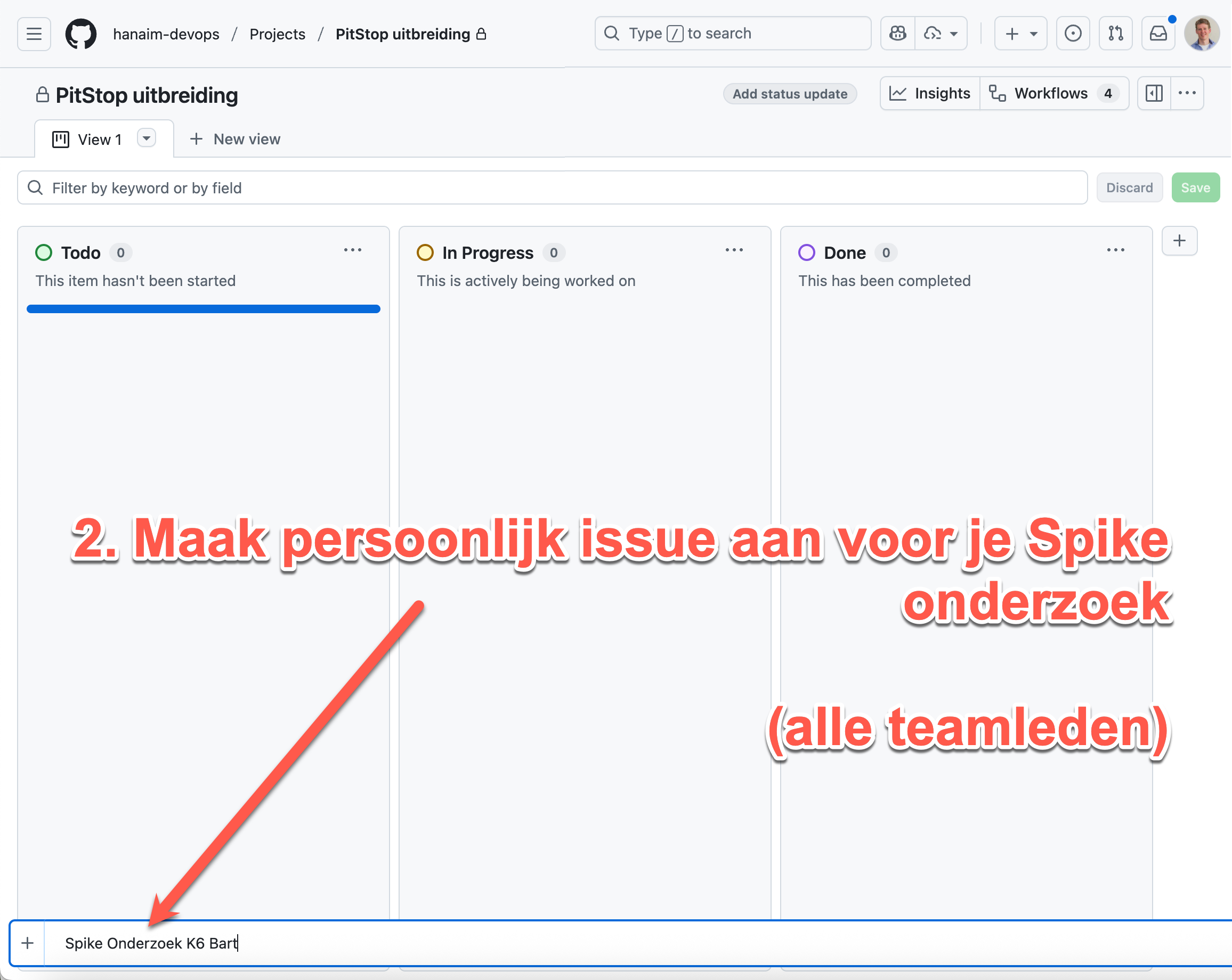
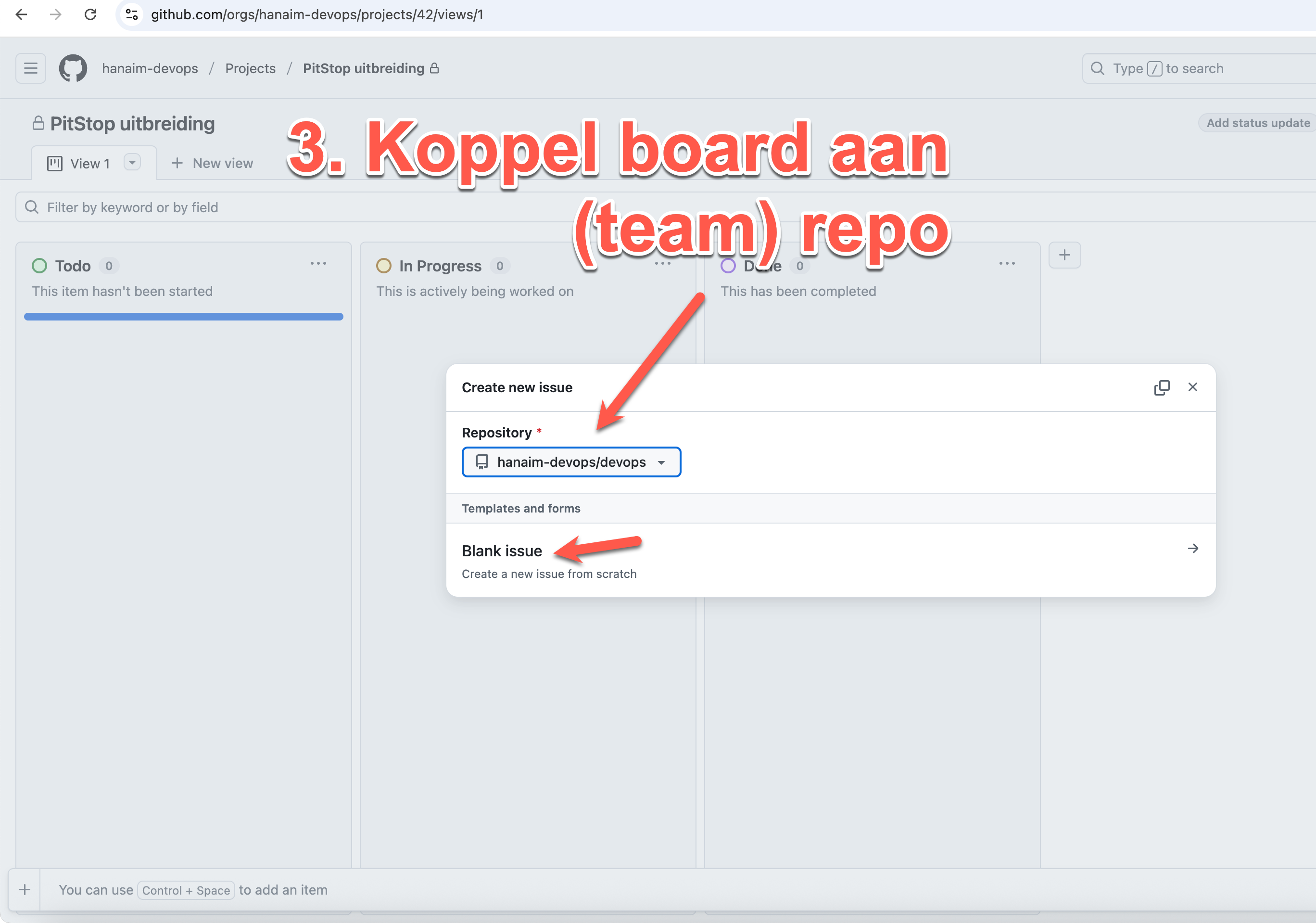
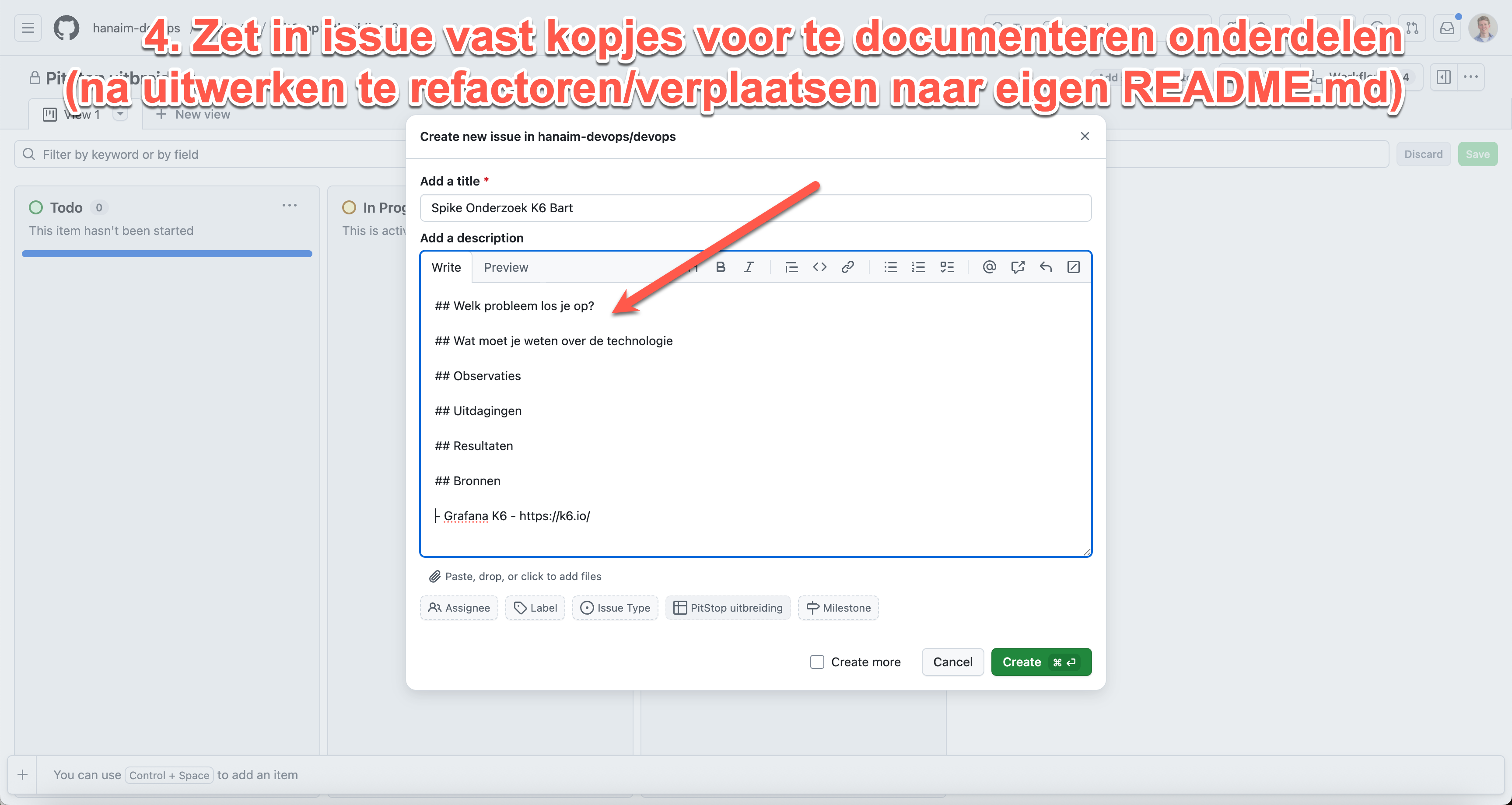
Voor de laatste stap, het refactoren verplaats je de tekst vanuit issue naar de README.md in je eigen folder. Commit ook je wijzigingen op het persoonlijke issue nr (e.g. zet het #nr in je commit messages).
Herhaalbaarheid en bronvermelding
Voor de herhaalbaarheid en controleerbaarheid van je onderzoek is het verplicht om je geraadpleegde bronnen (officiële documentatie, blogs en tutorials, etc.) te bewaren en op te nemen in je documentatie. Bijvoorbeeld direct in de taak op het projectbord, of in de README.md van je prototype. Noteer per bron minimaal:
- Titel van het stuk (artikel/blog/video/documentatie)
- Volledige URL
Waar relevant kun je ook auteur, datum en versie vermelden. Gebruik consistente notatie.
Toepassen van (HBO) ICT onderzoeksmethoden
Je kunt bovenstaande opdracht volgen. Merk echter op dat je hierbij 'gewoon' werkt volgens de HBO ICT onderzoeksmethoden. Je werkt ook vanuit een onderzoeksvraag. De hoofdvraag voor iedereen in deze week is:
Hoe kan ik mijn gekozen technologie nuttig toepassen in mijn groepsgekozen PitStop‑uitbreiding?
Deze vraag kun (moet) je concreet maken, door zowel de concrete technologie in de vraag te zetten als je PitStop uitbreiding te noemen. Bijvoorbeeld:
"Hoe kan ik de load testing tool K6 nuttig toepassen in onze uitbreiding van PitStop met Voorraadbeheer"
De Spike Guide heeft feitelijk al enkele van de HBO ICT onderzoeksmethoden voor je gekozen. Koppel je aanpak aan passende onderzoeksmethoden (triangulatie) en splits de hoofdvraag op in drie deelvragen:
-
Literatuuronderzoek: officiële documentatie, artikelen, tutorials
- Deelvraag: Welke best practices, beperkingen en randvoorwaarden gelden voor mijn gekozen technologie in de context van onze PitStop‑uitbreiding?
- Ingrediënten (bron: Literature study):
- A willingness to read.
- Search engines (e.g. Google Scholar, your library’s search engines).
- The ability to select what is really important for your case and to leave the rest unread.
- Identifying the ‘gatekeepers’ (parties who guarantee the quality of certain information).
- Knowing when to stop.
-
Prototyping: klein, doelgericht proof‑of‑concept
- Deelvraag: Werkt de technologie in een minimaal, representatief prototype voor onze beoogde use‑case, en wat zijn de technische beperkingen?
- Ingrediënten (bron: Prototyping):
- A willingness to tackle the riskiest and difficult parts first.
- The ability to ‘kill your darlings’ if the feedback or findings are negative.
- A clear view of what you would like to learn from your prototype.
-
Presentatie/Showroom (Pitch): toets je bevindingen bij stakeholders (team/docent)
- Deelvraag: Kunnen we de waarde en toepasbaarheid van de technologie overtuigend overbrengen en ophalen of de richting klopt?
- Ingrediënten (bron: Pitch):
- Enthusiasm.
- The ability to present your idea briefly and convincingly.
- Representative experts.
- A willingness to improve and change.
Gebruik de ingrediënten uit ictresearchmethods.nl om je opzet te verbeteren (kwaliteitscriteria, meetbaarheid, validiteit). Zie een spike niet als aparte methode, maar als onderzoek ingebed in Agile softwareontwikkeling: timeboxed, gekoppeld aan een backlog‑issue en eindigend met gedeelde bevindingen en aanbevelingen.
Toelichting aan de hand van gestelde studentenvragen n.a.v. de opdracht
"Het is dus de bedoeling dat een [...] tool uitkies die ik ook behandel in de presentatie van donderdag? Of is het de bedoeling dat ik alleen een prototype uitwerk die de hoofdvraag beantwoord?"
Antwoord: Beide. Je onderzoekt een CNCF‑technologie én doet iets hands‑on (maakt een prototype). Een prototype bouwen impliceert dat je een tool/stack kiest. Het is niet verplicht om deze week al alles in PitStop te integreren (dat volgt in de laatste twee weken en telt mee in de eindbeoordeling). Een ‘hello world’‑achtig prototype is nu voldoende voor het hands‑on deel, mits je dit koppelt aan je onderzoeksvraag.
"Ik ben een beetje in de war over wat er precies opgeleverd moet worden voor het onderzoek. Het lesmateriaal noemt dat je je bevindingen en resultaten moet noteren, wat de indruk wekt dat het vooral gaat om het lezen van documentatie, het maken van een prototype en daar een korte toelichting bij geven. Maar nu hoor ik dat er ook een onderzoeksmethode bij hoort, waardoor het meer lijkt op een klassiek HAN‑onderzoek, zoals we die gewend zijn."
Antwoord: Het doel is toegepast onderzoek ‘net wat beter’ te doen. Zie softwareontwikkeling als continu toegepast onderzoek: je verkent techniek en domein, werkt eisen uit in code en tests, en onderbouwt keuzes. Deze Spike Guide geeft al een lichte methodische ruggengraat: literatuuronderzoek → prototyping → presenteren. Voeg waar passend principes uit onderzoeksmethoden toe (zoals triangulatie en expliciete kwaliteitscriteria). Een spike is dus geen nieuwe methode, maar een Agile vorm die onderzoek timeboxt en verbindt aan waarde voor het team.
Workshop User Story Mapping
Deze workshop leer je eindopdracht kennen, maar leert ook de User Story Mapping (USM) techniek kennen. Je past deze toe voor de opdracht komende twee weken. Deze techniek gebruik je ook in het eindproject om (meer) structuur aan te brengen

Figuur 1: De oorspronkelijke analogie van van Jeff Patton de grondlegger van USM (Patton, 2008)
Voorbereiding/Workshop
- Lees het verhaal over User Story Mapping en kijk de video van 6 minuten van Atalassian op de website van de Open Practice Library (Takane, 2017).
- Kies een van de PitStop casussen mogelijke 'Functionele uitbreidingen van PitStop' op, of verzin of genereer er zelf
- Verzin voor deze casus zes (6) user stories in de standaard vorm
Als <gebruikersrol> wil ik <functionaliteit> zodat ik <businesswaarde>. Hierbij:
- a. Minstens drie verschillende gebruikers(rollen) of persona's.
- b. Zoek op wat een persona is in Agile (bijvoorbeeld op Wikipedia of interaction-design.org). Voor empathisch design en UX, zie ook IxDF (2016).
- c. Zorg dat je user stories uniek zijn, anders dan die van je klasgenoten.
- d. Post je 6 user stories in Slack (eindopdracht-kanaal).
- e. Na het posten van unieke user stories kun je een casus claimen voor je groep. Overleg met je team; bij discussie beslist de docent.
NB: Het is geen gegeven dat je zelf ingediende/bedachte user stories ook mag implementeren, dit gaat in overleg met team, en hier houdt de docent veto recht.
Lesinhoud
- Maak een aantekeningen/tekening (concept map)
- The 8 Fallacies of USM
- Intro User Story Map
- Lesopdracht: Maak met je team een user Story map van je eigen casus/user stories
Een 'Concept map' van 'User Story Map'
Opdracht studenten: Maak n.a.v. lesinhoud vandaag een concept map van User Story Mapping
Relevante termen voor deze concept map zijn o.a.:
- Value slices, prioritering
- User story map, backbone
- User stories, acceptatiecriteria en backlog/code management tool
Einde les maakt de docent een foto hiervan.
User Story Map
Figuur 2: User Story map, leeg template van miro.com
Doel van de les is een goed beeld te hebben wat een User Story Map is en waar dit voor dient, en hoe je er een kunt maken voor een concrete business case (of functionele uitbreiding). Je kunt het best een whiteboard gebruiken voor vrijheid en eenvoud, zodat iedereen in team input kan leveren. Bij een brainstorm vertragen tools alleen maar. Voor overnemen als je opzet hebt, kun je bv. Miro template gebruiken. Moderne aanpak is 'diagrams as code'. Check de TextUSM tool en repo: textusm.com · GitHub repo. Deze heeft ook VS Code plugin met live preview. Het is even puzzelen hoe je ook meer releases/sprints maakt (alles werkt met tab).
Toon Miro instructie (screenshot, groot)
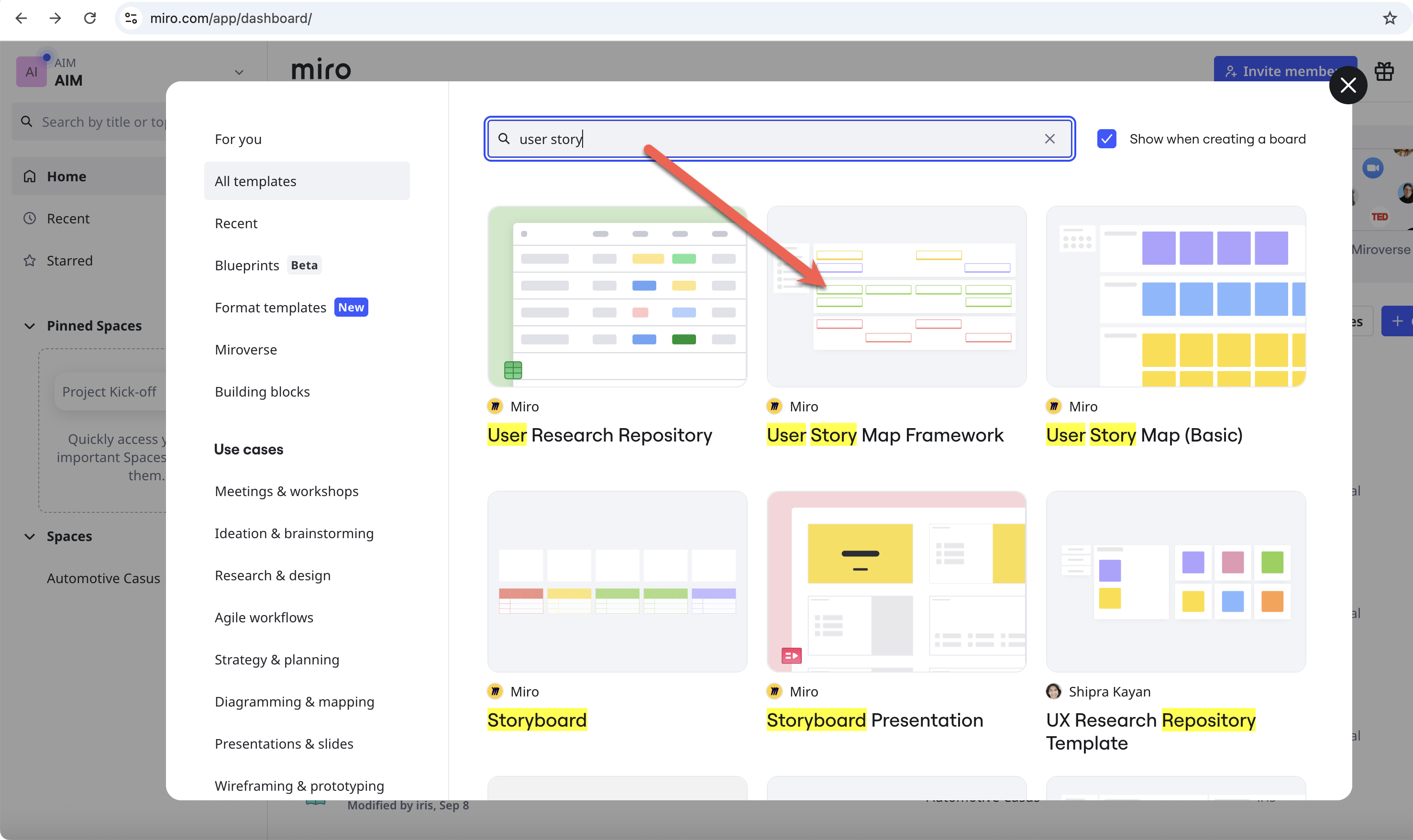
Voorbeeld uitgewerkte USM (Voorraadbeheer)
Zie de uitgewerkte user stories en USM voor de casus "Voorraadbeheer":
De richtlijnen op Open Practice Library geven aan minstens 3 sprints te maken. Ook de term 'MVP' in het template is belangrijk. Dit is een soort abstract 'sprintdoel'. Maar in true 'DDD practice' moet je hier in je eigen template een concrete invulling voor maken in de 'Ubiquitous language' die je deelt/gaat delen met business experts. In plaats van hen uit te leggen wat een 'MVP' is. Want dat moeten zij uiteindelijk zelf beoordelen: wat is 'viable' in hun business? Wat levert waarde op? Wel kun je eens nadenken over varianten op MVP als 'Minimally Marketable Product' (MMP) en 'Minimal Loveable Product' (MLP).
Lesvraag: Is er een vaste volgorde in het maken van MVP, MMP en MLP? Minimally Viable Product, Marketable Product en Lovable Product!?
Intro over 'Fallacies' in algemeen
Ter overpeinzing/bespreking:
“The trouble with the world is not that we know so little. It’s that we know so much, that just ain’t so.” - Mark Twain (or is it.. ;)
Eerder leerde je de 8 fallacies of distributed computing.
En algemeen: waarom is het nuttig te denken in termen van 'fallacies'?
The 8 Fallacies of User stories
Hier zijn 3 fallacies. Verzin met de klas er nog 5. Bekijk de lijst die de docent toont.
USM als 'functional spike' (onderzoek)
In deze week maak je ook een USM voor je casus. Zie USM als onderdeel van een 'functional spike': een kort, afgebakend onderzoek om interacties en scope van een feature te verkennen. Vergelijk dit met een 'technical spike' die je ook uitvoert om technische risico's te onderzoeken. Zie ook Spike (software development).
Technology push vs demand pull
Bij het kiezen van je te onderzoeken technologie (technical spike) en het aanscherpen van je casus (functional spike) helpt het onderscheid tussen 'technology push' en 'demand pull'. Let op dat technologie zoals AI niet altijd de beste startpunt is voor een project (Panagis, 2024).
"Compared to demand pull, technology push companies are in the reverse situation. They have developed a solution, but need to figure out what problem it solves. In this case, their potential customers are not already looking for a solution. Therefore, technology push companies need to figure out, which population in the market will benefit from their product and then convince them that the product is better than the status quo." — Kristi Bradford (2024)
Anti‑patterns in user stories (en hoe te voorkomen)
- Lege ‘zodat’: herhaalt het middel/doel (“…zodat ik ingelogd ben”).
- Beter: benoem meetbare waarde en wie profiteert.
- Voorbeeld: Slecht “Als gebruiker wil ik kunnen inloggen, zodat ik ingelogd ben.” → Beter “Als klant wil ik kunnen inloggen, zodat ik mijn geplande reparaties en facturen kan zien.”
- NB: ‘Inloggen’ is vaak geen gebruikersdoel maar een beveiligingsmaatregel. Een betere story benoemt de stakeholder en waarde van security:
- “Als security‑officer wil ik dat gebruikers zich authenticeren, zodat kwaadwillenden geen toegang hebben en gebruikers alleen bij eigen gegevens kunnen.”
- Implementatie‑verhaal: beschrijft oplossing i.p.v. behoefte (“JWT zetten”).
- Beter: outcome/waarde; oplossing laat je vrij voor het team.
- Zombie user story: blijft liggen, geen eigenaar/waarde, te groot.
- Aanpak: slice volgens INVEST, duidelijke acceptatiecriteria, eigenaar + deadline; anders archiveren.
- Vage waarde: ‘zodat het beter werkt’.
- Aanpak: expliciteer KPI/DoD (bijv. doorlooptijd −20%, foutpercentage <1%).
Heuristiek: vervang 'zodat …' door "omdat dat … waarde oplevert voor …". Kun je geen stakeholder/waarde noemen? Story herformuleren of schrappen. Denk ook na over wie de echte klant is: als een product gratis lijkt, ben jij waarschijnlijk het product (Shaikh, 2018).
Invest principes
Een beetje het tegenovergestelde van deze zelf bedacht 8 fallacies is het INVEST principe van Bill Wake (Wikipedia, 2024). Deze geldt voor PBI's, maar User stories is daar een vorm van. Deze moet je hanteren in het project bij het maken van sprint planningen, of bij het nadenken van value slices in je User Story Map. Hieronder de korte definitie van Wikipedia, maar het artikel van Philip Rogers op logrocket.com is wat toegankelijker met plaatjes en meer toelichting (2018).
"..the characteristics of a good quality Product Backlog Item (commonly written in user story format, but not required to be) or PBI for short. Such PBIs may be used in a Scrum backlog, Kanban board or XP project."
Letter Meaning Description I Independent The PBI should be self-contained. N Negotiable PBIs are not explicit contracts and should leave space for discussion. V Valuable A PBI must deliver value to the stakeholders. E Estimable You must always be able to estimate the size of a PBI. S Small PBIs should not be so big as to become impossible to plan/task/prioritize within a level of accuracy. T Testable The PBI or its related description must provide the necessary information to make test development possible.
Agile: GEEN WaterScrumFall
Agile wordt wel eens foutief aangegrepen als excuus om 'gewoon aan de slag te gaan' zonder verder te plannen of na te denken. Het is belangrijk om aan de slag te gaan en niet verstrikt te raken in 'analysis paralysis'. Maar met een beetje nadenken vantevoren kun je vaak veel verspilde tijd later voorkomen. En nadenken over een Road map voor je product samen met opdrachtgever en andere stakeholders. Dit kan in de vorm van een User Story Map. Hiermee zet je ook wat 'sprint goals' uit voor de 1e paar Sprints. Dit Requirements Engineering' stukje kun je ook iteratief aanpakken, in plaats van waterfall. Zodat je niet in de val trapt van 'WaterScrumFall' zoals Jez Humble het noemt:
"After witnessing a handful of Agile transformations, oftentimes the system of Waterfall isn’t entirely replaced by Agile, merely paved over. The DevOps group might have embraced it, but the rest of the business is still operating in a “Non-Agile”, project-that-starts-and-ends, style." - Steven Prutzman (2023)

Figuur 3: Simon Brown predikt 'Just enough upfront design' (YouTube/Brown, 2022)
Naast Humble's WaterScrumfall concept benadrukt ook C4 creator Simon Brown's praatje 'The lost Art of Software Architecture' hoe enige INVESTering zich kan uitbetalen in tijdsbesparing later. Dit is zeker een kijktip! Je software architectuur uitdenken met het C4 model is hier een vorm van. Maar aan de domein-/functionele kant is User Story Mapping hier een goede vorm voor.'
Quiz
Test je kennis met deze korte multiple choice quiz.
Leerdoelen
Check met onderstaande leerdoelen of je de stof beheerst en User Story mapping en gerelateerde kennis in de vingers hebt.
- Je kunt uitleggen wat User Story Mapping (USM) is en waarom het belangrijk is voor projectplanning.
- Je kunt beschrijven hoe USM helpt bij het prioriteren van user stories in DevOps projecten.
- Je kunt het INVEST-principe uitleggen en toepassen op het maken van sterke user stories.
- Je begrijpt wat fallacies zijn (algemene misvattingen) en kunt misvattingen in user stories herkennen als ze worden gegeven.
- Je kunt het verschil uitleggen tussen user stories en andere Product Backlog Items (PBI’s), zoals taken, bugs en epics.
- Je kunt een backbone en value slices beschrijven in een User Story Map.
Bronnen
- Bradford, K. J. (21 feb 2024) 6 differences between technology push and demand pull Pragmatic Frontiers. Geraadpleegd op 11-10-2024 via https://pragmaticfrontiers.substack.com/p/6-differences-between-technology
- Brown, S. (13 okt 2022) The lost art of software design by Simon Brown. YouTube. Geraadpleegd 14-102-2024 op https://www.youtube.com/watch?v=36OTe7LNd6M
- Interaction Design Foundation - IxDF. (2016, February 28). Empathic Design: Is Empathy the UX Holy Grail?. IxDF. Geraadpleegd 14-10-2024 op https://www.interaction-design.org/literature/article/empathic-design-is-empathy-the-ux-holy-grail
- Panagis, A. (Aug 8, 2024) Is AI A Good Starting Point? Generative AI – The Easy Way Out scalemath.com. Geraadpleegd op 11-10-2024 via https://scalemath.com/blog/generative-ai/
- Patton, J. (8 okt 2008) The New User Story Backlog is a Map jpattonassociates.com. Geraadpleegd 11-10-2024 op https://jpattonassociates.com/the-new-backlog/
- Prutzman, S. (Nov 10, 2023) Is your business stuck in a Water-Scrum-FALL model? medium.com.Geraadpleegd 13-20-2024 op https://medium.com/@sprutzman/is-your-business-stuck-in-the-water-scrum-fall-model-28e3c99eca6c
- Rogers, P. (Sep 10, 2024) Writing meaningful user stories with the INVEST principle Logrocket.com. Geraadpleegd 11-20-2024 op https://blog.logrocket.com/product-management/writing-meaningful-user-stories-invest-principle/
- Shaikh, F. (Nov 23, 2018) If you're not paying for the product, you are the product! LinkedIn. Geraadpleegd op 11-10-2024 via https://www.linkedin.com/pulse/youre-paying-product-you-faiz-shaikh/
- Takane M., De Beasi, R. (April 20, 2017) User Story Mapping & Value Slicing - Create lightweight release plans by slicing value out of collections of features Open Practice Library. Geraadpleegd op 11-10-2024 via https://openpracticelibrary.com/practice/user-story-mapping
- Wikipedia auteurs (17 sept 2024) INVEST (mnemonic) Wikipedia Geraadpleegd op 11-10-2024 via https://en.wikipedia.org/w/index.php?title=INVEST_(mnemonic)&oldid=1246204419
User stories – Voorraadbeheer (USM)
Deze pagina bevat de user stories en de User Story Map (USM) voor de uitbreiding "Voorraadbeheer".
Visualisatie (SVG)

Alternatieve visualisatie: volledige user stories
Open SVG (volledige user stories) in nieuw tabblad

Let op: Op de kaartjes hoeft de user story niet volledig uitgeschreven te staan. Gebruik korte, scanbare titels op de USM-kaartjes en leg de volledige user stories (incl. ‘zodat…’) vast in de backlog bij de PBI’s.
USM bronbestand (TextUSM)
Toon/verberg USM bron (vergeten-voorraad.usm)
# Tryout interactive on https://app.textusm.com/
# user_activities: Backbone
# user_tasks: Activities
# user_stories: Releases
# release1: SPRINT 1
# release2: SPRINT 2
# release3: SPRINT 3
Voorraad beheren
Onderdeelbeheer (SPRINT 1)
Onderdeel aanmaken
Voorraad raadplegen
Voorraad mutaties (SPRINT 2)
Voorraad aanpassen
Onderdelen reserveren (SPRINT 2)
Werkorderkoppeling
Reparatie plannen met onderdelen
Onderdelen reserveren
Lage voorraad signaleren (SPRINT 3)
Alerts
Notificatie lage voorraad
Bestelling via API (SPRINT 3)
Bestelproces
Dummy PartzNow API
Bestelsuggestie genereren
Bestelling verzenden
Inzicht per werkorder (SPRINT 1)
Werkorderinzicht
(anchor)
Werkorder met onderdelen
Voorraad visualiseren (SPRINT 2)
Overzicht & Kaart
(anchor)
Dashboard voorraadstatus
Kaart leverstatus (SwiftLogix)
Toon/verberg USM bron (vergeten-voorraad-usm-2.usm – volledige user stories)
# Zie ook CLI-opdracht onderaan deze pagina
# Tryout interactive on https://app.textusm.com/
# user_activities: Backbone
# user_tasks: Activities
# user_stories: Releases
# release1: SPRINT 1
# release2: SPRINT 2
# release3: SPRINT 3
Voorraad beheren
Onderdeelbeheer (SPRINT 1)
Als magazijnmedewerker wil ik een onderdeel kunnen aanmaken zodat het bestelbaar en traceerbaar is
Als monteur wil ik actuele voorraadinformatie kunnen raadplegen zodat ik kan plannen zonder mis te grijpen
Voorraad mutaties (SPRINT 2)
Als magazijnmedewerker wil ik voorraad aantallen kunnen aanpassen zodat verschillen direct gecorrigeerd worden
Onderdelen reserveren (SPRINT 2)
Werkorderkoppeling
Als planner wil ik reparaties met onderdelen kunnen plannen zodat de juiste onderdelen op tijd gereserveerd zijn
Als monteur wil ik onderdelen kunnen reserveren voor een werkorder zodat ze beschikbaar zijn bij aanvang
Lage voorraad signaleren (SPRINT 3)
Alerts
Als inkoper wil ik automatische meldingen bij lage voorraad zodat ik tijdig kan bijbestellen
Bestelling via API (SPRINT 3)
Bestelproces
Als inkoper wil ik via een PartzNow API kunnen bestellen zodat bestellingen sneller en foutloos gaan
Als inkoper wil ik bestelsuggesties ontvangen zodat ik efficiënter en data‑gedreven kan inkopen
Als inkoper wil ik bestellingen kunnen verzenden vanuit het systeem zodat het proces end‑to‑end is
Inzicht per werkorder (SPRINT 1)
Werkorderinzicht
Als servicecoördinator wil ik per werkorder onderdelen en status zien zodat ik klantvragen kan beantwoorden
Als servicecoördinator wil ik een overzicht van werkorders met gebruikte onderdelen zodat ik kosten kan bewaken
Voorraad visualiseren (SPRINT 2)
Overzicht & Kaart
Als manager wil ik een dashboard met voorraadstatus zien zodat ik trends en knelpunten herken
Als logistiek planner wil ik leverstatus op een kaart zien zodat ik leveringen kan voorspellen en bijsturen
USM genereren (CLI)
Gebruik de TextUSM CLI (of npx) om van het .usm bestand een SVG te genereren:
npx textusm -i src/week-6-7-8-beroepsproduct/vergeten-voorraad-usm/vergeten-voorraad.usm \
-o src/week-6-7-8-beroepsproduct/vergeten-voorraad-usm/vergeten-voorraad-usm.svg
npx textusm -i src/week-6-7-8-beroepsproduct/vergeten-voorraad-usm/vergeten-voorraad-usm-2.usm \
-o src/week-6-7-8-beroepsproduct/vergeten-voorraad-usm/vergeten-voorraad-2-usm.svg
Tip: Op
https://app.textusm.com/kun je met dezelfde syntax interactief editen en exporteren.
Casussen Uitbreiding Pitstop
Kies een van onderstaande casussen of maak er zelf een.
Casus 1. Klant 'in the loop'

Notificatie systeem naar gebruikers dat reparatie gestart is, of reparatie klaar, of evt. input tussentijds nodig is (goedkeuren reparatie a.d.h.v. kosten). Het huidige notificatiesysteem in PitStop is alleen voor onderhoudsmeldingen.
Doel: doorlooptijden verkorten door snellere klantrespons en efficiënter gebruik van werkplaatsen.
Casus 2. Leenauto’s: geluk bij een ongeluk

Klanten kunnen tijdens reparatie een leenauto krijgen. Zij geven digitaal aan dát ze dit willen, welk type auto, en vinden voorwaarden en inleverdatum.
Samenwerking met leasemaatschappij; richt zich op klanten die een andere/leuke auto willen uitproberen tijdens reparatie.
Casus 3. Doe het zelf avonden

Module voor plannen en aanmelden voor informatieavonden waarin klanten onder begeleiding sleutelen. Doel: klantenbinding en benutten van ongebruikte avonduren.
Casus 4. Eigen functionaliteit (via prompt of ChatPUG)

Studentengroepen mogen zelf een passende functionaliteit voorstellen (niet te groot/klein). Gebruik als context de bestaande functionaliteit van PitStop en de voorbeelden hierboven. Je kunt hierbij een prompt gebruiken of de ChatPUG.
Prompt voor eigen uitbreiding
"Genereer een context- en opdrachtbeschrijving voor een nieuwe PitStop uitbreiding Zie de opdrachtbeschrijving en 3 voorbeelden op de minordevops.nl site. Concreet:
- Raadpleeg de bestaande functionaliteit van Microservice applicatie PitStop over 'Garage Maintenance' op https://github.com/EdwinVW/pitstop/wiki/Application%20functionality. Vertaal dit naar het Nederlands voor de introductie (onderdeel C hieronder)
- Kies een van de voorbeelden hierboven als referentie en stijl.
- Voor de gewenste functionele uitbreiding van PitStop genereer je 7 zaken:
- a. een coole project naam a la "Leenauto's" of "Klant in the loop", maar dan voor een nieuwe/andere functionele uitbreiding
- b. En ook een creatieve ondertitel, hierbij zoals "Geluk bij een Ongeluk"
- c. Een Nederlandse vertaling en parafrasering van de standaard functionaliteit van PitsStop via de eerder gegeven URL op github.com/EdwinVW als context beschrijving en introductie in een h2 kopje 'Context'.
- d. Een korte opdrachtbeschrijving waarin je minstens 2 gebruikersgroepen noemt en ook wat details qua 'working objects' als 'lijstjes', 'notificaties', 'overzicht', 'start ticker' of 'go/no beslissing' en functionaliteit en domeintermen uit PitStop zoals 'reparatie', 'doorlooptijd' en nieuwe termen uit de uitbreiding (dit zijn voorbeelden, gebruik deze NIET letterlijk, tenzij ze voor de door jou bedacht uitbreiding ook toevalllig relevant zijn)
- e. Genereer ook direct een afbeelding bij de opdracht, in lijn met de andere 3 (tekening rondom het thema, met liefst hierop een of meer personen in beweging (een beetje 'in actie').
- f. Geef tot slot een disclaimer dat dit een fictieve casus is, en dat genoemde API's en partijen niet per se echt zijn.
- g. Geef de bronnen, de 2 URL's op github.com en minordevops.nl van hierboven
Geef dan aan dat je graag door itereert op wat je hebt gemaakt. "Want één prompt is geen prompt..."
Maak van al bovenstaande een duidelijke zakelijke tekst, dus GEEN marketing tekst. Schrijf actief. Wees spaarzaam met bivoegelijke naamwoorden. Bewaar marketing voor het plaatje ;). Schrijf de hele tekst in b2 niveau Nederlands en in active vorm (dus NIET lijdend e.g. met 'word/worden' of 'is/zijn' + voltooid deelwoord). Laat ook de
a,b,ct/mgindeling weg uit je gegenereerde input. Dit is hierboven enkel voor het structureren van de prompt zelf. Graag 1 kopjes 1 met de Titel en dan dubbele punt en erachter de subtitel. Dan eronder direct het gegenereerde plaatje (afbeelding), liefst rechts uitgelijnd."
ChatPUG: PitStop Uitbreiding Generator
Er is per oktober 2024 ook een kant en klare 'custom GPT', een zogenaamde 'GPTs' beschikbaar. Deze bevat een uitgebreide variant van bovenstaande prompt. Hier de link naar chatgpt.com:
Dit is een service aan jou, maar geeft geen garantie op dat de output goed is (e.g. 'garantie tot de deur'). Controleer altijd zelf de output en werk iteratief verder.
PitStop C4 Architecture Documentation
Deze pagina bevat basis C4 model diagrammen van de PitStop Garage Management System volgens de C4 model standaard van Simon Brown. Voor je eigen PitStop uitbreiding kun je deze uitbreiden. Als je tijdens uitbreiden fouten opmerkt in bestaande, graag rapporteren bij de docent.
📋 Inleiding
De PitStop applicatie is een microservices-gebaseerd garage management systeem dat demonstreert moderne software architectuur concepten zoals Microservices Architecture, CQRS (Command Query Responsibility Segregation), Event Driven Architecture etc. Zie voor verdere info de docs/wiki/code in de Pitstop repo op Github van Edwin van Wijk.
🛠️ C4 Diagrammen Tools
Deze C4 diagrammen zijn gemaakt met de C4-PlantUML library en kunnen worden gevisualiseerd op/met:
- PlantUML Online Server: http://www.plantuml.com/plantuml/uml/
- VS Code Plugin: PlantUML Extension (vereist GraphViz installatie lokaal)
📚 Referenties
- C4-PlantUML Library - Officiële C4-PlantUML repository
- VS Code PlantUML Plugin - Voor lokale ontwikkeling
- C4 Model Website - Officiële C4 model documentatie
🏗️ C4 Model Diagrammen
C4 Context Diagram
Toont het systeem in zijn context - wie gebruikt het systeem en welke externe systemen interacteren ermee.
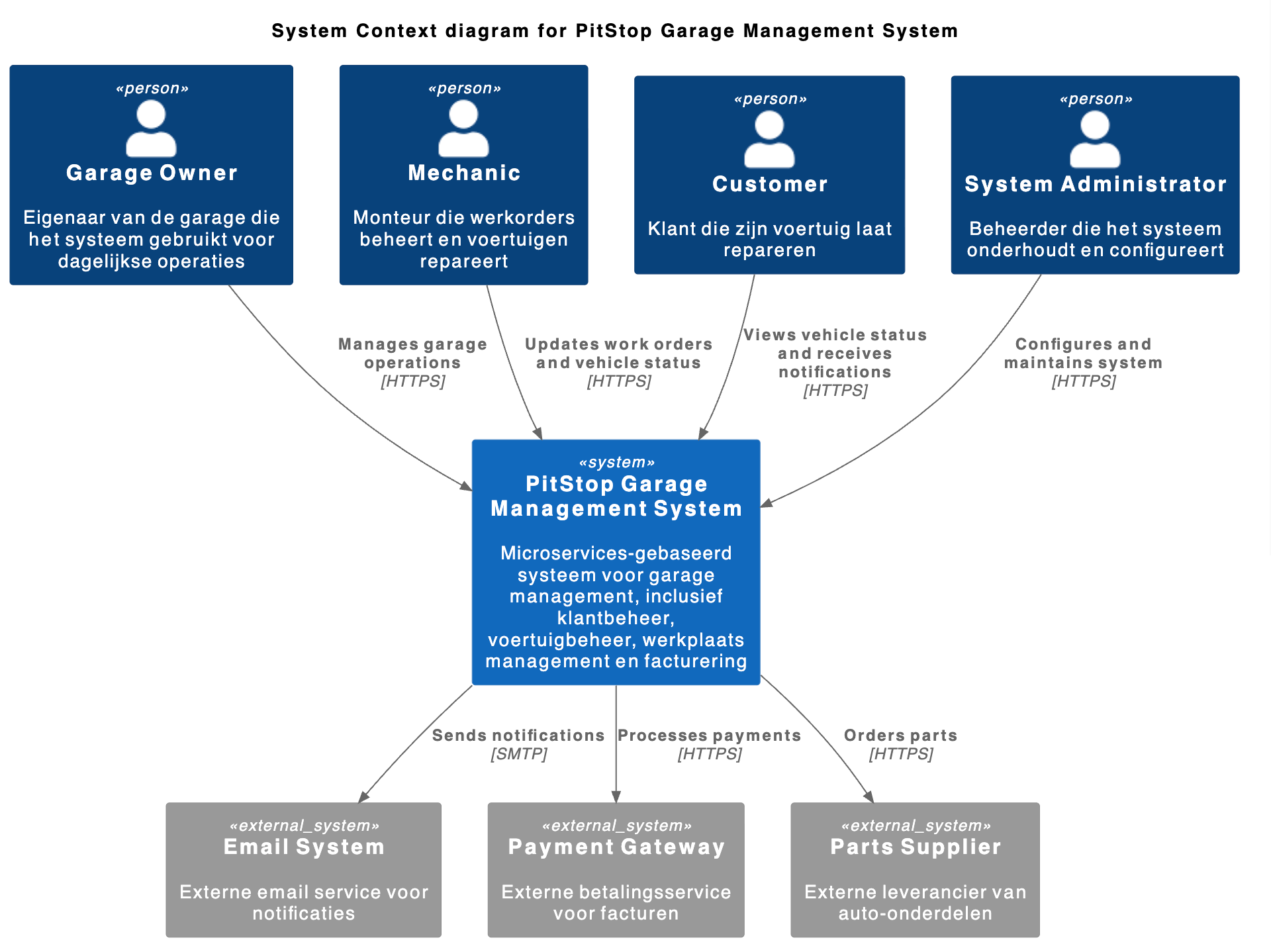
📋 PlantUML Code - C4 Context Diagram
```plantuml
@startuml C4_Context
!include https://raw.githubusercontent.com/plantuml-stdlib/C4-PlantUML/master/C4_Context.puml
title System Context diagram for PitStop Garage Management System
Person(garage_owner, "Garage Owner", "Eigenaar van de garage die het systeem gebruikt voor dagelijkse operaties")
Person(mechanic, "Mechanic", "Monteur die werkorders beheert en voertuigen repareert")
Person(customer, "Customer", "Klant die zijn voertuig laat repareren")
Person(admin, "System Administrator", "Beheerder die het systeem onderhoudt en configureert")
System(pitstop, "PitStop Garage Management System", "Microservices-gebaseerd systeem voor garage management, inclusief klantbeheer, voertuigbeheer, werkplaats management en facturering")
System_Ext(email, "Email System", "Externe email service voor notificaties")
System_Ext(payment, "Payment Gateway", "Externe betalingsservice voor facturen")
System_Ext(parts_supplier, "Parts Supplier", "Externe leverancier van auto-onderdelen")
Rel(garage_owner, pitstop, "Manages garage operations", "HTTPS")
Rel(mechanic, pitstop, "Updates work orders and vehicle status", "HTTPS")
Rel(customer, pitstop, "Views vehicle status and receives notifications", "HTTPS")
Rel(admin, pitstop, "Configures and maintains system", "HTTPS")
Rel(pitstop, email, "Sends notifications", "SMTP")
Rel(pitstop, payment, "Processes payments", "HTTPS")
Rel(pitstop, parts_supplier, "Orders parts", "HTTPS")
@enduml
```
🎯 Systeem Context
Gebruikers
- Garage Owner: Beheert dagelijkse garage operaties
- Mechanic: Werkt met werkorders en voertuigreparaties
- Customer: Bekijkt voertuigstatus en ontvangt notificaties
- System Administrator: Onderhoudt en configureert het systeem
Externe Systemen
- Email System: Voor notificaties naar klanten en medewerkers
- Payment Gateway: Voor het verwerken van betalingen
- Parts Supplier: Voor het bestellen van auto-onderdelen
Systeem Verantwoordelijkheden
Het PitStop systeem is verantwoordelijk voor:
- Klantbeheer en registratie
- Voertuigbeheer en onderhoudshistorie
- Werkplaats planning en werkorder beheer
- Facturering en betalingen
- Notificaties en communicatie
- Audit logging en compliance
C4 Container Diagram
Toont de high-level vorm van de architectuur en hoe verantwoordelijkheden zijn verdeeld over containers.
Architectuur Toelichting
De Notification Service is een .NET Core Worker die voor lokale ontwikkeling een lokale email service gebruikt - het stuurt geen echte emails tijdens development. In productie zou deze service geïntegreerd worden met een echte SMTP provider.
De RabbitMQ Message Broker fungeert als het centrale zenuwstelsel van de architectuur, waarbij alle API's events publiceren en de worker services deze asynchroon verwerken. Dit zorgt voor loose coupling tussen services.
De Web Application fungeert als een thin client die voornamelijk API calls maakt naar de verschillende management API's. Er is geen directe database toegang vanuit de frontend.
De Audit Service is specifiek ontworpen als write-only service voor compliance doeleinden - het logt alle systeem activiteiten maar leest nooit data terug voor business logica.
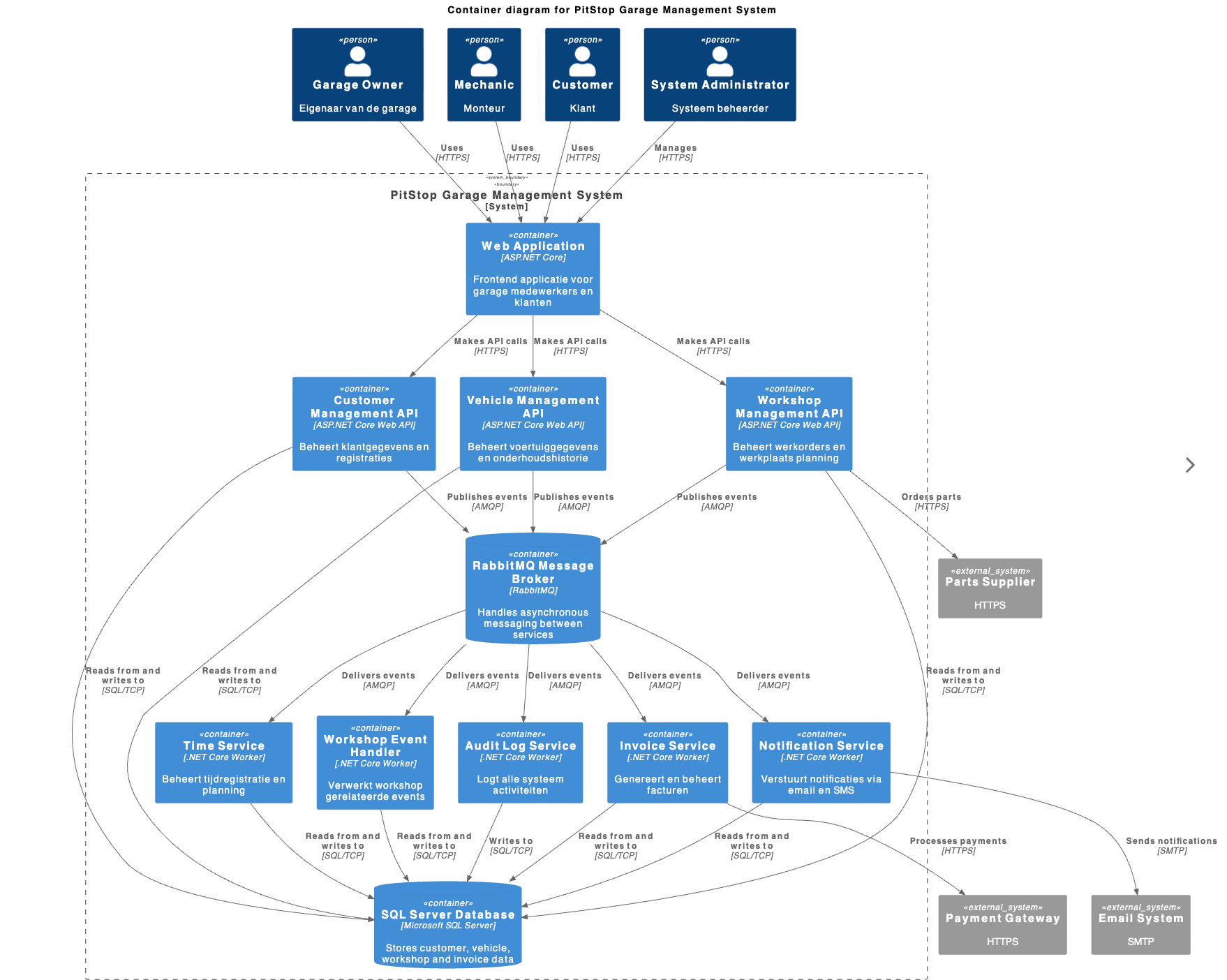
📋 PlantUML Code - C4 Container Diagram
```plantuml
@startuml C4_Container
!include https://raw.githubusercontent.com/plantuml-stdlib/C4-PlantUML/master/C4_Container.puml
title Container diagram for PitStop Garage Management System
Person(garage_owner, "Garage Owner", "Eigenaar van de garage")
Person(mechanic, "Mechanic", "Monteur")
Person(customer, "Customer", "Klant")
Person(admin, "System Administrator", "Systeem beheerder")
System_Boundary(pitstop_system, "PitStop Garage Management System") {
Container(webapp, "Web Application", "ASP.NET Core", "Frontend applicatie voor garage medewerkers en klanten")
Container(customer_api, "Customer Management API", "ASP.NET Core Web API", "Beheert klantgegevens en registraties")
Container(vehicle_api, "Vehicle Management API", "ASP.NET Core Web API", "Beheert voertuiggegevens en onderhoudshistorie")
Container(workshop_api, "Workshop Management API", "ASP.NET Core Web API", "Beheert werkorders en werkplaats planning")
Container(invoice_service, "Invoice Service", ".NET Core Worker", "Genereert en beheert facturen")
Container(notification_service, "Notification Service", ".NET Core Worker", "Verstuurt notificaties via email en SMS")
Container(audit_service, "Audit Log Service", ".NET Core Worker", "Logt alle systeem activiteiten")
Container(time_service, "Time Service", ".NET Core Worker", "Beheert tijdregistratie en planning")
Container(workshop_event_handler, "Workshop Event Handler", ".NET Core Worker", "Verwerkt workshop gerelateerde events")
ContainerDb(sqlserver, "SQL Server Database", "Microsoft SQL Server", "Stores customer, vehicle, workshop and invoice data")
ContainerDb(rabbitmq, "RabbitMQ Message Broker", "RabbitMQ", "Handles asynchronous messaging between services")
}
System_Ext(email, "Email System", "SMTP")
System_Ext(payment, "Payment Gateway", "HTTPS")
System_Ext(parts_supplier, "Parts Supplier", "HTTPS")
' User interactions
Rel(garage_owner, webapp, "Uses", "HTTPS")
Rel(mechanic, webapp, "Uses", "HTTPS")
Rel(customer, webapp, "Uses", "HTTPS")
Rel(admin, webapp, "Manages", "HTTPS")
' Web app to APIs
Rel(webapp, customer_api, "Makes API calls", "HTTPS")
Rel(webapp, vehicle_api, "Makes API calls", "HTTPS")
Rel(webapp, workshop_api, "Makes API calls", "HTTPS")
' APIs to database
Rel(customer_api, sqlserver, "Reads from and writes to", "SQL/TCP")
Rel(vehicle_api, sqlserver, "Reads from and writes to", "SQL/TCP")
Rel(workshop_api, sqlserver, "Reads from and writes to", "SQL/TCP")
' Event-driven communication
Rel(customer_api, rabbitmq, "Publishes events", "AMQP")
Rel(vehicle_api, rabbitmq, "Publishes events", "AMQP")
Rel(workshop_api, rabbitmq, "Publishes events", "AMQP")
Rel(rabbitmq, invoice_service, "Delivers events", "AMQP")
Rel(rabbitmq, notification_service, "Delivers events", "AMQP")
Rel(rabbitmq, audit_service, "Delivers events", "AMQP")
Rel(rabbitmq, time_service, "Delivers events", "AMQP")
Rel(rabbitmq, workshop_event_handler, "Delivers events", "AMQP")
' Services to database
Rel(invoice_service, sqlserver, "Reads from and writes to", "SQL/TCP")
Rel(notification_service, sqlserver, "Reads from and writes to", "SQL/TCP")
Rel(audit_service, sqlserver, "Writes to", "SQL/TCP")
Rel(time_service, sqlserver, "Reads from and writes to", "SQL/TCP")
Rel(workshop_event_handler, sqlserver, "Reads from and writes to", "SQL/TCP")
' External integrations
Rel(invoice_service, payment, "Processes payments", "HTTPS")
Rel(notification_service, email, "Sends notifications", "SMTP")
Rel(workshop_api, parts_supplier, "Orders parts", "HTTPS")
@enduml
```
Kubernetes copy-paste snippets
Hieronder staan drie minimale voorbeelden (Deployment, Service en Ingress) die je kunt kopiëren en aanpassen.
- Namespace:
k8s/00-namespaces.yml - Deployment:
k8s/01-deployment.yml - Service:
k8s/02-service.yml - Ingress:
k8s/03-ingress.yml
1) Deployment (Rolling update, 1 replica)
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-world
namespace: demo
labels:
app: apache
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0
maxSurge: 1
selector:
matchLabels:
app: apache
template:
metadata:
labels:
app: apache
spec:
containers:
- name: apache
image: httpd:2.4
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
2) Service (ClusterIP)
---
apiVersion: v1
kind: Service
metadata:
name: apache-service
namespace: demo
spec:
selector:
app: apache
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
3) Ingress (basic host + path)
Vereist een Ingress Controller (bijv. NGINX Ingress). Pas de hostnaam aan.
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: apache-ingress
namespace: demo
annotations:
kubernetes.io/ingress.class: nginx
spec:
rules:
- host: your-app.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: apache-service
port:
number: 80
Quiz
Test je kennis over Kubernetes objecten en httpd met onderstaande korte multiple choice quiz.
Bronnen
- Apache httpd op Docker Hub:
https://hub.docker.com/_/httpd
FAQ Eindopdracht
Onderzochte technologie toepassen in beroepsproduct
Vraag: Ik kan mijn beoogde onderzochte technologie toch niet toepassen. Kan ik nu alsnog een voldoende halen voor het project?
Antwoord 1
Dit kan gebeuren. Als je vantevoren al 100% wist dat de technologie ging werken, was deze wellicht niet spannend genoeg. Of je alsnog een voldoende haalt hangt af van je motivering. Als je tijdens kort vooronderzoek de problemen al had kunnen voorzien, had je de technologie niet moeten onderzoeken. Het idee van praktisch onderzoek is dat je de resultaten gebruikt om het toe te passen. Onderzoek alleen voor theorie doen we niet in dit project/vak.
Idealiter merk je aan het eind van het onderzoek al dat het onderzochte wellicht niet past. Soms stuit je op een bug of moeilijk te voorzien integratieprobleem. Gebruik alsnog je geschreven blogpost als referentie voor de toekomst, of als genoemd/overwogen alternatief voor een wel gebruikte technologie of aanpak (denk aan decision forces diagram). Als er een bug is, geef een referentie naar documentatie of een issue in een open source repo. Mocht deze er niet zijn, maak deze dan zelf aan om de community verder te helpen.
Als de enige reden dat je het niet toegepast hebt is dat je hier geen tijd voor had, is dit in principe niet geldig. Je moet dan althans in je documentatie een beschrijving geven hoe het wel toegepast kan worden bij voldoende tijd. Geef een oplossingsrichting.
Unieke technologie
Vraag: Ik wil dezelfde technologie onderzoeken als mijn teamgenoot
Antwoord 2
Dat mag niet :|. Het is de bedoeling je eigen specialisatie te hebben. Niet om het onderzoek GEHEEL met zijn tween te doen. Uiteraard mag je elkaar wel helpen en verder samenwerken. Als het een grote tool of framework is waar je beiden één aspect of feature van wilt onderzoeken mag dit wel. Stem dan onderling gezamenlijke zaken af en zorg dat je ook een eigen aspect onderzoekt. Licht deze situatie ook kort toe in de inleiding van je blogpost en verwijs naar elkaars blog posts, met een quote of parafrase waaruit de lezer een idee heeft wat het is en wat de verschillen zijn.
Teamonderzoek en presentatie
Vraag: Hoe presenteer je als team de verschillende onderzochte technieken die je toepast in PitStop? En hoe maak je een gezamenlijke presentatie met de gezamenlijke PitStop uitbreiding als doel en gedeelde casus?
Antwoord 3
Als team presenteer je gezamenlijk, maar iedereen heeft zijn eigen specialisatie en onderzochte technologie. Start met jullie gedeelde casus/uitbreiding voor PitStop om context te creëren. Iedere teamgenoot presenteert vervolgens zijn/haar technologie (2-3 minuten per persoon) en legt uit hoe deze bijdraagt aan jullie gezamenlijke uitbreiding. Sluit af met hoe alle technieken samenkomen. Maak een gedeeld format/template, bedenk een logische volgorde met onderlinge 'hand-offs', en verwijs naar elkaars onderzoek. Gebruik je blogposts als basismateriaal en voorkom 'death by Powerpoint' — spreek met impact. Zie de Spike Guide voor meer details over de presentatie structuur en tips.
Deeltoetsen 2
Oefendeeltoets Dev 2/2
Edit minor 2024/'25: De oefenquizzes op specifieke pagina's zijn meer bijgewerkt en hebben minder oververtegenwoordiging van Kubernetes vragen dan onderstaande pdf's (hoewel deel van K8S vragen nog wel relevant zijn):
- Oefendeeltoets 1 (5 minuten)
- Oefendeeltoets 2
De toetsen gaan over alle stof in week 3 t/m 5 in de course.
Hieronder voor 2024 een korte samenvatting. Maar het is handiger om zelf een samenvatting te maken tijdens het doornemen/herhalen van de stof uit online materiaal, gelinkte bronnen en slides, etc.
Neem ook de leerdoelen van de weekthema's en lessen door en controleer dat je hierover de kennis ('kent') of vaardigheid ('kan') hebt, door een verhaaltje te vertellen.
Toetsstof 2024
- Micro Frontends
- C4 & Continuous Documentation
- RabbitMQ
- Continuous Delivery (incl. 12factor, IAAS vs PAAS vs DevOps three ways e.d.)
- Domain Driven Design (DDD) + Webscale + Microservices (MSA)
- Behaviour Driven Design (BDD)
- Event Driven Architectures (EDA)
- SemVer
- Orchestration/Kubernetes (etcd)
- CDMM (niet uit hoofd, maar CDMM categorieen en checkpoints hieronder wel herkennen en kunnen uitleggen/toepassen)
SlackOps (Chaos engineering)
Week 9 - Presentaties, herkansingen, transfer naar project blok 2
- Les 1 - Eindpresentaties
- Vrijdag: Minor DevOps Workshop Maarten van Golen MCPS
- Herkansing theorietoetsen (meer info)
De volledige formele eisen, competenties en beoordeling staan in de de OWE.
De beoordeling van het beroepsproduct is in de vorm van een teampresentatie van het gebouwde product, en live deployment. Tot slot geef je hier ook de als team eerder vastgestelde self assessment op basis van het Continuous Delivery Maturity Model (CDMM). Met ook verbeterpunten en/of richtingen van evt. known issues.
Op een andere dag een meer inhoudelijke review meeting ook met het hele team, maar dan met van alle teamleden toelichting van eigen bijdrage in product en kwaliteit hiervan. Hierbij laat je ook documentatie zien zoals C4 diagrammen, Architecture Decision Records en een goeie README. Maar de mondelinge toelichting vinden we minstens zo belangrijk als 'comprehensive documentation'. Dit is vergelijkbaar met de beoordelingvorm in het grote project in blok 2. Je code moet zoveel mogelijk voor zichzelf spreken (the code IS the design). Maar gekozen technologieen moet argumentatie voor zijn (DRY vs YAGNI e.d.).
Na de presentaties is deze week ook de herkansingsmogelijkheid van theorietoetsen. En eind van de week kennismaking met de opdrachtgever.
Week 9 - Herkansings(totaal)toetsen
Als je voor één of meer deeltoetsen een onvoldoende had en je cijfer wilt ophalen, of zelfs als je al voldende had, maar je cijfer gewoon wilt ophalen, heb je op deze dag een totaaltoets voor zowel de course Dev als de course DevOps. Je moet je wel vantevoren aanmelden via ~~iSAS~~Osiris. Het lokaal navragen bij de docent (of evt. in iSAS).
NB: De grote set Kubernetes oefenvragen uit Kahoots zijn ook in deze oefentoets gezet, i.v.m. lagere toegankelijkheid van Kahoots.
Donderdag 6 november 2025 11:30-13:00 (lokaal: C1.06)
- 11:30 Lokaal open, intro en regels
- 11:35 TheorieToets Dev: Linux, C4, RabbitMQ
- 12:05 Einde/Pauze
- 12:15 Theorietoets DevOps: GitOps t/m SlackOps en DDD t/m EDA...
- 12:45 Einde/Evt. kort nabespreken desgewenst
- 13:00 Einde
DevOps (voltijd)
"Let's do some major DevOps!"
In deze multidisciplinaire minor staat de moderne techniek DevOps centraal. In een DevOps-team werken developers en beheerders samen om nieuwe features van een applicatie te ontwikkelen, en tegelijkertijd de bestaande features draaiende te houden.
Hierbij is er veel aandacht voor het garanderen van een hoge beschikbaarheid van een applicatie. We gaan kijken naar loosely coupled micro services, event-carried state transfer, Docker, Kubernetes, RabbitMQ, unit testen, acceptatie testen, build- en release-pipelines, logging, monitoring, site reliability engineering, kort-cyclisch development en natuurlijk de samenwerking tussen Dev en Ops.
De minor bestaat uit twee gedeelten: een gedeelte met theorie en een kleinschalig project waarin zowel je theoretische als praktische kennis wordt voorbereid op het tweede deel: het uitvoeren van een grootschalige project voor een echte klant waarbij je je expertise optimaal kunt benutten. Beide delen worden verzorgd door de HAN en Info Support samen, waarbij de HAN vooral in het eerste en Info Support vooral in het tweede deal de lead zal nemen in de begeleiding.
Afhankelijk van het profiel dat je volgt, wordt aandacht besteed aan de volgende onderwerpen:
- Devops
- Test driven development
- Deployment-tooling (CD/CI-tools, containers, container orchestration)
- Management en beheer (configuration management, monitoring, logging, cloud providers)
- (Domain driven) design en design patterns
- OO-programmeren
- REST
- ORM
- Web- en applicatieservers
- Versiebeheersystemen (zoals Git)
- Operating systems
- Netwerken, security en protocollen
- Proxies, load balancers, firewalls
Leerdoelen
Na het volgen van deze minor beschik je over de theoretische en de praktische kennis om een DevOps ontwkkelproject in te richten en uit te voeren in een professionele organisatie.
Aanvullende informatie
Voor meer informatie:
info@han.nl | T (024) 35 30 500 van 09.00 tot 16.30 bereikbaar | www.han.nl
Contactpersoon minor
Bart van der Wal E-mail: bart.vanderwal@han.nl
Inschrijven? Goed om te weten!
Bij populaire minoren vindt 3 tot 4 weken na het open gaan van de inschrijvingen een loting plaats áls er op dat moment meer inschrijvingen zijn dan beschikbare plaatsen. Bij de minoren waar nog plaats is, geldt daarna tot aan de sluiting van de inschrijfperiode: zodra een minor vol is, wordt deze gesloten, vol = vol.
Daarnaast geldt dat als het aantal aanmeldingen na drie weken ruim onder de norm ligt; deze minor mogelijk wordt teruggetrokken. Dus heb je interesse, meld je direct aan.
Schrijf je op tijd in!
Let op: Voor HAN studenten geldt dat zij zich, in geval van uitloten of geen doorgang van de eerste keuze NA de periode van besluitvorming (deze duurt ca. 3 weken), kunnen herinschrijven. Dit kan alleen op de dan nog beschikbare minoren die plaatsen vrij hebben.
Ook dan geldt: zodra een minor vol is, wordt deze gesloten, vol = vol.
Een goed overzicht van de HAN minoren kun je vinden in de minoren app! De app is bereikbaar via: http://www.minoren-han.nl/
Toetsing
Er zijn 2 deeltoetsen voor de DevOps course. Verder zijn er wekelijkse verplichte opdrachten.
Tot slot is er een DevOps beroepsproduct waar je met een team 2 weken aan werkt en tot slot presenteert voor beoordelaars en ook individuele bijdrage aan toelicht tijdens een review sessie.
De toetsing is de standaard projecttoetsing met een tussentijds groepsbeoordeling en individuele beoordeling en hetzelfde op het eind. De beoordelingscriterie en eisen tijdens het project volgen begin van het project.
Zie details overweging en beoordeling in de officiële OWE beschrijving.
Rooster
Er wordt vanuit gegaan dat studenten van maandag t/m vrijdag beschikbaar zijn, dus bijbaantjes of andere vakken van maandag t/m vrijdag (9.00-17.45 uur) volgen is geen optie.
De roostering zal plaatsvinden zoals bij AIM gebruikelijk: in de coursefase (MINDEC05) 4 tot 6 maal per week een dagdeel les (verder zelfstudie) en in de projectfase (MINDEP01) 40 uur per week projectwerk.
Werkvormen
- Werkcolleges
- Projectopdracht
Deze tekst staat ook op kiesopmaat.nl (dd, 1 feb 2021)
DevOps tools (tech in deze minor (logo attributie) 
Presented by:

Courses - Blok 1 bij AIM
- git
- Markdown
- Docker
- OpenNebula
- Kubernetes
- GiHub
- Java
- Cucumber
- RabbitMQ
- ELK
- npm
- Ansible
- DevOps schema
- DotNet core
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Project - Blok 2 bij InfoSupport
- Argo
- Azure
- Azure DevOps
- React
- Java 11
- Docker
- Kubernetes
- Argo
- Micronaut (todo logo)
{kind=link}
{kind=link}
Logo's
![]()
![]()

![]()

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()

Java Unit testing met Maven, Surefire en JUnit

Bart van der Wal, augustus 2024.
Dit is de Java/Spring Boot variant van de tutorial 'Unit testing C# in .NET using dotnet test and xUnit' op Microsoft Learn (2024). Deze tutorial toont een project opzet met een:
- unit test-project
- en een broncode-project
Om de tutorial te volgen met een vooraf opgebouwd project, kun je de voorbeeldcode op GitHub (van der Wal, 2024) bekijken of downloaden. We gaan er van uit dat je weet hoe dit werkt.
Hieronder eerst een toelichting over de wijzigingen t.o.v. de originele C# variant/tutorial en de context. Dit is ook interessant voor studenten die deze opdracht doen. Daarna 5 instructiestappen om te volgen meer specifiek voor Java Spring Boot variant. Hiervan is de laatste optioneel.
1. Toelichting
Deze tutorial is naast starter van de week opdracht ook een beetje een voorbeeld blog post, zoals je zelf in week 6 moet schrijven. Met in ieder geval een hands-on karakter via voorbeeld code om over te nemen en terminal commands om uit te voeren voor jou als lezer. Ook bevat deze APA referenties, zoals je zelf in de blog moet gebruiken. is in het Nederlands Alleen het 'onderzoekskarakter' is wellicht ondermaats als voorbeeld. Alhoewel ik hieronder wel wat beschouwingen doe en aansluit bij DevOps concepten zoals de DevOps roadmap en het Continuous Delivery Maturity Model (CDMM) die je ook een beetje, respectievelijk zelfs heel goed moet leren kennen in de minor.
Deze tutorial schreef ik naar aanleiding van minor DevOps 2024 waarin we licht varieren/diverisificeren t.o.v. eerdere edities. Dit in het kader van concept van 'Polyglot X' uit DevOps: dat microservices verschillende talen/frameworks kunnen gebruiken. Hiermee stijg je uit boven het basis niveau (Base level) uit het CDMM (een soort DevOps Maturity Model, InfoQ, 2013):
"Many organizations at the base maturity level will have a diversified technology stack but have started to consolidate the choice of technology and platform, this is important to get best value from the effort spent on automation."
Merk op dat er hierbij het checkpunt uit CDMM 'consolidate' (MinorDevOps, z.d.)) er wel een gemene deler Docker of Kubernetes is. Qua communicatie tussen de microservices is (gewoon via een) http API een standaard, maar in een latere week van de minor leren studenten ook een voorbeeld van een 'message bus' of (eigenlijk) 'message broker' namelijk RabbitMQ. ZO ga je naar meer advanced level van CDMM:
"...split the entire system into self contained components and adopt[ed] a strict api-based approach to inter-communication so that each component can be deployed and released individually." (InfoQ, 2013)

Figuur 1: Deel van DevOps roadmap wat aangepast naar context van minor DevOps (roadmap.sh, 2024)
De helft van de studenten (-teams/-duo's) doet de opdracht met .NET. De andere helft met Java, Spring Boot. In opdracht van week 2 ga je verder door de deze basis applicatie 'containerizen'.
2. Installeren scoop of SDKMan en dan Spring Boot CLI
We start een Java project met Spring Boot. Hierbij gebruiken we Maven als package manager zoals gebruikelijk bij Software Engineering op de HAN. Je bent misschien geneigd om IntelliJ te gebruiken. En voor het editen van code is dit prima, maar voor de herhaalbaarheid/scriptability ga je nu als DevOps-er, de initiele opzet via de commandline doen.
Installeer daarvoor de Spring Boot CLI (Command line interface) conform de instructies op de website (Spring Boot, z.d.): Maar het lijkt wel 'turtles all the way down', want voordat je Spring CLI kunt installeren (Spring Boot, z.d.) moet je eerst een package manager installeren, maar gebruik (en installeer) bv. scoop op Windows (scoop, z.d.), brew op macOS of sdkman als je Linux gebruikt.
Dit is een korte samenvatting voor Windows gebruikers (macOS en Linux komen er sowieso wel uit, toch?)
"Open een PowerShell terminal (version 5.1 or later) en vanaf de PS C:> prompt, run:
Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
Invoke-RestMethod -Uri https://get.scoop.sh | Invoke-Expression
En daarna op de command line:
scoop bucket add extras
scoop install springboot
Bij onverhoopte errors, backtrace check de gegeven/originele bronnen/website voor installatie instructies, dit verandert vaak snel over de tijd.
3. Start Java Spring Boot project
Deze sectie beschrijft het maken van een Spring Boot Java project met de applicatie code en ook meteen een eigen test package. De project moet de volgende directory structuur en bestanden krijgen, conform standaard Maven structuur:
/priemtester
pom.xml
src/main/java/nl/han/devops/
PriemTesterApplication.java
PriemTester.java
src/main/java/nl/han/devops
PriemTesterTests.java

Figuur 2: Je zou de Spring Initializer in IntelliJ CLI kunnen gebruiken, maar...

Figuur 3: Beter: gebruik de Spring boot CLI, don't be afraid of the command line!
Voer onderstaand commando uit. Superkort is het ook niet meer, maar je customized meteen de package naam en naam van java klasse met je main(..) functie (dit wordt PriemTesterApplication).
spring init --build=maven --package-name=nl.han.devops priemtester
Je mag nu de applicatie is aangemaakt deze wel openen in IntelliJ IDEA. Installeer deze als je deze nog niet hebt staan (best meteen Ultimate editie via je HAN student e-mail). Of navigeer naar je project directory en open deze in de VS Code editor:
cd priemtester
code .
4. Make it your own!
Hernoem DemoApplication.java naar PriemTesterApplication.java.
Maak een nieuwe klasse PriemTester.java met de volgende code:
package nl.han.devops;
public class PriemTester {
public boolean isPriemgetal(int candidate) {
throw new UnsupportedOperationException("Nog niet geïmplementeerd.");
}
}
Aangezien we een unit test gaan schrijven van de 'domein' logica, en NIET de gehele Applicatie (dat zou een integratietest zijn) hernoem ook de DemoApplicationTests.java naar PriemTesterTests.java om deze te 'repurposen'. Verwijder dan ook de gegenereerde contextLoads() methode, die hier dan niet meer thuishoort.
Deze code gooit nu een UnsupportedOperationException met een bericht dat deze methode nog geimplementeerd is. Op deze manier compileert de code wel, en kun je het runnen, maar is duidelijk wat er aan de hand is, ook als je dit stuk code een paar dagen laat liggen, en dan pas weer terug komt. Maar nu gaan we dit gaan we al veel sneller aanpassen ;).
De NIET TDD manier om de code te runnen/testen zou zijn om in je main de nieuwe methode aan te roepen. Je kunt even tijdelijk de code in je main methode in PriemTesterApplication.java als volgt maken, aangezien deze nu nog niet echt iets doet, en om wel te checken of je nog Java programma's kunt runnen ;). Maar verwijder deze code daarna weer.
public static void main(String[] args) {
SpringApplication.run(PriemTesterApplication.class, args);
// Tijdelijke test code.
var priemTester = new PriemTester();
for(int i = 0; i<10; i++) {
System.out.println("Getal " + i + " is een priemgetal?" + priemTester.isPriemgetal(i));
// Einde tijdelijke test code, beter via TDD
}
}
We gaan nu unit tests gebruiken als entry points in plaats van de main methode. Zo kom je ook netjes tot TDD: Test Driven Development, zoals verplicht in deze minor! En 'vervuil' je je main methode niet met test code.
5. Maak een test, TDD all the way!
Een populaire aanpak in testgestuurde ontwikkeling (TDD) is om eerst een (mislukkende) test te schrijven voordat de doelcode wordt geïmplementeerd. Deze tutorial gebruikt de TDD-aanpak. De methode IsPrime kan worden aangeroepen, maar is niet geïmplementeerd. Een testaanroep naar IsPrime faalt. Bij TDD wordt een test geschreven waarvan bekend is dat deze zal falen. De doelcode wordt vervolgens bijgewerkt om de test te laten slagen. Je herhaalt deze aanpak steeds opnieuw: je schrijft een falende test en werkt daarna de doelcode bij om te slagen.
Vul de code in PriemTesterApplicationTests met test methodes voor input 1 en 2. Later komen er meer methodes in de verzameling tests. Zo'n verzameling tests noemt men ook wel een test suite.
NB: Dit woorde 'suite' in 'test suite' spreek je ANDERS uit dan het woord 'suit' (=pak), wat veel mensen foutief zeggen. Je zegt 'suite' meer als 'zwiete' (of 'sweet' in het Engels). Luister anders eens op Google Translate naar het Nederlands en evt. ook de Engelse variant, via de volgende link:
https://translate.google.com/?sl=nl&tl=en&text=test%20suite&op=translate (als developer/devopser moet je ook kunnen praten over je vak, dus probeer hier zelf eens zinnen of woorden uit als je twijfelt hoe je ze uitspreekt)
@SpringBootTest
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
class PriemTesterApplicationTests {
PriemTester sut;
@BeforeAll
void beforeAll() {
sut = new PriemTester();
}
@Test
void PriemTester_1_is_geen_priemgetal() {
// Arrange.
// TODO Refactoren dit soort herhalende code.
// DAMP: DRY voor unit tests: Descriptive And Meaningfull Phrases.
sut = new PriemTester();
var input = 1;
var expected = false;
// Act.
var actual = sut.isPriemgetal(input);
// Assert.
Assertions.assertEquals(expected, actual);
}
@Test
void PriemTester_2_is_een_priemgetal() {
// Arrange.
// TODO Refactoren dit soort herhalende code.
// DAMP: DRY voor unit tests: Descriptive And Meaningfull Phrases.
sut = new PriemTester();
var input = 2;
var expected = true;
// Act.
var actual = sut.isPriemgetal(input);
// Assert.
Assertions.assertEquals(expected, actual);
}
De @Test annotatie maakt een methode als een test methode die gerund wordt door de 'test runner'.
De naam van een test methode maakt technisch niet uit, maar het is belangrijk deze een beschrijvende naam te geven.
Verder biedt JUnit ook de @BeforeEach en @BeforeAll annotatie die telkens voor elke test (in de testsuite) respectievelijk eenmaal voor start van op de (gelijknamige) methode)
Run mvn test. En/of gebruik de 'play' toets op toetsmethodes in je editor/IDE.
Los de TODO's op door herhalende code te refactoren naar de BeforeAll. En run de tests opnieuw om te checken dat alles nog werkt.
Breidt nu de applicatie code isPriemgetal uit met de volgende code:
public boolean isPriemgetal(int kandidaat) {
if (kandidaat == 1) {
return false;
}
throw new UnsupportedOperationException("Niet geheel geïmplementeerd.");
}
Run weer de tests.
6. Meer testgevallen via parametriseren testmethode
Voeg tests toe voor input 0 en -1. Je kan verder gaan copy-pasten en wat aanpassen. Maar dat is niet DRY (Don't Repeat Yourself), maar WET (Write Everything Twice). Er is een betere manier!
bool result = sut.IsPrime(1);
Assert.False(result, "1 zou geen priemgetal moeten zijn");
Er bestaan nog extra JUnit annotaties die het mogelijk maken een suite van vergelijkbare tests op te stellen.
Je kunt gebruik maken van @ParameterizedTest om een reeks tests uit te voeren met verschillende invoerargumenten. De annotatie @ValueSource specificeert de waarden voor die invoer. In plaats van afzonderlijke test methodes te schrijven, gebruik je deze JUnit annotaties om één enkele testtheorie te creëren. Als volgt:
package nl.han.devops;
import org.junit.jupiter.api.*;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.ValueSource;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class PriemTesterTest {
private final PriemTester priemTester = new PriemTester();
@ParameterizedTest
@ValueSource(ints = {-1, 0, 1, 2})
public void isPriemgetal_WaardenKleinerDan2_ReturnFalse(int value) {
boolean result = priemTester.isPriemgetal(value);
Assertions.assertFalse(result, value + " zou geen priemgetal moeten zijn");
}
}
NB Conform lessen uit het 1e Semester van Software Engineering, is het goed de priemTester variabele in bovenstaande code te hernoemen naar sut om evident te maken dat de PriemTester klasse de system under test is in deze unit test.
Run mvn test en twee van de testen zullen falen. Om alle tests te laten slagen, update de IsPriem methode met de volgende code:
public bool IsPriemgetal(int kandidaat) {
if (kandidaat < 2) {
return false;
}
throw new NotImplementedException("Not fully implemented.");
}
Volg de TDD aanpak, en voeg meer falende testen toe, en update de applicatie code. Zie evt. de uiteindelijke versie van de implementatie op GitHub.
Let op: Deze IsPriem methode is GEEN efficient algoritme om te testen of een getal een priemgetal is (hiervoor kun je best een bestaande oplossing/package uit NuGet of MavenCentral repository halen).
7. Optionele extra opdracht: Make it fast.
Binnen Software Engineering, en ook in deze minor, richten we ons vooral op de 'make it work' fase en dan de 'make it nice' fase uit het bekende adagium van Beck's bekende gezegde over code:

Figuur 4: "Make it work, make it nice, make it fast." - Kent Beck, z.d. (TODO: APA), Bron plaatje: the tombomb
Maar voor de liefhebbers, die eens willen kijken naar 'make it fast'. Best manier is toch dit van andere te jatten, en je eigen originaliteit te bewaren voor onopgeloste problemen (of oplossing van bestaande problemen toepassen in nieuwe domeinen, waar niemand dit probleem al echt heeft gezien ... 😉 💶).
Voor een WEL efficiente methode, of in ieder geval efficientere aanpak zoek zelf een package in NuGet of Maven central, bestudeer de README/documentatie of community feedback of deze goed is, en voeg hiervan de URL als bron toe. En voeg een variant toe van deze implementatie. Liefst via eerst extracten van een interface uit je huidige PriemTester (met refactor optie van IntelliJ bv; of anders handmatig. Deze interface noem je PriemTester en je huidige implementatie hernoem je naar CustomPriemTester. Dan maak je een nieuwe implementatie EfficientPriemTester, en hierin roep je de Maven package aan. Feitelijk is dit nu een.... Adapter patroon). Later zou je een load test kunnen bouwen, om de twee implementaties op performance/snelheidsverschillen te kunnen testen.
Bronnen
- InfoQ (2013). The Continuous Delivery Maturity Model. Geraadpleegd 27 augustus 2024 op https://www.infoq.com/articles/Continuous-Delivery-Maturity-Model/
- Minor DevOps (z.d.) Beoordelingsmodel Groep. Geraadpleegd op 27-8-2024 op https://minordevops.nl/beoordelingsmodel-groep.html
- Microsoft Learn (3-7-2024) Use code coverage for unit testing. Geraadpleegd op 26 aug 2025 op op https://learn.microsoft.com/en-us/dotnet/core/testing/unit-testing-code-coverage vervanging van de 10 juli 2025 gewijzigde pagina die vroeger titel Unit testing with dotnet test and xUnit had
- Scoop.sh (z.d.) Scoop geraadpleegd op 2 september 2024 op https://scoop.sh/
- Spring Docs (z.d.) Installing the CLI :: Spring Boot, Geraadspleegd op 27-8-2024 op https://docs.spring.io/spring-boot/cli/installation.html
- Spring.io (z.d.) Installing Spring Boot CLI geraadpleegd op 2 september 2024 op https://docs.spring.io/spring-boot/installing.html#getting-started.installing.cli
- Wal, B. van der. (2 september 2024) Priemtester code. geraadpleegd op 2 september 2024 op https://github.com/hanaim-devops/priemtester
Is de toekomst van development brown field development?

Bart van der Wal, augustus 2025.
Versielog (28-10-2025): terminologie gecorrigeerd – "green field browser" hernoemd naar evergreen browser.
De software development wereld verandert snel. Waar we vroeger vooral nieuwe applicaties bouwden (green field development), werken ontwikkelaars tegenwoordig steeds vaker met bestaande codebases (brown field development). Deze trend wordt versterkt door de opkomst van AI-tools en de volwassenheid van de software industrie. In deze blogpost verkennen we waarom brown field development de toekomst is en wat dit betekent voor ontwikkelaars.
Green field vs Brown field development
Green field development betekent het ontwikkelen van een compleet nieuwe applicatie vanaf nul. Dit is wat startups doen in hun beginfase en wat je meestal leert in het onderwijs - "File → New Project". Het is spannend en creatief werk, maar in de praktijk doen ontwikkelaars in grote bedrijven dit maar zelden.
Brown field development daarentegen betekent het toevoegen van features aan een bestaande applicatie. Je werkt met legacy code, bestaande architecturen en moet begrijpen wat er al staat voordat je iets nieuws kunt toevoegen.
Waarom de verschuiving naar brown field?
1. Volwassenheid van de software industrie
De software industrie is volwassen geworden. De meeste bedrijven hebben al jarenlang software draaien en hun applicaties zijn complexe ecosystemen geworden. Nieuwe features worden toegevoegd aan bestaande systemen in plaats van nieuwe applicaties te bouwen.
"In veel grote bedrijven doen veel developers maar heel zelden 'File → New Project'..."
2. Microservices: een kleine tegenbeweging
De adoptie van microservices heeft wel een kleine tegenbeweging veroorzaakt. Hier start een software architect vaker een nieuw project, simpelweg omdat het totale systeem bestaat uit samenwerkende microservices, waar significant nieuwe features en toepassingen in een nieuwe microservice komen. Maar omdat deze wel in het landschap moet passen, en enige vorm van 'consolidated technology' wel handig is (standaard talen en tools gebruiken), start een nieuwe microservice vaak als een kopie van een bestaande service of een variant op een bestaand patroon.
3. Legacy systemen en LTS
Brown field development betekent vaak werken in oude codebases - soms nog in COBOL of Fortran, maar ook in oudere versies van .NET of Java. In het bedrijfsleven is werken met LTS (Long Term Support) versies de standaard, niet de nieuwste technologieën.
AI en de opkomst van "Code Monkeys"
Met AI-tools zoals GitHub Copilot en Cursor neemt AI een deel van het programmeerwerk over. De "code monkey" taken worden geautomatiseerd, en ontwikkelaars komen pas om de hoek kijken als er dingen niet werken. Dit is per definitie brown field development.
Vibe Coding: de nieuwe trend
De trend van "vibe coding" - waarbij niet-programmeurs kunnen programmeren met AI-tools - is door ervaren software engineer Dave Farley (auteur van 'Continuous Delivery' en 'Modern Software Engineering') al afgewezen als "the worst idea of 2025".
Het probleem is dat AI wel code kan genereren, maar de kwaliteit en robuustheid vaak te wensen overlaten. Je kunt wel prompten dat de AI "robuste code" moet schrijven of "unit tests met hoge coverage", maar de realiteit is dat AI net als mensen fouten maakt.
De wet van code lezen vs schrijven
Er is een vaste wet in software development: een ontwikkelaar leest meer code dan dat hij schrijft. Dit wordt alleen maar sterker met brown field development. Je moet bestaande code analyseren, begrijpen en debuggen voordat je nieuwe features kunt toevoegen.
Cognitive Load: het echte probleem
Het echte probleem met brown field development is cognitive load - hoe veel een ontwikkelaar moet denken om een taak te voltooien. Volgens zakirullin's cognitive load theorie is dit een fundamentele menselijke beperking:
"Cognitive load is how much a developer needs to think in order to complete a task."
Wanneer je code leest, houd je variabelen, control flow en call sequences in je hoofd. De gemiddelde persoon kan ongeveer vier van zulke "chunks" in het werkgeheugen houden. Zodra de cognitive load deze drempel bereikt, wordt het veel moeilijker om dingen te begrijpen.
Het probleem met AI gegenereerde code
AI tools kunnen code genereren, maar ze begrijpen vaak niet de cognitive load die ze creëren. Ze kunnen complexe patronen implementeren zonder te beseffen hoe moeilijk dit is voor andere ontwikkelaars om te begrijpen.
De toekomst: specialisten in cognitive complexity
In de toekomst zullen goed opgeleide ontwikkelaars steeds vaker worden ingevlogen om codebases te repareren en uitbreidbaar te maken. Ze zullen experts worden in:
- Cognitive complexity reductie - het verlagen van de mentale belasting van code
- Refactoring - het herstructureren van code zonder functionaliteit te veranderen
- Code review en kwaliteitscontrole - het controleren of AI gegenereerde code daadwerkelijk robuust is
Wat betekent dit voor jou als DevOps student?
In de minor DevOps van de HAN ga je vooral brown field development ervaring opdoen. Dit is bewust gekozen omdat:
Je leert werken met bestaande codebases
- Week 1: Je werkt met bestaande Java/C# projecten en voegt functionaliteit toe
- Week 2: Je containerized bestaande applicaties
- Week 3: Je implementeert CI/CD pipelines voor legacy systemen
- Week 4: Je orchestreert bestaande microservices
Waarom brown field in plaats van green field?
- Realistische werksituatie: 90% van je carrière werk je met bestaande code
- Cognitive load management: Je leert omgaan met complexiteit en legacy code
- Incrementele verbetering: Je leert systemen stap voor stap te verbeteren
- Team collaboration: Je leert samenwerken in bestaande codebases
De vaardigheden die je ontwikkelt
- Code reading: Begrijpen wat bestaande code doet
- Refactoring: Code verbeteren zonder functionaliteit te breken
- Integration: Nieuwe features toevoegen aan bestaande systemen
- Testing: Unit tests schrijven voor legacy code
- Documentation: Bestaande documentatie begrijpen en bijwerken
Maar ook: kansen voor green field development
Hoewel je in deze minor brown field ervaring opdoet, zijn er ook belangrijke kansen voor green field development in nieuwe, maatschappelijk relevante domeinen. Waar de knapste koppen voorheen bezig waren met advertentie-optimalisatie en sociale media algoritmes, liggen er nu kansen voor projecten die de mensheid op lange termijn helpen:
Maatschappelijk relevante domeinen voor HAN pijlers Slim Schoon, Sociaal:
Deze domeinen sluiten aan bij de drie zwaartepunten van de HAN: Slim (Smart Region), Schoon (Sustainable Energy & Environment) en Sociaal (Fair Health) (HAN University of Applied Sciences, z.d.). Hier liggen kansen voor projecten die de mensheid op lange termijn helpen:
- Milieu en duurzaamheid: Plastic soup opruimen, klimaatverandering aanpakken
- Duurzame energie: Zonne-energie optimalisatie, waterstof technologie
- AI Alignment: Het "alignment problem" oplossen zodat AI de hele mensheid helpt
- Gezondheidszorg: Preventieve geneeskunde, personalized medicine
- Onderwijs: AI-ondersteund leren, toegankelijk onderwijs
Deze domeinen hebben vaak nog geen bestaande ICT infrastructuur. Hier kun je de vaardigheden die je leert in brown field development (cognitive load management, code kwaliteit) toepassen op betekenisvolle nieuwe projecten.
Green field binnen geconsolideerde technologie stack
In het beroepsproduct van de minor DevOps ga je wel degelijk nieuwe projecten opstarten. Echter wel binnen een "consolidated technology stack" die de klant aangeeft. Typisch Java of C# met Angular of React front-end.
Dit sluit aan bij het Polyglot X concept uit web-scale architectuur, waarbij microservices verschillende talen en frameworks kunnen gebruiken, maar wel binnen een geconsolideerde technologie keuze (CorporatieMedia, 2016). De nieuwe services sluiten aan via dezelfde Service Bus of andere communicatie standaard/netwerk zoals RabbitMQ en draaien als Docker containers in Kubernetes.
Voordelen van deze aanpak:
- Flexibiliteit: Verschillende teams kunnen verschillende talen/frameworks gebruiken
- Consolidatie: Beperkte set van goedgekeurde technologieën
- Interoperabiliteit: Alle services communiceren via gestandaardiseerde interfaces
- Deployability: Uniforme containerization en orchestration
Qua taal en framework kun je variëren, maar de infrastructuur en communicatiepatronen blijven consistent. Dit is een praktische toepassing van brown field principes in een green field context.
Tools en technieken
Moderne ontwikkelaars moeten vertrouwd zijn met:
- Refactoring tools waar AI nog niet goed mee samenwerkt
- Code analysis tools die cognitive complexity meten
- Architecture patterns die cognitive load verminderen
Evergreen browser
Een gerelateerde term aan greenfield development is de evergreen browser. Dit is een browser die zichzelf automatisch up-to-date houdt via frequente, automatische updates. Dit geldt voor alle moderne versies van Chrome, Edge en Firefox die zonder gebruikersinterventie security‑patches en feature‑releases toepassen. Deze aanpak werd de feitelijke standaard sinds de lancering van Google Chrome (2008) en is sindsdien overgenomen door moderne browsers (NordVPN, 2025).
In een AI‑gedreven context helpt een evergreen‑strategie omdat apps en hun afhankelijkheden langer veilig en compatibel blijven, mits de kernfunctionaliteit framework‑onafhankelijk is (bijv. Hexagonal Architecture). Zo kunnen adapters wisselen terwijl de business‑logic stabiel blijft.
Belangrijke principes:
- Plain Old Java Objects (POJO) of Plain Old C# Objects (POCO): Domeinmodellen die onafhankelijk zijn van frameworks
- Hexagonal Architecture: De business logic is gescheiden van externe dependencies
- Dependency Inversion: De applicatie hangt niet af van concrete implementaties
- Framework Independence: De kern functionaliteit kan gemigreerd worden naar nieuwe frameworks
Dit betekent dat je applicatie "green field" kan blijven, zelfs als de onderliggende technologieën veranderen. De AI kan dan automatisch nieuwe adapters genereren voor nieuwe frameworks, terwijl de business logic intact blijft.
Waarom een human‑in‑the‑loop én human‑in‑the‑lead nodig blijft
LLM‑gedreven ontwikkeling gebruikt natuurlijke taal als interface. Natuurlijke taal is ambigu en ondergespecificeerd; het is geschikt voor intenties en context, maar niet voor precieze, formele specificaties. Software vereist exacte, ondubbelzinnige instructies. Daarom moeten:
- Specificaties en kritische beslissingen door mensen worden gemaakt en gevalideerd (human‑in‑the‑lead).
- Generatie en wijzigingen continu door mensen worden beoordeeld op implicaties, risico’s en consistentie (human‑in‑the‑loop).
Zoals Robert C. Martin stelt: “There will be code.” Uiteindelijk moet gedrag in code worden vastgelegd; prompts en natuurlijke taal kunnen dat niet volledig vervangen. Code (en tests) blijven de enige eenduidige, verifieerbare specificatie van het systeemgedrag.
Conclusie
Brown field development is niet alleen de toekomst - het is al de realiteit voor de meeste ontwikkelaars. De uitdaging ligt niet in het schrijven van nieuwe code, maar in het begrijpen, onderhouden en uitbreiden van bestaande systemen.
Met de opkomst van AI-tools wordt de rol van de ontwikkelaar verschoven van "code schrijver" naar "code analist en architect". De vaardigheid om cognitive load te verminderen en complexe systemen begrijpelijk te maken wordt steeds waardevoller.
Voor studenten betekent dit dat ze niet alleen moeten leren programmeren, maar ook moeten leren hoe ze bestaande code kunnen analyseren, begrijpen en verbeteren. Brown field development skills worden essentieel in de moderne software industrie.
Bronnen:
- CorporatieMedia (6 december 2016). Info Support publiceert roman over web-scale architectuur. Geraadpleegd op 28 augustus 2025 op https://corporatiegids.nl/nl/nieuws/info_support_publiceert_roman_over_web-scale_architectuur-2541
- Farley, D. (2025). The Worst Idea of 2025: Vibe Coding. Geraadpleegd op 28 augustus 2025 op https://www.youtube.com/watch?v=1A6uPztchXk
- Farley, D. (2021). Modern Software Engineering: Doing What Works to Build Better Software Faster. Addison-Wesley Professional.
- Humble, J., & Farley, D. (2010). Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation. Addison-Wesley Professional.
- HAN University of Applied Sciences (z.d.). Onze focus. Geraadpleegd op 28 augustus 2025 op https://www.han.nl/over-de-han/waar-staan-we-voor/onze-focus/
- NordVPN (2025). Evergreen browser. Geraadpleegd op 28 oktober 2025 op https://nordvpn.com/cybersecurity/glossary/evergreen-browser/
- Zakirullin (2025). Cognitive Load is what matters. Geraadpleegd op 28 augustus 2025 op https://github.com/zakirullin/cognitive-load
- Martin, R. C. (2008). Clean Code: A Handbook of Agile Software Craftsmanship. Prentice Hall.
Minor chartering
Door: Bart van der Wal, zomer 2021
Het toepassen van The Agile Inception Deck (AID) op de Minor DevOps zelf.
NB Een workshop van InfoSupport behandelt AID ook en in het project in blok 2 ga je dit ook gebruiken.
1. Describe why we are here
To do some major DevOps!
De DevOps beweging bestaat nu zo'n 10 jaar, en je ziet adoptie in groot deel van ICT bedrijfsleven, maar bij AIM (en voor zover mij bekend andere HBO ICT's) was er nog geen dedicated vak hierover, maar sijpelde het slechts hier en daar het onderwijs binnen via gebruik tools en om sneller aan de slag te kunnen.
2. Create an Elevator Pitch
"Let's do some major DevOps!" :)
In deze minor leer je moderne DevOps technieken en concepten om te kunnen innoveren en waarde toe te voegen in bedrijven. DevOps ligt in het verlengde van de Agile beweging, en geeft zeer veel tools, en best practices om als klein bedrijf een applicatie op schaal te draaien en om als groot bedrijf je complexe bedrijfsprocessen te modelleren, en te voorkomen dat tijd verloren gaat aan ICT complexiteit (accidental complexity) zodat je de gewonnen tijd kunt steken in het (via ICT) verbeteren van je bedrijfsvoering (inherente complexiteit).
3. Design a Product Box
Met het voltooien van een minor DevOps tijdens je studie ben je meer waard voor bedrijven en kun je sneller aan de slag in het ICT werkgebied. Interessante werkgevers hebben een hele categorie vacatures zals 'DevOps Engineer' en 'Site Reliability Engineer' (SRE), waarvoor je in aanmerking komt.
4. Create a NOT List
| In scope | Out of scope |
|---|---|
| Git | Cloud provider specific services/tools |
| Docker | Programming basics (voorkennis) |
| Kubernetes | Infrastructure as Code (Terraform e.d.) |
| Prometheus/Grafana | Service mesh (eigen onderzoek) |
| Linux | Basic computer skills (voorkennis) |
| DevOps principles | Business part/LEAN etc. |
| CNCF & DevSecOps basics | Ansible, Puppet, Chef, eBPF |
Extra: Ideeen Ops workshops 2022
- Package manager
- Running unit tests (writing Cucumber specs?)
- Managing DevOps
- CM: Ansible/CM
5. Meet Your Neighbors
Core team is jij, mede studenten, docenten AIM, docenten InfoSupport.
Buren/dependencies:
- aimsites.nl
- StackOverflow
- InfoSupport medewerkers
- Stackoverflow
- Academic license cloud services/trials
6. Show the Solution
Zie DevOps Tech.
7. Ask What Keeps Us Up at Night
- Is het te makkelijk?
- Is het te moeilijk?
- Operationele problemen
8. Size It Up
- 9 weken courses
- 9 weken project
9. Be Clear on What’s Going to Give
What's going to give? Nou in deze volgorde (tussen haakjes korte toelichting)
-
- scope (minimale diepgang per onderwerp)
-
- quality (6 niveau ligt vast)
-
- time (vast, 9 weken)
-
- money (n.v.t. behalve 'tijd is geld')
10. Show What It’s Going to Take
- Minimaal 20 studenten (max. 30)
- Een PluralSight account voor elke student
- Een voldoende krachtige laptop om lokaal
- VS Code, IntelliJ
- Nieuwsgierigheid, pragmatische insteek en een kritische blik
- Flexibiliteit en uren (40 uur per week, geen bijbanen)
- Goede en tijdige onderlinge communicatie
- Tijdige feedback en input
Controlekaart documenten AIM*
Een document dient aan al onderstaande criteria te voldoen.
Algemeen
- Lever het document op tijd in en op de juiste plek en manier.
-
Het document oogt netjes (geen verspringend lettertype,
geen inktvegen, geen rommelige vormgeving en geen onleesbare stukken tekst). - Voorzie het document van een titel, studentnaam of -namen (alfabetisch geordend), studentnummers, klas, groepsnummer, docentnaam of -namen, datum, course/semestergegevens en versienummer.
-
Voorzie het document van een inhoudsopgave
en paginanummers.
Opbouw
- Structureer je document door een goede indeling in hoofdstukken, en een hoofdstuk in paragrafen en alinea's. Het document bevat in ieder geval een inleiding, kerntekst en conclusie.
- Bijlagen, plaatjes en tabellen zijn een zinvolle aanvulling op de hoofdtekst.
- Gebruik APA-bronvermelding: een APA-literatuurlijst achteraan en in de tekst verwijzingen naar deze bronnen bij quotes of parafrases.
Stijl, spelling en grammatica
- Schrijf het document doel- en doelgroepsgericht en hou in de schrijfstijl rekening met de doelgroep.
- Spel vervoegingen van werkwoorden correct. Er staan maximaal drie foutief gespelde werkwoorden op een willekeurige pagina.
- Spel woorden correct. Er staan maximaal drie foutief gespelde woorden op een willekeurige pagina.
-
Het document is in de actieve vorm geschreven.Je schrijft het document in de actieve vorm. Het bevat nagenoeg geen lijdende zinnen.
*Noot: Bovenstaande tekst is overgenomen van de 'factlearning' Wordpress site van ICA AIM Professional skills (2016). Dat is niet de meest recente, maar op dit moment nog wel dé beste plek om via Google deze controlekaart te vinden :P.
Overzicht en toelichting aanpassingen
In deze 'markdown' versie zijn t.o.v. het origineel:
- de controlepunten ook voorzien van markdown checkboxen om af te vinken voor het inleveren/uploaden:
[ ]->[x] - De eisen in de actieve vorm geschreven, ook het punt over het vermijden van lijdende vorm, i.v.m. 'eat your own dogfood'
- irrelevante punten voor markdown/digitale documenten zoals 'paginanummers' en 'geen inktvegen' doorgestreept
Merk op dat de meeste punten in het digitale tijdperk gewoon nog gelden. Een automatische/interactieve inhoudsopgave/TOC kun in markdown kun je makkelijk genereren met tools bv. in Visual Studio Code)
Nu je ChatGPT kunt gebruiken om je te helpen/teksten te herschrijven moet je makkelijk foutloos kunnen schrijven i.p.v. drie fouten per pagina. Meer moeite heeft ChatGPT met in actieve vorm schrijven, of het herschrijven hiernaar.
Maar ook moderne bronnen zoals Google's Technical writing course (Google, 2022) onderstrepen dit punt alleen nog maar, o.a.:
- Passive voice obfuscates your ideas, turning sentences on their head. Passive voice reports action indirectly.
- Some passive voice sentences omit an actor altogether, which forces the reader to guess the actor's identity.
- Active voice is generally shorter than passive voice.
En IBM geeft voor requirements aan:
"Effective requirements clearly state who or what performs an action. Rewrite the requirement to clearly identify and focus on the actor."
Bart van der Wal - september 2023 (bijgewerkt januari 2026).
Bronnen
- AIM Professional Skills. juni 2016. Controlekaart documenten ICA. Geraadpleegd op 22-9-2023 op https://factlearning.files.wordpress.com/2016/02/controlekaart-documenten-ica.pdf
- Google (sept 2022) Google Technical Writing - Prefer active voice to passive voice Geraadpleegd 2 okt 2023 op https://developers.google.com/tech-writing/one/active-voice#prefer_active_voice_to_passive_voice
- IBM Engineering Requirements Quality Assistant (5-5-2023) Passive voice ibm.com, geraadpleegd 16-10-2025 op https://www.ibm.com/docs/en/erqa?topic=scores-passive-voice
Workshop Onderzoeksplan + Prompt Eng.
In deze workhop hebben we het over prompt engineering, en stel je een onderzoeksplan op.
Inleiding - Over onderzoek en Prompt engineering
Bij HAN ICT (AIM) vinden we het erg belangrijk dat je onderzoek doet. En een onderzoekende houding hebt. Dit is zelfs noodzakelijk, omdat de ICT sector zo in beweging is, dat je ook na je studie zult moeten blijven bijleren (Leven Lang Ontwikkelen). De opgedane kennis en vaardigheden uit je studie zijn wel een basis en een kapstop waar je nieuwe kennis aan kunt ophangen, en vaardigheden kunt verfijnen. Heel belangrijk hierbij is dat je de juiste vragen kunt stellen, juiste bronnen kunt vinden en de juiste methoden kunt gebruiken.
Wel richten we ons op toegepast onderzoek in plaats van theoretisch onderzoek. Dit laatste gebeurt meer op universiteiten of in Master opleidingen. Sommigen zien het zo dat daar dan het 'echte onderzoek' plaatsvind. Maar feitelijk is het heel nuttig om de uitkomsten van dergelijk theoretisch onderzoek, daadwerkelijk toe te passen, en zo te innoveren en waarde te creëren ('valorisatie').
Naast gestructureerd onderzoek doen, moet je het ook netjes opschrijven met geen of nauwelijks spel- of stijlfouten (max 3 per pagina). Hier kan ChatGPT je bij helpen. Als een AI qua schrijfniveau al snel een 7 of 8 scoort of zelfs hoger, dan kun je eigenlijk niet meer aankomen om dit zelf wel te doen (zie figuur 1). ChatGPT en andere generatieve AI lijken een belangrijke rol te hebben als productiviteitsbooster, maar hebben ook serieuze nadelen, dus dit vraagt een kritische houding.
We zien ChatGPT dus als 'creative technology', een AI met enorm veel kennis, waarschijnlijk meer dan enig mens ooit gehad heeft, en die altijd snel met een antwoord komt. Maar die af en toe ook 'confidently wrong' is, in de woorden van Elon Musk (2023):
"So when you're asking important, difficult questions, that's when it tends to be confidently wrong."
Ook bekende Nederlandse informaticus Edsger Dijkstra schreef lang geleden al over 'the foolishness of natural language programming':
"some still seem to equate "the ease of programming" with the ease of making undetected mistakes." - Edsger Dijkstra https://www.cs.utexas.edu/users/EWD/transcriptions/EWD06xx/EWD667.html (1979)
Prompt Engineering
"Eén prompt is geen prompt".
Via ChatGPT kun je vrij gemakkelijk vrijwel foutloze teksten laten genereren. Althans, foutloos in die zin, dat de output geen spellingsfouten of stijlfouten bevat. Inhoudelijk verzint ChatGPT af en toe gewoon wat, als het maar goed overkomt. Het klakkeloos overnemen van teksten van ChatGPT is natuurlijk niet wat we willen.
Verder heb je ook nog fouten qua formulering of doelgroep. Het 'hallucineren'kun je proberen wat te bepreken door ChatGPT hier in je gesprek een algemene prompt te geven:
Lieg niet! Als iets niet zeker is, zet dit er dan bij, of laat feiten geheel weg als ze erg onzeker zijn of niet kloppen.
Helaas geeft dit geen garanties, maar ChatGPT neemt dit wel mee.
Ook schrijf je een technische tekst voor een technische doelgroep. Het gebruik van heel veel bijvoeglijke naamwoorden of bijwoorden hierin is NIET gepast. Zie Technical writing; 'adjectives and adverbs' is de Engelse term voor bijvoegelijke naamwoorden respectievelijk bijwoorden. Een bijwoord is een soort bijvoeglijk naamwoord, maar dan voor een werkwoord i.p.v. een zelfstandig naamwoord, e.g. "Mooie zinnen (bijv. nw.) lees je vrolijk" (bijwoord))).
"...adjectives and adverbs can make technical documentation sound dangerously like marketing material." - Google Technical Writing (2023)
Zo schrijft ChatGPT standaard snel “jubelende” teksten over de tools en technologieën. ChatGPT heeft kennelijk nogal de neiging om overdrijvingen in de tekst op te nemen. Dit is meer marketing taal dan een technische en kritische tekst zoals gewenst. Voorbeelden:
- “deze essentiële tool ...”
- “dit is voor DevOps-ontwikkelaars absoluut onmisbaar”
- “tool X fungeert als cruciale pijler”
- “tool X is een uiterst waardevol instrument”
- en “van vitaal belang”.
Zulke zinsnede zijn niet acceptabel. Laat ChatGPT dit omschrijven. En als deze dat niet kan of wil, dan moet je het zelf doen. Kennelijk heeft ChatGPT een bias waardoor deze nogal positief uit de hoek komt. Deze toon is niet passend in een blog waarmee je objectiviteit uit wil stralen.
Alleen als je na je onderzoek tot de conclusie komt dat de tool inderdaad fantastisch, geweldig of onmisbaar is, dan kun je dat eventueel zo benoemen in je conclusie, maar als je inleiding al van (op dat moment nog ongefundeerd) enthousiasme aan elkaar hangt, kom je minder geloofwaardig over.

Figuur 1: 3HOOG: ChatGPT. Benieuwd hoe het afloopt?... Zie: sam.han.nl
Onderzoeksmethoden
Over de onderzoeksmethoden is een nog een workshop, maar de HBO ICT onderzoeksmethoden ben je als het goed is eerder in je studie al bekend mee geraakt. Tijdens de workshop kun je mooi nu tijdens je werk nog opkomende vragen stellen. Schrijf deze op, anders vergeet je ze. De onderzoeksmethoden geven suggesties en kwaliteitscriteria voor goed onderzoek, maar zijn geen simpele 1-2-3 of afvinklijst naar goede onderzoeksresultaten.
Ook kun je niet aan ChatGPT toevertrouwen om echt origineel werk te maken of foutloos te zijn. Deze verzint af en toe gewoon wat, dus je moet alles controleren (zie Figuur 2). Als je zelf nog geen expert bent - wat bij onderzoek per definitie zo is - dan zul je dit met andere bronnen dan ChatGPT moeten doen.
Figuur 2: Is ChatGPT veilig voor gebruik? - Aleksandr Tiulkanov on X - Onderzoeker AI & Digitaal beleid.
Als je eenmaal goede antwoorden hebt kun je ChatGPT wel inzetten om een passende inleiding met goede leeswijzer te schrijven. En ook een conclusie. In je conclusie mag je toch "geen nieuwe informatie presenteren" (zie evt. "Do's en Dont's in je conclusie op Scribr (2013)).
Ook is ChatGPT redelijk goed in het schrijven van een (management) samenvatting, als je deze het samen te vatten. Wellicht kan ChatGPT ook een aanzet tot een goede discussie geven. Of een hypothese formuleren. Het is echter wel zaak, alles te controleren. Ook of chat geen hoofdlijnen mist. Of juist heel wollig is gaan schrijven, terwijl dit niks toevoegt, hoogstens goede input verwaterd (zie figuur 3).

Figuur 3: ChatGPT: Lossy compression... of "Too Long, Didn't Write" (bron: marketoonist.com)
Stappenplan voor schrijven onderzoeksplan
Hieronder een heel aantal stappen onderverdeeld in 3 hoofdfasen A, B en C.
A. Setup ChatGPT en repo
- Maak — als je die nog niet had — een ChatGPT account aan voor je @student.han.nl account, of gebruik het anoniem, als dat werkt: https://chat.openai.com/
- Maak een repo aan op GitHub waar je je onderzoek (incl. onderzoeksplan) in gaat vastleggen/opslaan/documenteren. Zet in de repository naam je eigen naam, en zorg dat deze private is. Of gebruik een GitHub classroom link van een template repository als je docent deze aanlevert.
- Geef je teamgenoten ook toegang tot deze repository i.v.m. tussentijdse feedback volgens de 'Feedback circle' (PACT: zie opdrachtbeschrijving onderzoek).
B. Prompt engineering onderzoeksvragen voor onderzoeksplan
- Formuleer wie je doelgroep is (zie opdrachtbeschrijving) en neem dit mee in je prompts aan ChatGPT
- Stel, met behulp van Prompt engineering, hoofdvraag en deelvragen op over je DevOps technologie en het bijbehorende (DevOps) concept.
- Laat ChatGPT deelvragen beantwoorden, en vind relevante andere concepten en/of andere tools en pas eventueel je vragen aan (vooronderzoek/orientatieonderzoek).
- Vind kandidaat onderzoeksmethoden voor elk van de deelvragen (minstens 3, maar liever meer en scherpe deelvragen dan bij het minimum blijven)
- Laat ChatGPT elk van je deelvragen kort beantwoorden (geef deze prompt met max. aantal woorden)
- Vind per deelvraag een of meerdere relevante bronnen (anders dan ChatGPT) voor eerste verificatie
C. Vastleggen, format checks
- Leg de doelgroep de (voorlopige) hoofdvraag en deelvragen en bijbehorende onderzoeksmethoden vast in een
onderzoeksplan.mdin je repository - Voeg hierin ook een korte (APA) bronnenlijst onderaan toe met kopje
## Bronnen(met iig als bronnen de Research methods, de AIM controlekaart, ChatGPT, en extra bron per deelvraag, dus minstens 7 bronnen) - Zorg hierbij ook dat dat de bron titel cursief zijn in markdown en dat er ook referentie uit de tekst is naar je bron, zoals
- Installeer/activeer ook markdown linter (in bv VS Code), en haal lint fouten uit je
onderzoeksplan.md, zoals missende witregels rondom kopjes of bullet lijsten
D. Oefenen met markdown en AIM controlekaart
- Zet alvast het logo van de CNCF tool/technologie als markdown afbeelding in je onderzoeksplan, of een ander relevant logo en laat deze rechts alignen (
<img src="plaatjes/plaatje.jpg" width="200>" align="right"; html is ook markdown) - Neem ook een ander plaatje op, die 'gewoon' links aligned en block, en geef deze ook een 'caption'
*Figuur 1*: <Beschrijving>en verwijs met dit figuurnr ernaar in je tekst (gebruik niet 'hierboven' of 'plaatje hieronder') - Check dat de URL's van opgenomen bronnen ook in je bronnenlijst staan (
geraadpleegd op jj-mm-jjjj via <url>), en NIET als links in je hoofdtekst - Zoek ook wat stemmige afbeeldingen om je tekst te ondersteunen. Sla wel meteen de bron URL op, en neem deze ook op bronnen correct volgens APA. Zoek ook met bv. de Google image search met optie voor 'Creative Common werk', zie screenshot (University of Edinburgh, z.d.).

Figuur 4: Gebruik vrije plaatjes uit Google image search of vergelijkbaar
- en dat deze URL's ook NIET onnodig lang zijn, doordat ze bv. nog
#tekstfragment offbclidof andere onnodige tracking codes bevat (je moet evt. link tekst zelf IN je tekst zetten als quote of parafrase, en niet in bronnenlijst verstoppen) - Kijk tot slot of ChatGPT erg in de lijdende vorm heeft geschreven, en of je dit kunt laten herschrijven in de actieve vorm zoals de AIM controle kaart vraagt.
- Lees de AIM controlekaart en vink af of je document voldoet aan alle verplichte items. Heeft je onderzoekplan bv. een inleiding, kerntekst en (korte) conclusie? Staan je zinnen in de actieve vorm (weet je überhaupt wat dit inhoudt :S?). Pas dit nog aan. Dit was een mooie oefening voor je onderzoeksverslag, waar je hetzelfde moet doen!
Meldt bevindingen en vragen n.a.v. deze workshop bij de docent. Zorg dat deze dringende vragen beantwoordt.

Figuur 5: De toekomst van AI? - Bron CommitStrip.com
Tot slot
Voorlopig kunnen we AI nog goed gebruiken. Maar wat de toekomst brengt is onbekend. Er zijn grote kansen, maar ook grote risico's. Simpel verbieden kan niet, want er is ook argument te maken dat het onethisch is AI niet te gebruiken, gezien de grote uitdaging waar onze maatschappij nog voorstaat. Maar we moeten wel zorgen dat AI ge-aligned blijft.
PS: Dit stuk is nog geheel zonder hulp van ChatGPT geschreven. Alsnog kan het fouten bevatten; zo ja meldt deze even.

Figuur 6: ChatGPT als 'bullshitter' - Geen tijdbespaarder, maar normverhoger?
Het plaatje van figuur 6 mag je zelf even goed bekijken en over nadenken. Voor beperken grootte van plaatje/screenshot zijn beschrijvingen onder de 4 boeken eruit geknipt, maar verder is het plaatje niet bewerkt. De 2e bron (en dus ook beschrijving erbij) kon ik niet vinden via google, en had Chat verzonnen. Dit gaf deze ook meteen toe... Hieronder nog twee relevante quotes.
"ChatGPT [...] sometimes generates nonsense but overall it provides reasonable and and quite useful answers to our questions. So it’s a smart system; amazingly smart. But it’s also “bullshit”..." (Wikipedia z.d.)
En om de wellicht wat 'popy-jopy' of grof klinkende term 'bullshit' uit deze quote nog wat toe te lichten, want dit is inmiddels ook een in de wetenschap/filosofie onderzocht em beschreven woord.
"'On Bullshit' is een essay van de Amerikaanse filosoof Harry Frankfurt dat in 1986 werd gepubliceerd. [..]. Frankfurt [...] concludeert dat de spreker die zich van bullshit bedient niet geïnteresseerd is in de waarheid, maar alleen een mooi beeld van zichzelf wil scheppen. Volgens Frankfurt is bullshit een grotere bedreiging voor de waarheid dan de leugen" (Feeny 2023)

Figuur 7: XKDC over 'AI methodology'
Bronnen
- Commitstrip.com (april 2016) Meanwhile in a parallel universe. Will humans take our jobs? Geraadpleegd september 2023 op https://www.commitstrip.com/en/2016/04/14/meanwhile-in-a-parallel-universe-3/
- Driessen, Y. (feb 2023). 3 Hoog achter: ChatGPT. Geraadpleegd september 2023 op https://sam.han.nl/achtergrond/strip/3hoog-chatgpt/
- Feeney, P. (1 feb 2023) ChatGPT, “Bullshit” and the State of Artificial Intelligence. Geraadpleegd september 2023 op https://nl.wikipedia.org/wiki/On_Bullshit
- Marketoonist (juni 2023) Impact of ChatGPT. Geraadpleegd september 2023 op https://marketoonist.com/2023/06/impact-of-chatgpt.html
- Scribbr - (15 dec 2022). Scharwächter, V. Zo schrijf je een perfecte conclusie voor je scriptie | Met voorbeeld - Geraadpleegd oktober 2023 op https://www.scribbr.nl/scriptie-structuur/conclusie-scriptie/
- Wikipedia (z.d.) On Bullshit. Geraadpleegd september 2023 op https://medium.com/@patrick_97213/chatgpt-bullshit-and-the-state-of-artificial-intelligence-1b0f9c64079e
- XKDC z.d. AI Methodology. Geraadpleegd september 2023 op https://xkcd.com/2451/
- Google, z.d. - Technical writing. Geraadpleegd 31-10-2023 https://developers.google.com/tech-writing/one/clear-sentences
- The University of Edinburgh (z.d.) How to Google search for Creative Commons licensed resources Geraadpleegd op 2-11-2023 op https://open.ed.ac.uk/how-to-guides-old/how-to-google-search-for-creative-commons-licensed-resources/
- Dijkstra, E. (1979) On the foolishness of "natural language programming". Geraadpleegd september 2023 op https://www.cs.utexas.edu/users/EWD/transcriptions/EWD06xx/EWD667.html
- Fridman, L. (Host). (10 november 2023). Elon Musk: War, AI, Aliens, Politics, Physics, Video Games, and Humanity (Nr. 400) [Podcast aflevering]. In Lex Fridman Podcast. Geraadpleegd januari 2026 op https://lexfridman.com/elon-musk-4-transcript/
Technisch schrijven
Doel: Studenten voorbereiden op hun stage en afstuderen. Het schrijven van een afstudeerverslag is nu iets wat ze pas tijdens het afstuderen voor het eerst doen. We moeten ook wat meer standaarden dan enkel de AIM controlekaart geven.
Deze pagina bevat richtlijnen en tips voor technisch schrijven, specifiek gericht op ICT studenten. Deze richtlijnen zijn direct toepasbaar tijdens projecten - bijvoorbeeld bij het schrijven van een Software Guidebook tijdens een project - en helpen je voor te bereiden op je stage en afstuderen. We behandelen hier highlights uit de Google Technical Writing course en andere relevante bronnen, toegespitst op onze ICT studenten.
Inhoudsopgave
- De parallelen tussen documenten schrijven en code schrijven
- Documentstructuur en nummering
- Actief schrijven (geen lijdende vorm)
- Diagrammen altijd voorzien van toelichting
- Highlights uit Google Technical Writing course
- Markdown gebruiken
- APA-bronvermelding
- Toepasselijkheid van 'Technisch schrijven' op Plan van Aanpak
De parallelen tussen documenten schrijven en code schrijven
Er zijn opvallende parallelen tussen het schrijven van documenten en het schrijven van code. Beide vereisen structuur, duidelijkheid en een systematische aanpak.
"First make it work; then make it right"
Kent Beck, bekend van Extreme Programming en Test-Driven Development, zei ooit:
"First make it work; then make it right; then make it fast."
Dit principe geldt niet alleen voor code, maar ook voor het schrijven van documenten. Schrijf eerst je tekst, zorg dat de inhoud klopt en de structuur logisch is. Daarna kun je de tekst mooier maken, herschrijven, en verfijnen. Goed schrijven is herschrijven.
Structuur en hiërarchie
Net zoals code structuur heeft (klassen, methoden, functies), hebben documenten ook structuur nodig:
- Hoofdstukken zijn als modules of klassen - grote logische eenheden
- Paragrafen zijn als methoden - kleinere functionele eenheden
- Alinea's zijn als statements - individuele gedachten
Linus Torvalds , degene die het besturingssysteem Linux heeft geschreven - — zei over code structuur:
"If you need more than three levels [...], you're screwed anyway" - Linus Torvalds, Linux kernel coding style
Dit geldt ook voor documenten: gebruik maximaal drie niveaus van koppen (hoofdstuk, paragraaf, subparagraaf). Dieper dan dat wordt het onoverzichtelijk.
Verantwoordelijkheden toewijzen
In code design kennen we principes zoals Single Responsibility Principle (SRP) en GRASP. Bij het schrijven in de actieve vorm wijs je ook verantwoordelijkheden toe aan actoren. Dit maakt teksten duidelijker en beter te begrijpen.
Zie ook de uitgebreide uitleg hierover in de opdrachtbeschrijving onderzoek.
Refactoring
Net zoals je code refactort om deze beter leesbaar en onderhoudbaar te maken, moet je ook teksten herschrijven. De eerste versie is vaak niet de beste versie. Herlees, herschrijf, en verbeter.
Documentstructuur en nummering
Inleiding is Hoofdstuk 1
"De inleiding of introductie is het eerste hoofdstuk van je scriptie." — Scribbr
Sommige documenten zijn wel anders dan een scriptie, maar qua inleiding en nummering moeten HAN documenten deze standaard wel volgen. Het gaat vooral om dat Inleiding een Hoofdstuk is, en Bijlagen en Inhoudsopgave bijvoorbeeld niet, dus die krijgen GEEN hoofdstuknummer en zijn ook meer een soort container waar je zaken in kunt stallen.
Hoofdstukken structureren
Hoofdstukken moeten leesbaar zijn, dus elk hoofdstuk structureer je door het op te delen in subsecties en eventueel subsubsecties met hun eigen semantische kopje, en nummering voor verwijzing.
Leeswijzer
Een eigen leeswijzertje voor het hoofdstuk die deze structuur beschrijft/aankondigt kun je het best schrijven richting het einde, want goed schrijven is herschrijven. Pas als je weet wat er in het hoofdstuk staat, kun je een goede leeswijzer schrijven die de structuur beschrijft.
Actief schrijven (geen lijdende vorm)
De AIM controlekaart geeft aan:
"Je schrijft het document in de actieve vorm. Het bevat nagenoeg geen lijdende zinnen."
Dit is niet alleen een stijlregel, maar heeft ook praktische voordelen:
- Actieve vorm geeft meer context - je weet wie wat doet
- Actieve vorm is korter - minder woorden nodig
- Actieve vorm is duidelijker - verantwoordelijkheden zijn expliciet
Google Technical Writing course benadrukt:
"Passive voice obfuscates your ideas, turning sentences on their head. Passive voice reports action indirectly. Some passive voice sentences omit an actor altogether, which forces the reader to guess the actor's identity. Active voice is generally shorter than passive voice."
Voor ICT studenten is dit extra belangrijk omdat het aansluit bij software design principes: wie is verantwoordelijk voor welke actie? Net zoals in code design waar we verantwoordelijkheden toewijzen aan klassen en methoden.
Tip: Zoek een keer op 'word' of 'worden' in je tekst. Als dit vaker dan 5 keer voorkomt, weet je zeker dat je moet gaan herschrijven en de tekst een stuk korter kan.
Zie voor uitgebreide uitleg en voorbeelden:
Diagrammen altijd voorzien van toelichting
TOELICHTEN = uitLICHTEN en TOEvoegen
Elk diagram, figuur of tabel moet altijd voorzien zijn van een toelichting. Dit betekent:
- Een figuurnummer - bijvoorbeeld "Figuur 1"
- Een beschrijvende caption - wat toont het diagram?
- Verwijzing in de tekst - verwijs naar het figuurnummer, niet naar "hierboven" of "hieronder"
- Context - leg uit wat het diagram betekent en waarom het relevant is
Diagrammen en code: een genuanceerde vergelijking
Er is een parallel tussen diagrammen zonder toelichting en code zonder commentaar. Echter, zoals Uncle Bob (Robert C. Martin) aangeeft in zijn verhandeling over de 'Comment' code smell: goede code zou eigenlijk geen commentaar nodig moeten hebben. Als je code commentaar nodig heeft om begrijpelijk te zijn, is dat vaak een teken dat de code zelf niet duidelijk genoeg is - de code moet worden herschreven zodat deze zichzelf documenteert.
Voor diagrammen geldt iets vergelijkbaars: een goed diagram is in principe zelfverklarend. Maar in tegenstelling tot code, waar je de structuur en naamgeving kunt verbeteren, heb je bij diagrammen beperkte mogelijkheden om alles expliciet te maken zonder tekstuele toelichting. Daarom is een caption en contextuele uitleg bij diagrammen altijd nodig - niet als excuus voor een slecht diagram, maar als aanvulling om de lezer te helpen het diagram te interpreteren en te begrijpen waarom het relevant is.
Voorbeeld van goede verwijzing:
"De architectuur van het systeem is weergegeven in Figuur 1. Het diagram toont de drie hoofdlagen: presentatie, business en data."
Niet: "Zoals je hierboven kunt zien..." of "Het plaatje hieronder toont..."
Illustraties effectiever maken
De Google Technical Writing course over Illustrations geeft waardevolle tips om diagrammen en afbeeldingen duidelijker te maken:
Pijlen en annotaties in screenshots
In screenshots kun je direct pijlen toevoegen om belangrijke elementen te markeren. Dit maakt het voor de lezer direct duidelijk waar ze naar moeten kijken.
Notes en annotaties in UML/C4 diagrammen
In UML diagrammen of C4 Container diagrammen kun je notes toevoegen om specifieke aspecten uit te lichten. Dit helpt om complexe relaties of belangrijke beslissingen te verduidelijken.
Kleurcodering voor brown field development
Bij brown field development - het werken met bestaande codebases - is kleurcodering een krachtig middel om onderscheid te maken tussen:
- Nieuwe componenten/microservices - bijvoorbeeld groen of blauw
- Bestaande componenten die worden aangepast - bijvoorbeeld geel of oranje
- Bestaande componenten zonder wijzigingen - bijvoorbeeld grijs
Dit is extra relevant in het nieuwe onderwijs, omdat we nu meer brown field gaan ontwikkelen in plaats van enkel greenfield.
Legenda altijd toevoegen
Zoals Simon Brown aangeeft bij het C4 model: maak altijd netjes een legenda die de kleurcodering en symbolen expliciet maakt. Een legenda voorkomt verwarring en maakt je diagram toegankelijk voor alle lezers.
Voorbeeld van kleurcodering in een C4 Container diagram:
In een C4 diagram kun je bijvoorbeeld:
- Nieuwe containers weergeven in groen
- Bestaande containers die worden aangepast in geel
- Bestaande containers zonder wijzigingen in grijs
- Een legenda toevoegen die deze kleuren verklaart
Dit maakt direct duidelijk wat nieuw is, wat wordt aangepast, en wat ongewijzigd blijft - essentieel bij brown field development.
Groter is niet altijd beter
Veel beginnende ICT'ers proberen volledig te zijn in hun diagram, en maken een heel groot diagram, die ze dan soms zelfs naar een bijlage verplaatsen omdat het niet 'in het verslag zelf past'. Het is dan echter zaak om tijd te besteden aan hoe je dit grote afbeelding op kan splitsen in meerdere kleinere.
Zoals de Google Technical Writing course over Illustrations aangeeft: "Figure 3. Complex block diagram overwhelm readers." Een te groot diagram overweldigt de lezer en maakt het moeilijk om de essentie te begrijpen.
De essentie in ICT is ook 'probleem decompositie', dus een groot probleem opdelen in deelproblemen. En ook nadenken over hoe je de deeloplossingen die je realiseert vervolgens weer met elkaar laat praten, en samen inderdaad het gehele probleem oplossen. Vandaar ook zowel unit tests als integratie tests (en dus de testpiramide; maar dat terzijde).
Een groot diagram opsplitsen heeft verschillende voordelen:
- Leesbaarheid - kleinere diagrammen zijn makkelijker te begrijpen
- Focus - elk diagram kan zich richten op een specifiek aspect
- Onderhoudbaarheid - kleinere diagrammen zijn makkelijker bij te werken
- Herbruikbaarheid - deel diagrammen kunnen worden hergebruikt in andere contexten
Denk bijvoorbeeld aan het C4 model: in plaats van één groot diagram met alles, maak je een Context diagram, meerdere Container diagrammen, en Component diagrammen. Elk diagram heeft zijn eigen niveau van detail en doelgroep.
Diagrammen hoeven niet volledig te zijn
Algemene richtlijn/kwaliteitscriterium: Je diagrammen hoeven NIET volledig te zijn, maar moeten goede voorbeelden geven van de meest complexe stukken. De standaard zaken beschrijf je enkel kort in de bijbehorende toelichting.
Voorbeeld: C4 Container diagram met kleurcodering
Bij brown field development kun je een C4 Container diagram maken waarbij:
- Nieuwe containers in groen worden weergegeven
- Bestaande containers die worden aangepast in geel
- Bestaande containers zonder wijzigingen in grijs
Met een duidelijke legenda die deze kleuren verklaart.
Voorbeeld: UML Sequence diagram opsplitsen
Een veelvoorkomend probleem is een UML Sequence diagram dat te groot wordt omdat het zowel externe systeem aanroepen bevat als veel interne details. De oplossing is een combinatie van:
- System Sequence diagram - die de interne werking versimpeld weergeeft, volgens Einsteins quote: "Make everything as simple as possible, but not simpler"
- Apart sequence diagram - voor bijvoorbeeld enkele objecten uit een gegeven (UML) Class diagram, waar de interactie complexer is en methodes en interfaces uitgedacht moesten worden
Dit sequence diagram vult dan als dynamisch diagram het gegeven klasse diagram (wat een statisch diagram is) aan.
Wat NIET in diagrammen hoeft:
Interne details als getters en setters, of standaard aanroepen van een Controller → Service → Repository maak je geen diagram voor. Maar juist een diagram van een complex voorbeeld, bijvoorbeeld:
- Een
Controllerdie meerdereServices gebruikt - Een
Servicedie meerdereRepositorys spant in een niet-CRUD applicatie en zorgt voor transactionele integriteit
Toelichting beschrijft ook wat NIET in het diagram staat
In de toelichting (TOElichting) bij deze diagrammen moeten ook juist de zaken beschreven worden die NIET in het diagram staan. Je begint wel met wat wel in het diagram staat er UIT te lichten, maar voegt hier dan informatie aan toe.
Voorbeeld: ExpensePro applicatie
Voor een casus over een ExpensePro applicatie, voor het indienen van declaraties door medewerkers van een bedrijf tijdens zakelijke reizen door Europa:
De
ExpenseControllerroept deExpenseServiceaan, die gegeven input valideert, en voor het beoordelen van bepaalde declaraties deExpensePolicyServiceaanroept voor het beoordelen van declaraties op basis van de regels in het bedrijf en soms ook hierbij eerdere declaraties van de gebruiker in de beslissing betrekt via gebruik van deExpenseRepositoryen deExpensePolicyRepository. De repos worden alleen read acties gedaan, waardoor deExpensePolicyServicegeen transactionele integriteit hoeft af te dingen. Dit is anders voor de handmatige goedkeuring van declaraties door admin gebruikers. Daarbij kan een admin eenPolicyRuleaanpassen, wel zonder update omdat het hier gaat via een nieuweExpensePolicyVersionaanmaken met de door gebruiker ingegeven startdatum, zie klassediagram. Maar hierbij ook alle nog openstaande declaraties van afgelopen maand te herwaarderen (en dus te updaten). DeLoginController, enUserServiceenUserRepositoryhebben een standaard één-op-één verbinding, met relatief weinig logica in de Service. Maar we kiezen toch voor het handhaven van een Service voor toekomstige uitbreidbaarheid en handhaven van de standaard structuur uit de Layered Architecture (zie ADR04).
Belangrijk: Gebruik monospace font (via backticks '`' in Markdown) voor klassennamen en objectnamen, om voor de lezer duidelijk de relatie te leggen tussen documentatie en code.
Optioneel: Domain-Specific Language (DSL) via naamgeving in je domeinmodel
Waarom naamgeving voelt als een DSL
Natuurlijke taal is heel vrij vergeleken met een programmeertaal. Je kunt er van alles mee zeggen, ook dingen die niet kloppen met de werkelijkheid of zelfs intern inconsistent zijn. Deze vrijheid is krachtig in het echte leven, waar de werkelijkheid soms (nog) niet duidelijk is, en we te maken met vage menselijke zaken zoals 'meningen' ;). Maar in een applicatie zoek je juist duidelijkheid. Met zorgvuldige naamgeving van klassen, methodes en properties maak je een kleine taal waarin het níet mogelijk is om semantisch onzinnige combinaties te maken. Je API (de set publieke methodesignatures en type-/propertynamen) vormt zo een mini-DSL voor het domein.
Feitelijk bouw je met de API van je set klassen een taal. NB: met API bedoelen we hier niet per se een web- of REST-API, maar de Application Programmers Interface van een set OO-klassen (denk aan JDBC of Spring Boot MVC). Dit is de verzameling van methodesignatures en eventuele publieke properties (al zijn properties vaak privaat voor encapsulation).
Een paar vuistregels:
- Kies namen die de ubiquitous language van het domein volgen (Evans).
- Laat methodesignatures alleen combinaties toestaan die domein-logisch zijn.
- Vermijd generieke namen als
Manager/Util; want die verbergen domeinbegrippen. - Een "fluent" syntax kan, mits de zinsdelen domeinlogica afdwingen (Fowler).
Kernidee: de taal van je API moet het makkelijke pad maken voor correcte use-cases, en het moeilijke pad voor onzin of inconsistentie.
Verdieping / literatuur:
- Eric Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software, hoofdstukken over Ubiquitous Language en modellen.
- Martin Fowler, Domain-Specific Languages, delen over interne DSL's en fluente interfaces.
- Vaughn Vernon, Implementing Domain-Driven Design, secties over Bounded Contexts en taalafspraken.
Highlights uit Google Technical Writing course
De Google Technical Writing course bevat veel waardevolle richtlijnen voor technisch schrijven. Hieronder enkele highlights specifiek relevant voor ICT studenten:
1. Voorkom bijvoeglijke naamwoorden en bijwoorden
"...adjectives and adverbs can make technical documentation sound dangerously like marketing material." - Google Technical Writing (2023)
Schrijf je een technische tekst voor een technische doelgroep, dan is het gebruik van heel veel bijvoeglijke naamwoorden of bijwoorden NIET gepast. ChatGPT heeft bijvoorbeeld de neiging om "jubelende" teksten te schrijven:
- ❌ "deze essentiële tool ..."
- ❌ "dit is voor DevOps-ontwikkelaars absoluut onmisbaar"
- ❌ "tool X fungeert als cruciale pijler"
- ❌ "tool X is een uiterst waardevol instrument"
Dit is marketing taal, niet technische documentatie. Wees objectief en feitelijk.
2. Duidelijke zinnen
- Korte zinnen - één idee per zin
- Eenvoudige woorden - gebruik geen moeilijke woorden als eenvoudige woorden volstaan
- Concrete taal - vermijd abstracte termen waar mogelijk
3. Actieve vorm (zie boven)
Zie de sectie Actief schrijven hierboven.
4. Doelgroepgericht schrijven
Schrijf voor je doelgroep. Voor ICT studenten betekent dit vaak:
- Je klasgenoten (peers)
- Buitenstaanders met hetzelfde kennisniveau (ICT'ers)
- Soms: niet-technische stakeholders
Pas je taalgebruik aan op je doelgroep, maar blijf technisch accuraat.
5. Structuur en organisatie
- Logische volgorde - presenteer informatie in een logische volgorde
- Duidelijke koppen - koppen moeten duidelijk maken wat er in de sectie staat
- Consistente terminologie - gebruik dezelfde termen voor hetzelfde concept
Bullet lijsten in technische teksten
Gebruik in technische teksten bullet lijsten. En waar handig sub bullet lijsten. Maar leidt ze altijd even in, met een zin.
Google: "when writing, seek opportunities to convert prose into lists." — Google Technical Writing - Lists and Tables
Je ziet dat PlantUML van bullets dus ook zomaar een (work break down) boom van kan maken.
"If a table cell holds more than two sentences, ask yourself whether that information belongs in some other format." — Google Technical Writing - Lists and Tables
Markdown gebruiken
Markdown is een veelgebruikte opmaaktaal voor technische documentatie. Praktische voordelen:
- Documentatie staat naast je broncode in dezelfde repo → versiebeheer en PR-review lopen samen.
- Bij een commit of feature branch pas je code én documentatie tegelijk aan.
- Prima voor developer-doelgroep; voor niet-devs kun je via Pandoc exporteren als PDF of Word.
- Previews en linting zijn makkelijk (mdBook, GitHub preview) zodat je ziet hoe het eruitziet vóór publicatie.
- In combinatie met diagrams-as-code (PlantUML, mermaid) versioneer je ook je diagrammen in Git, met diffs, PR-review en near-WYSIWYG previews op GitHub/GitLab.
Niet ideaal voor rijke lay-out of DTP-achtige eindopmaak; gebruik dan liever Word/Google Docs/LaTeX. De Google Technical Writing course heeft ook een sectie over Markdown die de moeite waard is om te lezen.
Belangrijke Markdown conventies voor technisch schrijven
- Monospace font voor code - gebruik backticks (
`) voor klassennamen, methodenamen, variabelen, etc. Dit maakt duidelijk wat code is en wat gewone tekst - Koppen - gebruik koppen voor structuur (niet te diep, maximaal 3 niveaus)
- Lijsten - gebruik lijsten voor opsommingen
- Links - gebruik Markdown links in plaats van lange URL's in de tekst
Voorbeeld van monospace gebruik:
De
ExpenseControllergebruikt deExpenseServiceom declaraties te valideren. DeExpenseServiceroept vervolgens deExpensePolicyServiceaan voor het beoordelen van declaraties.
Dit maakt duidelijk welke delen code zijn en welke gewone tekst.
APA-bronvermelding
Doel van bronvermelding bij ICT
Hoewel je bij het lezen van algemene documenten vaak leest dat bronreferenties het doel hebben om plagiaat te voorkomen, is het bij ICT ook vooral de bedoeling om met referenties aan te tonen dat je daadwerkelijk zelf hebt verdiept in externe bronnen. Je toont aan dat je dergelijke vaak algemenere theorie ook juist kan toepassen en koppelen op de opdracht waar jij zelf mee bezig bent. Zodat je daadwerkelijk 'applied science', dus toegepaste wetenschap aan het doen bent.
Basisregels voor APA-bronvermelding
Vergeet verder niet om bij APA zowel voor elke gebruikte bron:
- de bron goed op te nemen in de Bronnen lijst, met juiste vorm afhankelijk of het een webbron is of niet
- en ook een referentie naar deze bron in je tekst op te nemen met een quote of parafrase.
De referentie tussen haakjes:
De referentie, het stuk tussen haakjes met auteurs- of organisatienaam en een jaartal staat hierbij tussen haakjes. En dat betekent dat je de zin waarin deze staat ook moet kunnen lezen als je dit stuk tussen haakjes weglaat. De bron kan dus niet onderwerp of lijdend voorwerp in de zin zijn.
Goed (alternatieve manier):
Google (2022) benadrukt dat actieve vorm korter is dan passieve vorm.
Deze versie is ook correct omdat je het jaartal tussen haakjes kunt weglaten en nog steeds een logische zin hebt: "Google benadrukt dat actieve vorm korter is dan passieve vorm."
Fout (bron wordt onderwerp):
(Google, 2022) benadrukt dat de actieve vorm korter is dan passieve vorm.
Hier wordt "Google" het onderwerp van de zin, wat niet mag volgens APA-regels.
Citeren vs parafraseren in het AI-tijdperk
In het huidige 'AI assisted' tijdperk is het verder wel handig om te neigen naar eerder letterlijk quoten van het materiaal. Want parafraseren zijn LLM's veel te goed in. En hierbij is het ook veel minder makkelijk om te checken of je daadwerkelijk goed aansluit bij een gelezen bron. Of dat je in je argumentatie wat stappen overslaat, of drogredenen opvoert.
Als er nog redeneerstappen zitten tussen de quote uit de bron en je eigen idee of conclusie, dan moet je deze in je tekst ook duidelijk maken.
Tekst moet op zichzelf leesbaar zijn
Het is essentieel dat je de lezer niet dwingt om de referentie ook daadwerkelijk te lezen en erbij te zoeken. Je stuk moet op zichzelf leesbaar en begrijpelijk zijn. De referenties zijn alleen bedoeld voor de lezer om makkelijk te kunnen controleren of het wel klopt. En om verdere optionele informatie erbij te zoeken.
Geen lange URL's in de tekst
Het heeft dus ook geen zin om gewoon naar de voorpagina van een website te verwijzen, bijvoorbeeld naar de Spring Boot landingspagina. Dan kun je deze domeinnaam gewoon opnemen in je tekst zelf zonder APA. Maar als je een argumentatie wil ondersteunen, zoek dan een blog op Spring Boot website op of andere site, of andere meer deeplink op.
Zet verder geen lange URL's in je tekst, maar gebruik APA. Je document moet op zichzelf leesbaar zijn, er is al veel te veel afleiding in de huidige wereld.
Voorkeur voor bronnen met auteur en datum
Geef ook de voorkeur aan bronnen waar daadwerkelijk een auteursnaam of tenminste organisatienaam op staat. En een datum van schrijven. Zodat niet al je bronnen z.d. worden.
Maak verder duidelijke onderscheid tussen 'medium' en 'organisatie', want bijvoorbeeld 'medium.com', maar ook stackoverflow.com en YouTube.com zijn een medium en is niet de organisatienaam die verantwoordelijk is voor de inhoud. Bij APA moet je de organisatie noemen.
Voorkeur voor erkende auteurs
Geef verder weer de voorkeur aan schrijvers die ook in lesstof voorkomen of in het vakgebied hoog aangeschreven staan, zoals Martin Fowler, Bob Martin (Uncle Bob), Kent Beck, etc. als optie.
Toepasselijkheid van 'Technisch schrijven' op Plan van Aanpak
Aan het begin van een project moeten studenten ook een Plan van Aanpak (ook wel 'Projectplan' geheten) schrijven als groep. Dit is minder een technisch document, maar meer een zakelijk document. Toch gelden veel van dezelfde regels uit deze pagina ook voor een Plan van Aanpak.
Doelgroepgericht schrijven blijft belangrijk
Hoewel een Plan van Aanpak een zakelijker karakter heeft dan technische documentatie, blijft doelgroepgericht schrijven het belangrijkste. Je schrijft voor:
- De opdrachtgever (vaak niet-technisch)
- Projectbegeleiders (technisch, maar ook procesmatig geïnteresseerd)
- Teamgenoten (technisch)
Pas je taalgebruik aan: je hoeft de lezer minder lastig te vallen met technische details, maar moet wel duidelijk en specifiek zijn over wat je gaat doen.
Specifiek maken en vooronderzoek doen
In ICT Projectplannen is het zaak om het document al zo specifiek mogelijk te maken. Dit betekent:
- Doe het nodige vooronderzoek - onderzoek de technologieën, frameworks en tools die je gaat gebruiken voordat je het plan schrijft
- Geen algemene zaken beschrijven - vermijd vage beschrijvingen zoals "we gaan een moderne webapplicatie bouwen"
- Wees concreet - beschrijf specifieke technologieën, frameworks en aanpakken
Onderscheid maken tussen projectresultaten en randvoorwaarden
Maak duidelijk onderscheid tussen:
- Projectresultaten en kwaliteitscriteria - wat lever je op en hoe meet je of het goed is?
- Randvoorwaarden - wat zijn de beperkingen en eisen waar je mee moet werken?
- Uitgesloten zaken - wat valt expliciet buiten de scope?
Risico's met uitwijkstrategieën en tegenmaatregelen
Voor elk geïdentificeerd risico moet je beschrijven:
- Het risico - wat kan er misgaan?
- De impact - wat zijn de gevolgen als het risico optreedt?
- Tegenmaatregelen - wat ga je doen om het risico te voorkomen of te beperken?
- Uitwijkstrategie - wat ga je doen als het risico toch optreedt?
Dit maakt je plan realistisch en toont aan dat je hebt nagedacht over mogelijke problemen.
Verwijzing naar Roel Grit
Voor uitgebreide richtlijnen over het schrijven van projectplannen, zie het boek van Roel Grit over projectmanagement. Dit boek behandelt de structuur en inhoud van projectplannen in detail.
Bronnen
- AIM Professional Skills. juni 2016. Controlekaart documenten ICA. Geraadpleegd op 22-9-2023 op https://factlearning.files.wordpress.com/2016/02/controlekaart-documenten-ica.pdf
- Beck, K. (z.d.) First make it work; then make it right; then make it fast. Geciteerd in diverse bronnen over software development.
- Brown, S. (z.d.) C4 Model. Geraadpleegd op https://c4model.com/
- Evans, E. (2003). Domain-Driven Design: Tackling Complexity in the Heart of Software. Addison-Wesley. Ubiquitous Language en modellen.
- Fowler, M. (2010). Domain-Specific Languages. Addison-Wesley. Interne DSL's en fluente interfaces.
- Google (sept 2022) Google Technical Writing. Geraadpleegd oktober 2023 op https://developers.google.com/tech-writing/one
- Google (sept 2022) Google Technical Writing - Illustrations. Geraadpleegd op https://developers.google.com/tech-writing/two/illustrations
- Grit, R. (z.d.) Projectmanagement. Noordhoff Uitgevers. Over projectplannen en Plan van Aanpak.
- Martin, R. C. (z.d.) Clean Code: A Handbook of Agile Software Craftsmanship. Over de 'Comment' code smell.
- Vernon, V. (2013). Implementing Domain-Driven Design. Addison-Wesley. Bounded Contexts en taalafspraken.
- Scribbr (z.d.) De inleiding of introductie is het eerste hoofdstuk van je scriptie. Geraadpleegd op https://www.scribbr.nl/
- Torvalds, L. (z.d.) Linux kernel coding style. Geraadpleegd op https://www.kernel.org/doc/Documentation/process/coding-style.rst
Schrijven met AI
Belangrijkste principe: De schrijver heeft de eindredactie. Je kunt het schrijven van delen van de documentatie overlaten aan AI, maar je bent zelf verantwoordelijk voor het controleren, aanpassen en samenvoegen.
Deze pagina behandelt het gebruik van AI (zoals ChatGPT) bij het schrijven van technische documentatie. We hergebruiken hier relevante stukken uit de Workshop Prompt Engineering, maar richten ons specifiek op het schrijven van documentatie.
Inhoudsopgave
- De schrijver heeft eindredactie
- Kwaliteitscriteria blijven gelden
- Wanneer gebruik je AI, wanneer schrijf je zelf?
- Prompt engineering voor documentatie
- Veelvoorkomende problemen met AI-generatie
- Controleren en samenvoegen
De schrijver heeft eindredactie
Het belangrijkste principe bij het gebruik van AI voor schrijven is: jij bent de schrijver, jij hebt de eindredactie. Dit betekent:
- Je kunt AI gebruiken om delen van je documentatie te schrijven
- Je kunt AI gebruiken om teksten te herschrijven of te verbeteren
- Maar: jij bent verantwoordelijk voor de uiteindelijke kwaliteit
- Jij controleert of alles klopt
- Jij past aan waar nodig
- Jij voegt alles samen tot een coherent geheel
AI is een hulpmiddel, geen vervanging voor je eigen verantwoordelijkheid als schrijver.
Kwaliteitscriteria blijven gelden
Alle onderdelen en kwaliteitscriteria waar we het op de pagina Technisch schrijven over hebben, blijven gelden - ongeacht of je zelf schrijft of AI gebruikt. Dit betekent dat je moet controleren op:
- Actieve vorm - de tekst staat in de actieve vorm, niet lijdend
- Doelgroepgericht - de tekst is geschikt voor je doelgroep
- Structuur - de tekst heeft een goede structuur met duidelijke koppen
- Diagrammen - diagrammen hebben toelichting en zijn niet te groot
- Spelling en grammatica - geen fouten (maximaal 3 per pagina)
- APA-bronvermelding - correcte bronvermelding waar nodig (voor onderbouwing van uitspraken)
- Geen bijvoeglijke naamwoorden/bijwoorden - technische teksten moeten objectief zijn
Of je nu zelf schrijft of AI gebruikt: jij controleert of het aan alle criteria voldoet.
Wanneer gebruik je AI, wanneer schrijf je zelf?
Het is belangrijk om te leren wanneer het handig is om AI te gebruiken, en wanneer het beter is om zelf te schrijven. Dit hangt af van verschillende factoren:
Wanneer AI gebruiken
- Eerste opzet - AI kan helpen met een eerste opzet van een tekst
- Herschrijven - AI kan helpen om teksten te herschrijven naar actieve vorm
- Spelling en grammatica - AI is goed in het corrigeren van spellings- en grammaticafouten
- Samenvattingen - AI kan helpen bij het schrijven van samenvattingen
- Routineuze delen - voor standaard onderdelen zoals inleidingen of conclusies (maar controleer altijd!)
Wanneer zelf schrijven
- Specifieke technische inhoud - als je specifieke technische kennis moet overdragen die AI niet heeft
- Je eigen onderzoek - voor beschrijvingen van je eigen onderzoek of bevindingen
- Complexe relaties - wanneer je complexe relaties tussen concepten moet uitleggen
- Als controle teveel tijd kost - soms is het sneller om zelf te schrijven dan uitgebreid te controleren
De balans vinden
De komende jaren zullen nieuwe AI's en technische mogelijkheden blijven verschijnen. Het is belangrijk dat je als student zelf beeld krijgt van wat op dat moment het handigste is. Maar je zult ook ontdekken dat het op een gegeven moment handiger is sommige stukken zelf te schrijven.
Of in ieder geval een uitgebreide prompt te schrijven aan de AI om zaken aan te passen en bepaalde stukken in te voegen (waarbij het laatste weer als nadeel heeft dat je vervolgens ook moet controleren of de AI dit allemaal goed gedaan heeft; want daar kun je eigenlijk nooit echt van uitgaan).
Prompt engineering voor documentatie
"Eén prompt is geen prompt" - je moet vaak meerdere prompts gebruiken en itereren om goede resultaten te krijgen.
Basisprincipes voor prompts
- Geef context - vertel de AI wat je doelgroep is, wat het doel van de tekst is, en welke stijl je wilt
- Geef voorbeelden - laat zien wat je wel en niet wilt
- Wees specifiek - vraag niet om "een goede tekst", maar om "een technische tekst voor ICT studenten, in actieve vorm, zonder bijvoeglijke naamwoorden"
- Itereer - gebruik de output als input voor een nieuwe prompt om te verbeteren
Voorbeeld prompts
Slechte prompt:
Schrijf een inleiding over Kubernetes.
Betere prompt:
Schrijf een inleiding over Kubernetes voor ICT studenten die al bekend zijn met Docker. De tekst moet:
- In actieve vorm zijn geschreven
- Geen bijvoeglijke naamwoorden of bijwoorden bevatten
- Maximaal 150 woorden lang zijn
- Objectief en feitelijk zijn, geen marketing taal
Uitgebreide prompts voor aanpassingen
Soms is het handig om een uitgebreide prompt te schrijven aan de AI om zaken aan te passen en bepaalde stukken in te voegen. Dit heeft echter als nadeel dat je vervolgens ook moet controleren of de AI dit allemaal goed gedaan heeft - want daar kun je eigenlijk nooit echt van uitgaan.
Voorbeeld uitgebreide prompt:
Pas de volgende tekst aan:
- Herschrijf alle lijdende zinnen naar actieve vorm
- Verwijder alle bijvoeglijke naamwoorden zoals "essentieel", "cruciaal", "onmisbaar"
- Voeg na paragraaf 2 een nieuwe paragraaf in over [specifiek onderwerp]
- Verwijder de laatste zin van paragraaf 3
[hier volgt de tekst]
Na zo'n prompt moet je altijd controleren of de AI alles correct heeft uitgevoerd.
Veelvoorkomende problemen met AI-generatie
1. Hallucinaties
ChatGPT en andere AI's kunnen "hallucineren" - ze verzinnen feiten die niet kloppen, maar die wel goed overkomen. Dit kun je proberen te beperken door een algemene prompt te geven:
Lieg niet! Als iets niet zeker is, zet dit er dan bij, of laat feiten geheel weg als ze erg onzeker zijn of niet kloppen.
Maar dit geeft geen garanties - je moet altijd controleren.
2. Marketing taal
ChatGPT heeft de neiging om "jubelende" teksten te schrijven met veel bijvoeglijke naamwoorden en bijwoorden:
- ❌ "deze essentiële tool ..."
- ❌ "dit is voor DevOps-ontwikkelaars absoluut onmisbaar"
- ❌ "tool X fungeert als cruciale pijler"
- ❌ "tool X is een uiterst waardevol instrument"
- en "van vitaal belang".
Zulke zinsnede zijn niet acceptabel. Laat ChatGPT dit omschrijven. En als deze dat niet kan of wil, dan moet je het zelf doen. Kennelijk heeft ChatGPT een bias waardoor deze nogal positief uit de hoek komt. Deze toon is niet passend in een blog waarmee je objectiviteit uit wil stralen.
Alleen als je na je onderzoek tot de conclusie komt dat de tool inderdaad fantastisch, geweldig of onmisbaar is, dan kun je dat eventueel zo benoemen in je conclusie, maar als je inleiding al van (op dat moment nog ongefundeerd) enthousiasme aan elkaar hangt, kom je minder geloofwaardig over.
3. Lijdende vorm
ChatGPT schrijft vaak in de lijdende vorm. Je moet dit expliciet vragen om te herschrijven naar actieve vorm, en daarna controleren of het gelukt is.
4. Wollige teksten
AI kan soms heel wollig gaan schrijven, terwijl dit niks toevoegt - hoogstens goede input verwatert. Controleer of de tekst nog steeds duidelijk en relevant is.
5. Hoofdlijnen missen
AI kan soms belangrijke hoofdlijnen missen. Controleer of de tekst compleet is en alle belangrijke punten behandelt.
Controleren en samenvoegen
Controleren
Na het gebruik van AI moet je altijd controleren:
- Inhoudelijke correctheid - klopt wat er staat?
- Volledigheid - zijn alle belangrijke punten behandeld?
- Stijl - voldoet het aan de kwaliteitscriteria (actieve vorm, geen marketing taal, etc.)?
- Consistentie - past het bij de rest van je documentatie?
- Bronvermelding - zijn bronnen correct vermeld waar nodig?
Samenvoegen
Bij het samenvoegen van AI-gegenereerde teksten met je eigen teksten:
- Zorg voor consistentie - gebruik dezelfde terminologie en stijl
- Controleer overgangen - zorgen de overgangen tussen AI-tekst en eigen tekst logisch?
- Herlees het geheel - lees het complete document door om te zien of het als één geheel werkt
- Pas aan waar nodig - pas AI-teksten aan zodat ze naadloos aansluiten bij je eigen teksten
Iteratief proces
Schrijven met AI is een iteratief proces:
- Prompt - geef een goede prompt aan de AI
- Genereer - laat de AI tekst genereren
- Controleer - controleer de output
- Pas aan - pas aan waar nodig (zelf of met nieuwe prompt)
- Herhaal - herhaal tot je tevreden bent
Tot slot
AI kan een krachtig hulpmiddel zijn bij het schrijven van documentatie, maar het is geen vervanging voor je eigen verantwoordelijkheid als schrijver. Je moet altijd controleren, aanpassen en samenvoegen. De kwaliteitscriteria voor technisch schrijven blijven gelden, ongeacht of je AI gebruikt of niet.
Zoals Edsger Dijkstra al zei:
"some still seem to equate "the ease of programming" with the ease of making undetected mistakes." - Edsger Dijkstra (1979)
Dit geldt ook voor schrijven: gemakkelijker schrijven betekent niet automatisch beter schrijven. Je moet altijd kritisch blijven.
Bronnen
- Dijkstra, E. (1979) On the foolishness of "natural language programming". Geraadpleegd op https://www.cs.utexas.edu/users.EWD/transcriptions/EWD06xx/EWD667.html
- Google, z.d. - Technical writing. Geraadpleegd 31-10-2023 https://developers.google.com/tech-writing/one/clear-sentences
- Workshop Prompt Engineering - Uitgebreide workshop over prompt engineering en onderzoek